




数据库智能运维
免费下载

一次数据库问题智能分析实践
数据库智能运维
一开始想做数据库智能运维的时候其实并不知道最终会做成什么样子,包括现在也是,不
知道会实现多大价值。当时一方面相信人工智能的算法能力,一方面也清楚仅仅是在数据
库这个领域,大量的性能数据都非常有挖掘价值,但是没有利用上。同时联想到在平时的
数据库运维中遇到的痛点,智能运维应该会有很大帮助。所以还是下决心将工作开展起来。
当前数据库智能运维系统先实现了一个小目标:
Db2
数据库的问题实时检测和智能分析。
首先是将数据库级别的性能指标都监控起来。
Db2
数据库级别就有
400+
指标,我甚至都
不了解这些指标的具体含义。人为去定义指标的价值也不是正确的做法,所以不如全部监
管起来。每个系统的每个指标都基于机器学习在历史数据上计算出异常模型,然后对实时
指标数据检测打标识。这样就做好了数据库指标的异常检测功能。
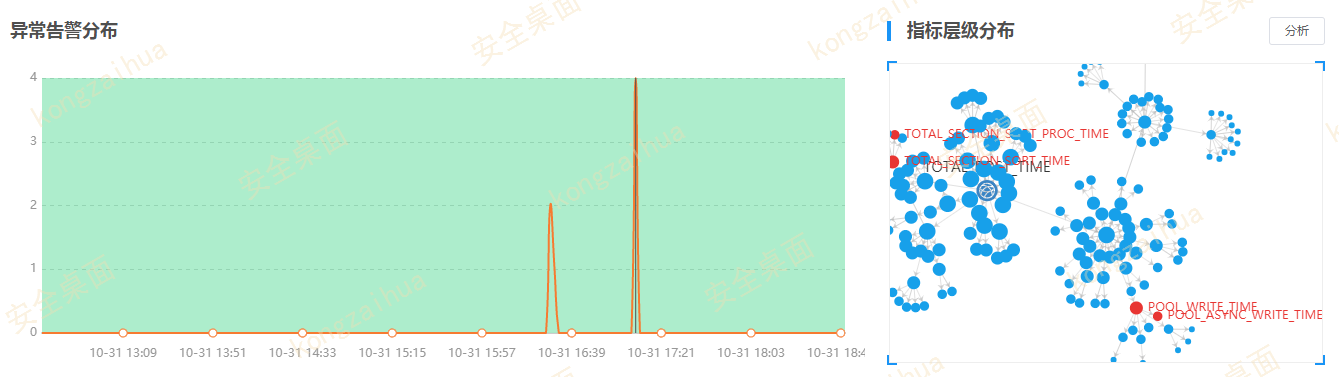
然后为了展现这些异常,我们基于人为的产品知识定义,结合历史数据的相关性分析,最
终形成了数据库指标的知识图谱。这样当很多异常指标发生的时候,我们能很快发现异常
点聚合在一起时什么功能什么原因。
在此基础上,为了方便普通用户能够看懂这个专业工具,我们还将一些指标集合定义成问
题场景。开发了一键智能分析功能,基于场景来解释当前系统的异常现象,并且下钻展示
影响的
SQL
是什么。
最后查到的问题
SQL
,我们进一步开发了
SQL
的性能详情页面,展示
SQL
的指标发展
趋势,执行时间分布等。这样能够很好的确定
SQL
是不是有问题,该从哪里着手来解决问
题。
一次核心系统的告警分析过程
2019
年
10
月
31
日,
17
:
08
:
54
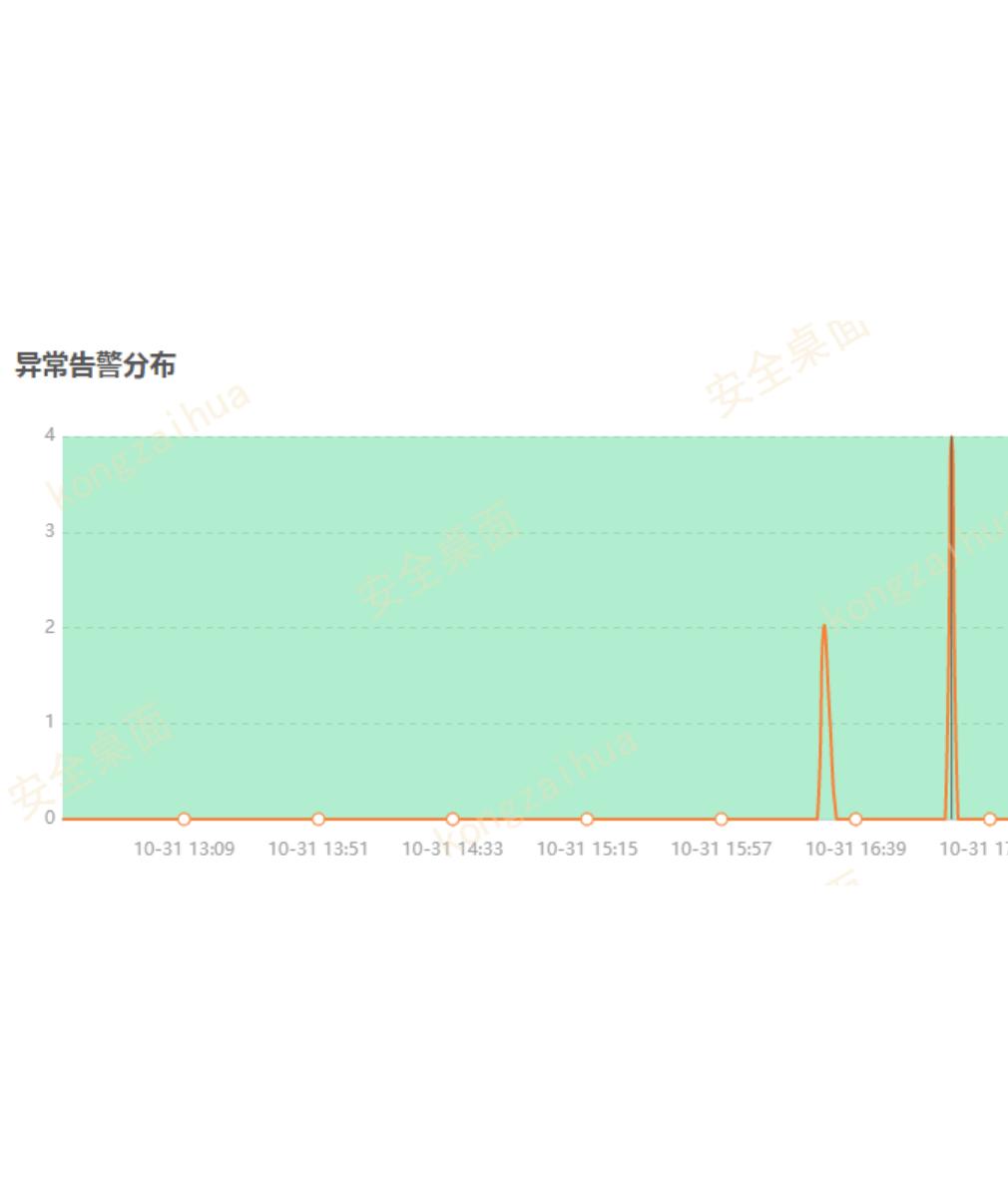
,核心系统数据库活动会话数高,达到
120
多个。
活动会话数是数据库堵塞的一个重要特征指标。如果分析不出来原因,很可能下一次就会
导致数据库全局堵塞,严重影响业务。尤其是核心系统出现这样的问题,需要格外重视。
如果是以前活动会话高并且很快消失,当时以及事后
DBA
其实都很难分析出原因是什么。
即便监控当时抓取到了正在执行的
SQL
,也没有足够的数据来着手分析。可能最好的办法
是问题发生的时候抓取
stack
甚至是
trace
,明显这也是不可能的,风险太大。
of 12
免费下载
【版权声明】本文为墨天轮用户原创内容,转载时必须标注文档的来源(墨天轮),文档链接,文档作者等基本信息,否则作者和墨天轮有权追究责任。如果您发现墨天轮中有涉嫌抄袭或者侵权的内容,欢迎发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
下载排行榜

{kind=link}
评论