




最大限度地减少对自由空间分割的监督.pdf
50墨值下载

Minimizing Supervision for Free-space Segmentation
Satoshi Tsutsui
∗, †
Indiana University
stsutsui@indiana.edu
Tommi Kerola
†
Shunta Saito
†
Preferred Networks, Inc.
{tommi,shunta}@preferred.jp
David J. Crandall
Indiana University
djcran@indiana.edu
Abstract
Identifying “free-space,” or safely driveable regions in
the scene ahead, is a fundamental task for autonomous nav-
igation. While this task can be addressed using semantic
segmentation, the manual labor involved in creating pixel-
wise annotations to train the segmentation model is very
costly. Although weakly supervised segmentation addresses
this issue, most methods are not designed for free-space. In
this paper, we observe that homogeneous texture and loca-
tion are two key characteristics of free-space, and develop
a novel, practical framework for free-space segmentation
with minimal human supervision. Our experiments show
that our framework performs better than other weakly su-
pervised methods while using less supervision. Our work
demonstrates the potential for performing free-space seg-
mentation without tedious and costly manual annotation,
which will be important for adapting autonomous driving
systems to different types of vehicles and environments.
1. Introduction
A critical perceptual problem in autonomous vehicle
navigation is deciding whether the path ahead is safe and
free of potential collisions. While some problems (like traf-
fic sign detection) may just require detecting and recogniz-
ing objects, avoiding collisions requires fine-grained, pixel-
level understanding of the scene in front of the vehicle, to
separate “free-space” [24] – road surfaces that are free of
obstacles, in the case of autonomous cars, for example –
from other scene content in view.
Free-space segmentation can be addressed by existing
fully-supervised semantic segmentation algorithms [33].
But a major challenge is the cost of obtaining pixel-wise
ground truth annotations to train these algorithms: human-
labeling of a single object in a single image can take approx-
imately 80 seconds [7], while annotating all road-related
∗
Part of this work was done as an intern at Preferred Networks, Inc.
†
The first three authors contributed equally. The order was de-
cided by using the paper ID as a random seed and then calling
np.random.permutation.
objects in a street scene may take over an hour [12]. The
high cost of collecting training data may be a substantial
barrier for developing autonomous driving systems for new
environments that have not yet received commercial at-
tention (e.g. in resource-poor countries, for off-road con-
texts, for autonomous water vehicles, etc.), and especially
for small companies and research groups with limited re-
sources.
In this paper, we develop a framework for free-space
segmentation that minimizes human supervision. Our ap-
proach is based on two straightforward observations. First,
free-space has a strong location prior: pixels correspond-
ing to free space are likely to be located at the bottom and
center of the image taken by a front-facing camera, since
in training data there is always free-space under the vehicle
(by definition). Second, a free-space region generally has
homogeneous texture since road surfaces are typically level
and smooth (e.g. concrete or asphalt in an urban street).
To take advantage of these observations, we first group
together pixels with low-level homogeneous texture into
superpixels. We then select candidate free-space super-
pixels through a simple clustering algorithm that incorpo-
rates both the spatial prior and appearance features (§3.3).
The remaining challenge is to create higher-level features
for each superpixel that semantically distinguish free-space.
We show that features from a CNN pre-trained on Ima-
geNet (§3.1) perform well for free-space when combined
with superpixel alignment, a novel method that aligns su-
perpixels with CNN feature maps (§3.2). Finally, these re-
sults are used as labels to train a supervised segmentation
method (§3.4) for performing segmentation on new images.
We note that our framework does not need any image an-
notations, so collecting annotated data is a simple matter of
recording vehicle-centric images while navigating the envi-
ronment where free-space segmentation is needed, and then
running our algorithm. The human effort required is re-
duced to specifying the location prior and adjusting hyper-
parameters such as superpixel granularity and the number
of clusters. This form of supervision requires little ef-
fort because the technique is not very sensitive to the ex-
act values of these parameters, as we empirically demon-
1
arXiv:1711.05998v3 [cs.CV] 8 Dec 2018
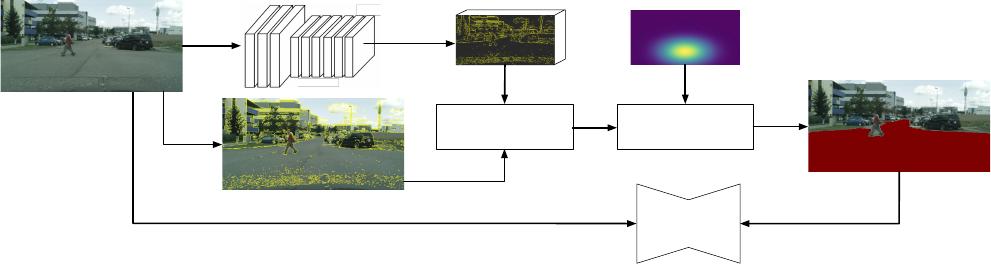
Superpixel align
Pre-trained dilated ResNet (fixed)Car-centric image
Superpixels
Feature map
Weighted k-means
Location prior
Estimated road mask
Use as labelsInput image
SegNet
Figure 1. Overview of our method. We extract features from a dilated ResNet pre-trained on ImageNet and leverage a novel superpixel
alignment method and location prior clustering to generate masks for training a segmentation CNN. Our method requires no manual
annotation of free-space labels. Best viewed in color.
strate with experiments on the well-established, publicly-
available Cityscapes dataset [12]. Our quantitative evalu-
ation shows that our framework yields better performance
than various baselines, even those that use more supervision
than we do (§4) .
In summary, we make the following contributions:
• We develop a novel framework for free-space segmen-
tation that does not require any image-level annota-
tions, by taking advantage of the unique characteristics
of free-space;
• We propose a novel algorithm for combining CNN fea-
ture maps and superpixels, and a clustering method
that incorporates prior knowledge about the location
of free-space; and
• We show that our approach performs better than other
baselines, even those that require more supervision.
2. Related Work
Fully supervised segmentation. Many recent advances
in semantic segmentation have been built on fully convo-
lutional networks (FCNs) [31], which extend CNNs de-
signed for image classification by posing semantic segmen-
tation as a dense pixel-wise classification problem. This
dense classification requires high resolution feature maps
for prediction, so FCNs add upsampling layers into the clas-
sification CNNs (which otherwise usually perform down-
sampling through pooling layers). SegNet [6] improves
upon this and introduces an unpooling layer for upsampling,
which reflects the pooling indices used in the downsampling
phase. We use SegNet here, although our technique is flex-
ible enough to be used with other FCNs as well.
A problem with CNN pooling layers is that they dis-
card spatial information that is critical for image segmen-
tation. One solution is to use dilated (or ‘atrous’) convolu-
tions [46], which allow receptive field expansion without
pooling layers. Dilated convolutions have been incorpo-
rated into recent frameworks such as DeepLab [9] and PSP-
Net [48]. Although our work does not focus on engineer-
ing CNN architectures, this direction inspired our choice of
CNN for image feature extraction, since we similarly want
to obtain a high resolution feature map. In particular, we use
dilated ResNet [47] trained on ImageNet, yielding a higher
resolution feature map than the normal ResNet [21].
Weakly supervised segmentation. Since ground-truth
segmentation annotations are very costly to obtain, many
techniques for segmentation have been proposed that re-
quire weaker annotations, such as image tags [13, 26, 34,
36,39,45], scribbles [29], bounding boxes [25], or videos of
objects [22,40]. At a high level of abstraction, our work can
be viewed as a tag-based weakly supervised method, in that
we assume all images have a “tag” of free-space. However,
most previous studies mainly focus on foreground objects,
so are not directly applicable for free-space, which can be
regarded as background [35]. From a technical perspec-
tive, some methods propose new CNN architectures [13] or
better loss functions [26], while others focus on automati-
cally generating segmentation masks for training available
CNNs [25]. We follow the latter approach here of gen-
erating segmentation masks for CNNs. We also do not
use the approach of gradually refining the segmentation
mask [39], because we believe that autonomous vehicles re-
quire a high-quality trained CNN even at the stage of initial
deployment.
Free-space segmentation. Free-space segmentation is
the task of estimating the space through which a vehi-
cle can drive safely without collision. This task is criti-
cal for autonomous driving and has traditionally been ad-
dressed by geometric modeling [3, 5, 27, 44], handcrafted
features [4, 18], or even a patch-based CNN [2]. We use
of 11
50墨值下载
【版权声明】本文为墨天轮用户原创内容,转载时必须标注文档的来源(墨天轮),文档链接,文档作者等基本信息,否则作者和墨天轮有权追究责任。如果您发现墨天轮中有涉嫌抄袭或者侵权的内容,欢迎发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
下载排行榜

评论