




吴仕橹-大数据的智能处理和数据可视化实践.pdf
免费下载

全球敏捷运维峰会 广州站
PUBLIC
Big Data Intelligent Processing & Data Visualization
演讲人:吴仕橹
全球敏捷运维峰会 广州站
PUBLIC
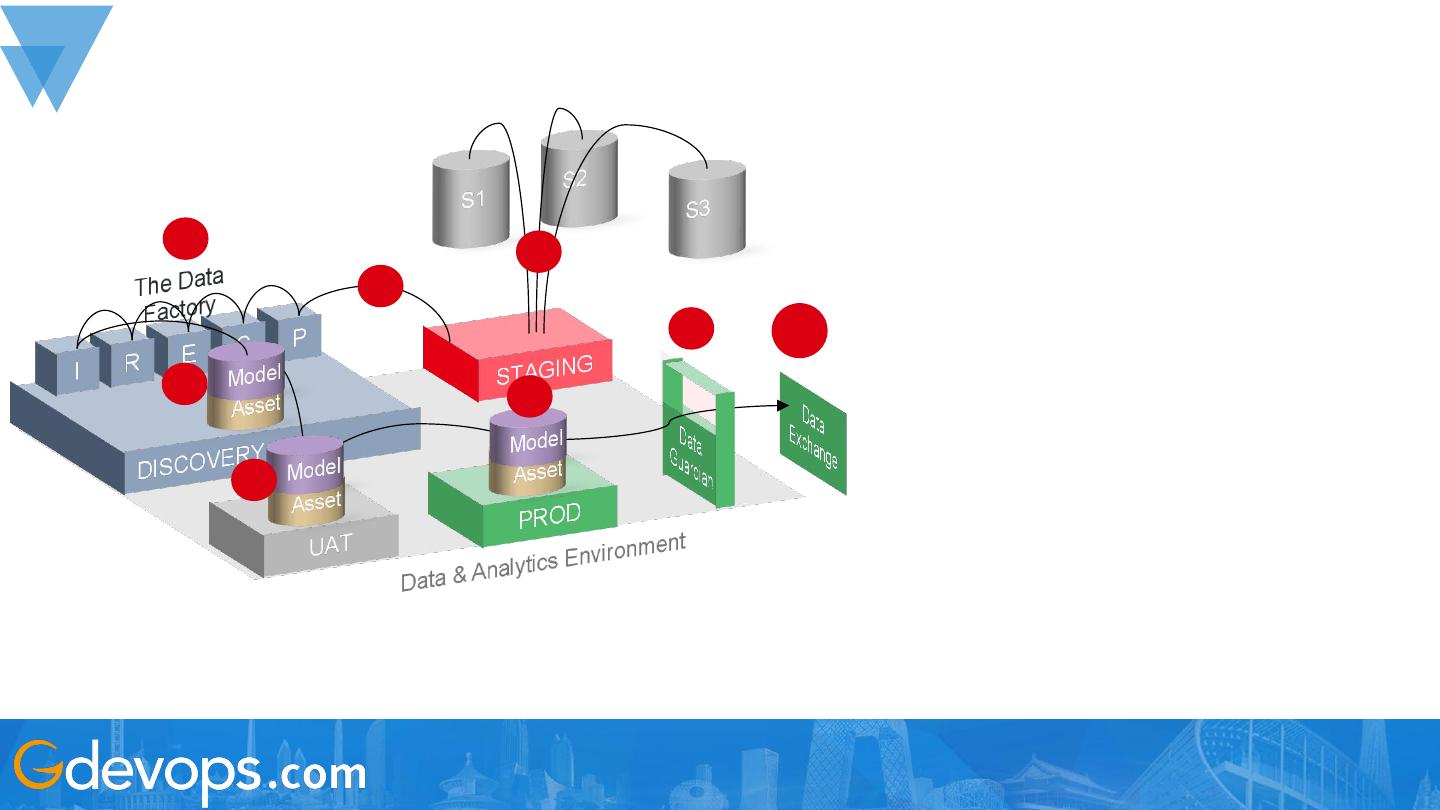
Business Insights & Analytics – How it Works
1
2
3
4
5
6
7
8
1) Source systems are ingested into staging (a shared preparation area).
Typically through Sqoop (database copy) or CDC (streaming style change
updates) or Juniper( in the house platform)
2) System tables are copied into the Discovery environment, where this
production data is processed and models/insight are developed post Data
Factory
3) The Data Factory takes raw data through a number of steps:
i. Profiling : looking at the data to identify its contents and tag it
with the correct metadata
ii. Cleansing & curating : restructuring the data into the simplest
and most efficient form, highlighting errors to revert back to
source system owners
iii. Enriching : creating new derived fields based on the raw data
(e.g. flags) and appending reference data for models to utilise
iv. Record linking : using advanced techniques to join up disparate
data and masses of separate sources into a single logical model
v. Indexing : organising the final data asset into an index, making it
quickly searchable
4) Stabilised assets and models are pushed through our UAT environment
for testing and data validation from the consuming users
5) Final models and assets are then landed in our production environment;
their insight ready for consumption through agreed patterns (typically APIs
or file transfers)
6) The Data Guardian will control all consumption compliance
7) Data Exchange hosts APIs/APPs to source data to consumers
of 10
免费下载
【版权声明】本文为墨天轮用户原创内容,转载时必须标注文档的来源(墨天轮),文档链接,文档作者等基本信息,否则作者和墨天轮有权追究责任。如果您发现墨天轮中有涉嫌抄袭或者侵权的内容,欢迎发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
下载排行榜

文档被以下合辑收录
评论