

1



理解Oracle位图索引
5墨值下载
理解位图索引( 2 003-09 )
位图索引对于特定类型的应用是一个巨大的福音。但是,在这个领域中有许多关于位
图索引如何工作,何时使用它们以及它的副作用的错误信息。本文测试了位图索引的
结构,并尝试解释一些很常见的错误概念是如何产生的。
大家都知道的 …
如果你进行一个快速的关于人们对位图
索引认知的调查问卷,你可能发现以下
说法竟然被频繁引用:
a)
当在有位图索引的表上发生更新
时,会持有全表锁。
b)
位图索引适用于低基数列。
c)
即便要返回表的大部分,位图索
引也要比表扫描更有效。
第三种说法实际上是第二种说法的一个
推论(未经测试),而且,所有这三种
说法都处于错误和极易导致误信的灰色
地带。
当然,这些说法有一些接近真相的部分
—这足以解释它们为什么会出现在如此
重要的位置。
本文的目的是去测试位图索引的结构,
回顾上述说法,并尝试整理出一些使用
位图索引时的成本和收益。
什么是位图索引 ?
为了更有效的找到请求的行,索引被创
建了。位图索引也不例外—然而位图索
引背后的策略与 B*tree 索引背后的策略
是非常不同的。为说明这一点,我们可
以从检查几个转储块开始。
考虑图 1 中的 SQL 脚本:.
注意我们定义了 btree_col 和
bitmap_col
,
以便我们可以有相同的从
0 到 9 循环出现的数据
在一个块尺寸为 8K 的 9.2 数据库上,
得到的结果表占用了 882 个块。B*tree
索引有 57 个叶子块, 位图索引有 10 个
叶子块。
显然位图索引比 B*tree 索引在某种程度
上封装得更紧实。为了观察封装,我们
使用类似如下的命令生成符号转储:
alter system
dump datafile x block y;
结果如图 2 所示—小心,转储块的结果
可能导致一个小误解。部分显示的信息
是推导出来的,部分为了清晰起见而进
行了重新排列。
位图会锁表吗?
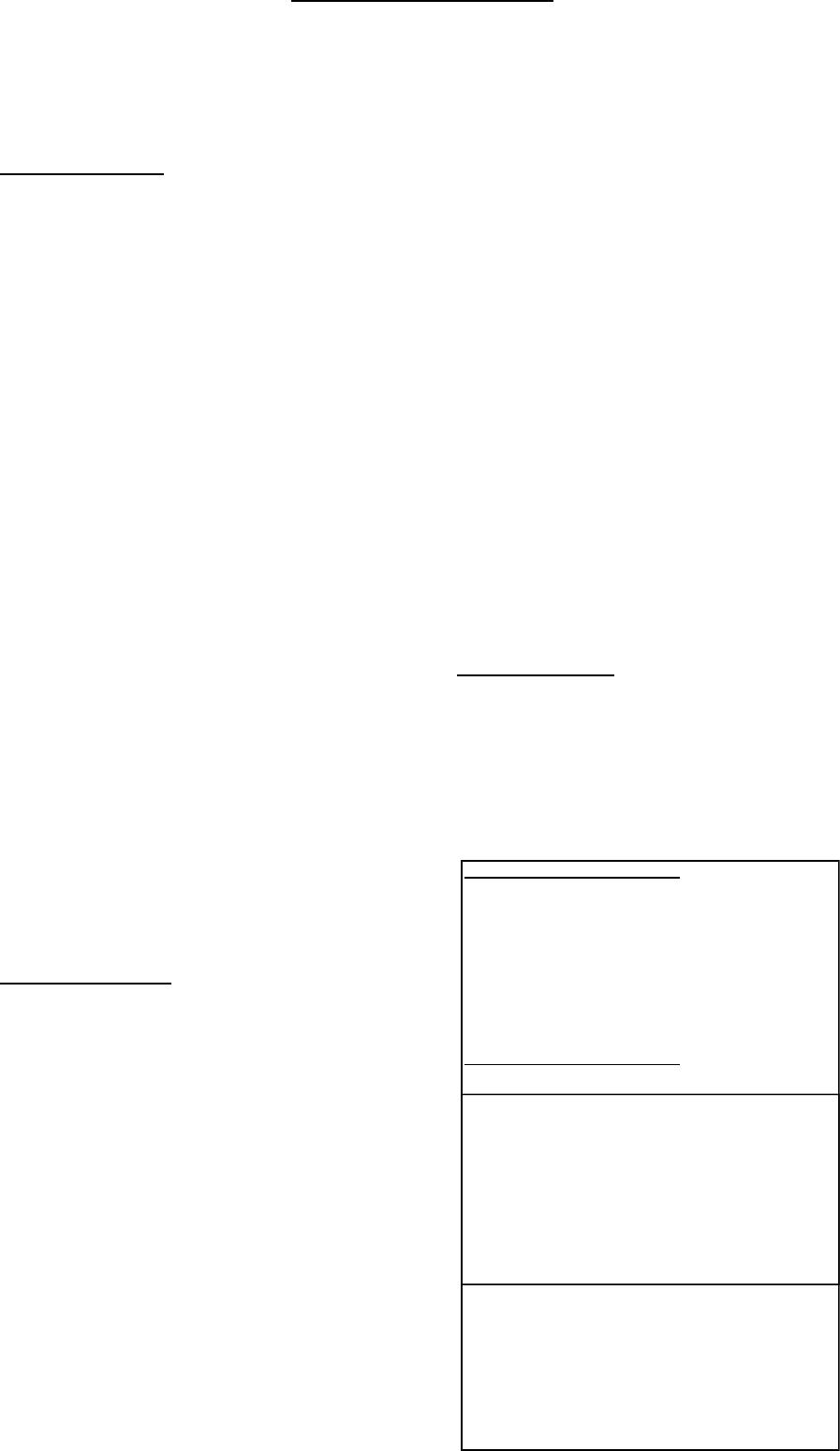
观察图 2,我们看到 B*tree 索引的每个
条目是由 flags, lock byte, 和两列数据
(本例中如此)构成的。这两列实际上
是索引值和 ROWID。表中的每一行在
索引中都有对应的一个条目。 (如果索
Extract from B*tree leaf
row#538[2016] flag: -----, lock: 0
col 0; len 2; (2): c1 02
col 1; len 6; (6): 00 40 c5 7d 00 09
row#539[2004] flag: -----, lock: 0
col 0; len 2; (2): c1 02
col 1; len 6; (6): 00 40 c5 7d 00 13
Extract from bitmap leaf
row#2[4495] flag: -----, lock: 0
col 0; len 2; (2): c1 03
col 1; len 6; (6): 00 40 c5 62 00 00
col 2; len 6; (6): 00 40 c7 38 00 1f
col 3; len 3521; (3521):
cb 02 08 20 80 fa 54 01
04 10 fb 53 20 80 00 02
fc 53 04 10 40 00 01 fa
53 02 08 20 fb 53 40 00 . . .
Figure 2: Symbolic block dumps.
create table t1
nologging
as
select
rownum id,
mod(rownum,10) btree_col,
mod(rownum,10) bitmap_col,
rpad('x',200) padding
from
all_objects
where rownum <= 30000
;
create index t1_btree on
t1(btree_col);
create bitmap index t1_bit on
t1(bitmap_col);
Figure 1 Sample data.
引是唯一索引,我们仍然会在每个索引
条目中看到同样的内容,但展现的方式
会有一些小不同)。
在位图索引中,每一个条目是由 flags,
lock byte, 和 4 列数据(本例中如此)
构成的. 这 4 列数据实际上是索引值,
一对 ROWID 和二进制位串。这一对
ROWID 标识表中的一段连续区域,而
被编码的二进制位串告诉我们在那些
ROWID 范围内,谁持有那个索引值。
观察二进制位串的大小—在上例中列的
长度是 3521 字节,或者大约 27000 个
二进制位。去除大约 12%的校验码等的
开销,单个条目大约可以覆盖表中
24000 行。但是,整个条目只有一个
lock byte, 这意味着单个锁会影响表上
的 24000 行。
因此,这就是可疑说法的来源——如果
你认为位图索引会导致一个完整的表锁,
那么是你经历的表太小了。
一个位图锁会覆盖数千行--这确实是个
坏消息—但是它不会锁表。
位图锁的后果
不过,我们不应该在这个结论上停止,
因为这很容易误解该结果。我们需要了
解哪些操作将导致持有一个关键锁字节,
以及精确地了解这将对数千个相关行产
生什么影响。
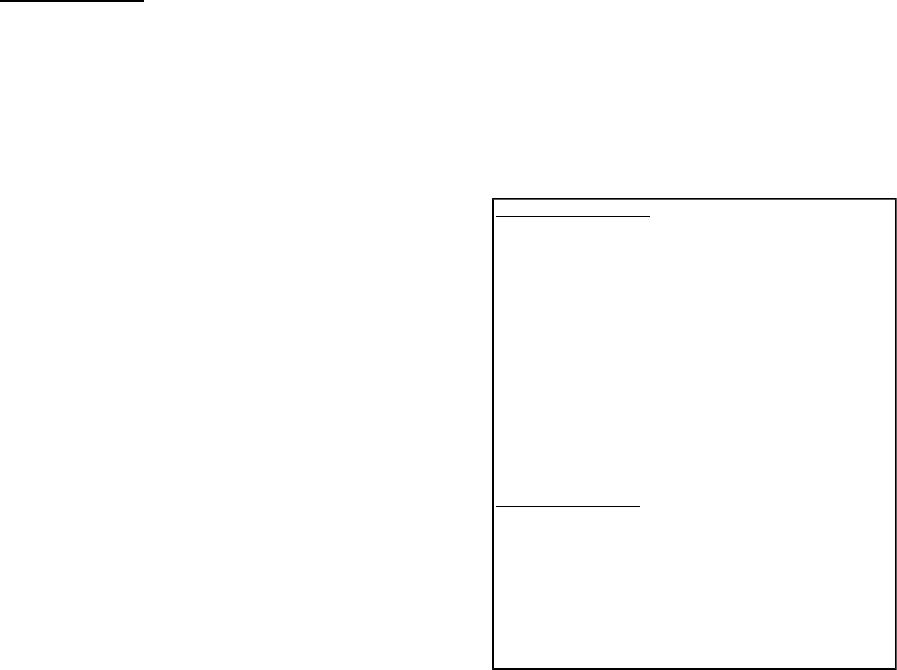
我们可以使用一个更小的测试来研究它
(如图 3 所示)。我们从创建一个小表
开始,然后我们在表的不同的行上做不
同的更新。
注意我们更新了表中一行的索引列。如
果我们转储索引和表块,我们会看到一
个 LOCK 字节被设定在表中的一行上,
但有两个部分的位图索引被锁定。这两
个部分是当前值 1(图中“from”部分)
邻近的行和值为 2(图中”to”部分)邻近
的行。(实际上我们会看到这两个部分
已经被拷贝并且拷贝也被锁定)
我们需要继续探讨的问题是在本例中,
Oracle 的锁定会有多激进.
答案对于那些认为“位图索引会导致表
锁”的人来说,可能有一点儿出乎意料。
我们可以做以下任何操作(每一个都是
单独的测试)
更新处于“From”部分的一行。假设我们
不尝试更新位图索引列。
update t1
set id = 5
where id = 0;
更新处于“TO”部分的一行。假设我们不
尝试更新位图索引列。
update t1
set id = 6
where bit_col = 2;
这些测试显示,被位图索引锁定覆盖的
行仍然是可以更新的。
当然,锁冲突是可能的,下面的例子均
没有更新锁定的表行,但是均会导致它
们的会话在模式 4(共享)的 TX 锁上
等待。
update t1
set bit_col = 4
where id = 2; -- bit_col = 2
update t1
Sample data set.
create table t1 (
id number,
bit_col number
);
insert into t1 values(0,1);
insert into t1 values(1,1);
insert into t1 values(2,2);
insert into t1 values(3,3);
insert into t1 values(4,4);
create bitmap index t1_bit on
t1(bit_col);
Update one row.
Update t1 set bit_col = 2 where id = 1;
(0,1) 'from' bitmap
(1,1) -> (1,2) locked row.
(2,2) 'to' bitmap
(3,3)
(4,4)
Figure 3: Preparing for update tests.
of 14
5墨值下载
【版权声明】本文为墨天轮用户原创内容,转载时必须标注文档的来源(墨天轮),文档链接,文档作者等基本信息,否则作者和墨天轮有权追究责任。如果您发现墨天轮中有涉嫌抄袭或者侵权的内容,欢迎发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
下载排行榜

评论