




HydraNets:高效推理的专用动态架构.pdf
50墨值下载
HydraNets: Specialized Dynamic Architectures for Efficient Inference
Ravi Teja Mullapudi
CMU
rmullapu@cs.cmu.edu
William R.Mark
Google Inc.
billmark@google.com
Noam Shazeer
Google Inc.
noam@google.com
Kayvon Fatahalian
Stanford University
kayvonf@cs.stanford.edu
Abstract
There is growing interest in improving the design of deep
network architectures to be both accurate and low cost.
This paper explores semantic specialization as a mecha-
nism for improving the computational efficiency (accuracy-
per-unit-cost) of inference in the context of image classifi-
cation. Specifically, we propose a network architecture tem-
plate called HydraNet, which enables state-of-the-art archi-
tectures for image classification to be transformed into dy-
namic architectures which exploit conditional execution for
efficient inference. HydraNets are wide networks contain-
ing distinct components specialized to compute features for
visually similar classes, but they retain efficiency by dynam-
ically selecting only a small number of components to eval-
uate for any one input image. This design is made possible
by a soft gating mechanism that encourages component spe-
cialization during training and accurately performs compo-
nent selection during inference. We evaluate the HydraNet
approach on both the CIFAR-100 and ImageNet classifica-
tion tasks. On CIFAR, applying the HydraNet template to
the ResNet and DenseNet family of models reduces infer-
ence cost by 2-4× while retaining the accuracy of the base-
line architectures. On ImageNet, applying the HydraNet
template improves accuracy up to 2.5% when compared to
an efficient baseline architecture with similar inference cost.
1. Introduction
Deep neural networks have emerged as state-of-the-art
models for various tasks in computer vision. However,
models that achieve top accuracy in competitions currently
incur high computation cost. Deploying these expensive
models for inference can consume a significant fraction of
data center capacity [
19] and is not practical on resource-
constrained mobile devices or for real-time perception in
the context of autonomous vehicles.
As a result, there is growing interest in improving the de-
sign of deep architectures to be both accurate and compu-
tationally efficient. In many cases, the solution has been to
create new architectures that achieve a better accuracy/cost
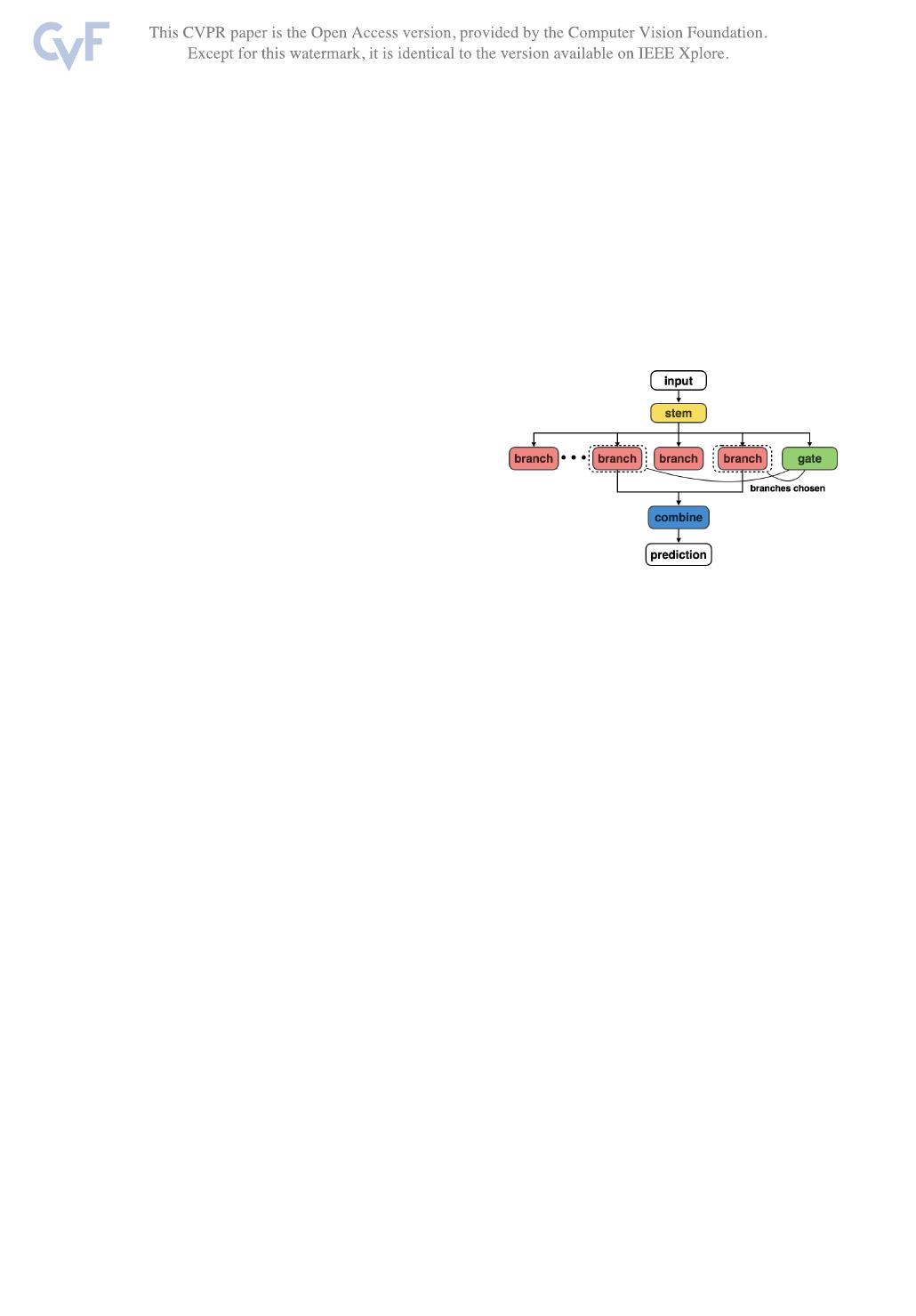
Figure 1: The HydraNet template architecture: contains
multiple branches specialized for different inputs and a gate
chooses which branches to run when performing inference
on an input, and a combiner that aggregates branch outputs
to make final predictions.
balance. Like most architectures, these new designs are
static architectures that evaluate the entire network for each
input, regardless of the input’s characteristics. In contrast,
dynamic architectures attempt to specialize the work per-
formed during inference to properties of a particular input.
For example, a cascade is a dynamic architecture that em-
ploys multiple models with different computational costs
and uses low cost models to “early out” on easy-to-process
inputs.
In this paper, we explore a dynamic architecture tem-
plate, which we call HydraNet, which achieves efficiency
gains by dynamically determining which subset of the ar-
chitecture to run to best perform inference on a given input.
In other words, a HydraNet maintains accuracy by having
large capacity that is semantically specialized to aspects of
the input domain. However, a HydraNet is computationally
efficient because it only uses a small fraction of this capac-
ity when performing inference on any one input.
Our primary contribution is the HydraNet architecture
template, shown in Figure
1, which is a recipe for trans-
forming state-of-the-art static network designs into dynamic
architectures that offer better accuracy-per-unit-cost. We
evaluate HydraNets in the context of image classification
where we specialize network components for visually simi-
lar classes. The gating mechanism in the HydraNet template
enables a simple training process which effectively special-
1
8080

izes the components to similar classes and enables condi-
tional execution for faster inference.
2. Related Work
Sparsity. The common approach to improving DNN effi-
ciency is to enforce sparsity in network connectivity [
21, 29,
4, 13]. This can be achieved via manual design of new DNN
modules (Inception [
27], SqueezeNet [16], MobileNet [13])
or via automated techniques that identify and remove the
least important connections from a dense network [
11, 10].
In either case, determination of the network topology is a
static preprocessing step, and all connections are evaluated
at the time of inference.
A complimentary optimization is to employ conditional
execution at the time of inference to exploit sparsity in ac-
tivations (skipping computation and memory accesses for
model weights when activations are known to be zero).
While attractive for reducing the energy consumption of
DNN accelerators [
9], fine-grained, per-element sparsity is
difficult to exploit on CPUs and GPUs, which rely heavily
on wide vector processing for performance. The subtask
specialization we exploit in HydraNets can be viewed as a
mechanism for designing and training a network architec-
ture that, through coarse-grained conditional execution, is
able to more effectively exploit dynamic sparsity.
Cascades. Cascades [
28] are a common form of condi-
tional model execution that reduces inference cost (on av-
erage) by quickly terminating model evaluation on inputs
that are easy to process (“early out”). Region proposal [
24]
based models for object detection are canonical example of
cascades in DNNs. Recent work has shown that integrat-
ing cascades into deep network architectures [
8, 14] can im-
prove the accuracy vs. cost of state-of-the-art architectures,
where the later stages in a cascade specialize for difficult
problem instances. The HydraNet approach of specializ-
ing network components for different subtasks is orthogonal
and complementary to the benefits of cascades.
Mixture of experts. The idea of specializing components
of a model for different subtasks is related to mixture-of-
experts models where the experts are specialized for dif-
ferent inputs or tasks. Recent work on training very large
DNNs for language modeling [
26] has used conditional ex-
ecution of experts for evaluating only a small fraction of ex-
perts for each training instance. One of the key aspects ad-
dressed in [
26] is the design of the mechanism for choosing
which experts to evaluate and trade-offs in network archi-
tecture to maintain computational efficiency. These design
choices are tailored for recurrent models and cannot be di-
rectly applied to state-of-the-art image classification models
which are feed-forward convolutional networks.
Hierarchical classification. Categories in ImageNet [
6,
25] are organized into a semantic hierarchy using an ex-
ternal knowledge base. The hierarchy can be used to first
predict the super class and only perform fine grained classi-
fication within the super class [
5, 7]. HDCNN [30] is a hier-
archical image classification architecture which is similar in
spirit to our approach. HDCNN and Ioannou et al. [20, 17]
improve accuracy with significant increase in cost relative
to the baseline architecture. In contrast, HydraNets on Ima-
geNet improve top-1 accuracy by 1.18-2.5% with the same
inference cost as corresponding baseline architectures.
Both HDCNN and Ioannou et al. model the routing
weights as continuous variables which are used to linearly
combine outputs from multiple experts. Jointly learning
the routing weights with the experts is similar to LEARN
in Table 8, and performs poorly due to optimization diffi-
culties (collapse and poor utilization of experts). HDCNN
uses complex multi-stage training to mitigate optimization
issues and provides robustness to routing error by overlap-
ping the classes handled by each expert. HydraNets use
binary weights for experts during both training and infer-
ence by dropping out all but the top-k experts. This enables
joint training of all the HydraNet components while allow-
ing flexible usage of experts.
Architectural structures similar to HydraNet [
1] have
been used for learning the partition of categories into dis-
joint subsets. Our main contribution is a gating mecha-
nism which reduces inference cost by dynamically choosing
components of the network to evaluate at runtime. Recent
work [
22, 23] has explored directly incorporating inference
cost in the optimization and explore training methods for
jointly learning the routing and the network features. In
contrast to the complex training regime required for joint
learning, our approach enables a simple and effective train-
ing strategy which we comprehensively evaluate cost on
both ImageNet and CIFAR-100 datasets.
3. HydraNet Architecture Template
The HydraNet template, shown in Figure
1, has four ma-
jor components.
• Branches which are specialized for computing features
on visually similar classes. We view computing fea-
tures relevant to a subset of the network inputs as a
subtask of the larger classification task.
• A stem that computes features used by all branches and
in deciding which subtasks to perform for an input.
• The gating mechanism which decides what branches
to execute at inference by using features from the stem.
• A combiner which aggregates features from multiple
branches to make final predictions.
Realizing the HydraNet template requires partitioning
the classes into visually similar groups that the branches
specialize for, an accurate and cost-effective gating mech-
anism for choosing branches to execute given an input, and
8081
of 11
50墨值下载
【版权声明】本文为墨天轮用户原创内容,转载时必须标注文档的来源(墨天轮),文档链接,文档作者等基本信息,否则作者和墨天轮有权追究责任。如果您发现墨天轮中有涉嫌抄袭或者侵权的内容,欢迎发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
下载排行榜

评论