




读写分离下怎么保证主备节点的读一致性?
5墨值下载
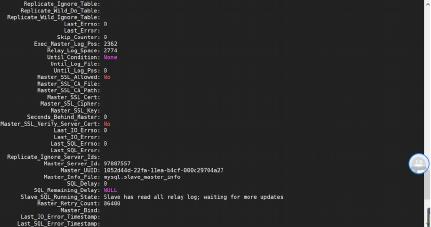
MySQL 读写分离场景,最重要的需要保证只读节点与主节点的读一致性。读写分离下一般是
怎么做的?我们先看下主从下怎么判断延时,以及怎么确保读写分离场景下读写一致性。
一、 MySQL replication 主备延时判断?
1.seconds_behind_master 值判断
我们知道 show slave status 结果里的 seconds_behind_master 参数的值,
可以用来衡量主备延迟时间的长短。
seconds_behind_master 是否为 0,如果是 0 主备无延时(但是感觉也不准)
2.对比位点确保主备无延迟:(异步复制)
Master_Log_File 和 Read_Master_Log_Pos,表示的是读到的主库的最新位点;
Relay_Master_Log_File 和 Exec_Master_Log_Pos,表示的是备库执行的最新位点。
如果 Master_Log_File 和 Relay_Master_Log_File、Read_Master_Log_Pos 和
Exec_Master_Log_Pos 、Exec_Master_Log_Pos
两组值相同,表示接收到的日志已同步。
3.对比 GTID 集合确保主备无延迟:
Retrieved_Gtid_Set,是备库收到的所有日志的 GTID 集合;
Executed_Gtid_Set,是备库所有已经执行完成的 GTID 集合。
如果这两个集合相同,也表示备库接收到的日志都已经同步完成。
相比来说对比位点的方式比看 seconds_behind_master 值的方式靠谱很多。
二、读写分离场景下怎么判断应用程序该连接到主库还是备库查询?
读写分离场景中,经常会遇到主备延时的坑,改怎么处理?(不推荐使用异步复制,推荐
都开启 GTID)(一般需要保证只读节点与主几点的读一致性)
目前大部分库都开启 GTID 模式,先了解一个查询
select wait_for_executed_gtid_set(gtid_set);
说明:
1.这个查询是在备库执行
2.gtid_set 代表主库执行完事务后返回的 gtid 集
3.返回值如果为 0,代表无延时,如果为 1 代表延时
场景:一个事务执行后,客户端需要发起查询,读写分离场景下,客户端需要判断,到底是
从哪查询?
我们的解决做法:
1.trx1 事务更新完成后,从返回包直接获取这个事务的 GTID,记为 gtid1;
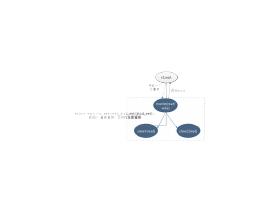
2.选定一个从库执行查询语句;
3.在从库上执行 select wait_for_executed_gtid_set(gtid1, 1);
如果返回值是 0,则在这个从库执行查询语句;
否则,到主库执行查询语句。
of 2
5墨值下载
【版权声明】本文为墨天轮用户原创内容,转载时必须标注文档的来源(墨天轮),文档链接,文档作者等基本信息,否则作者和墨天轮有权追究责任。如果您发现墨天轮中有涉嫌抄袭或者侵权的内容,欢迎发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
下载排行榜

评论