




UniKV_ Toward High-Performance and Scalable KV Storage in Mixed Workloads via Unified Indexing.pdf
免费下载
UniKV: Toward High-Performance and Scalable KV Storage
in Mixed Workloads via Unified Indexing
Qiang Zhang
1
, Yongkun Li
1
, Patrick P. C. Lee
2
, Yinlong Xu
1
, Qiu Cui
3
, Liu Tang
3
1
University of Science and Technology of China
2
The Chinese University of Hong Kong
3
PingCAP
zhgqiang@mail.ustc.edu.cn, {ykli, ylxu}@ustc.edu.cn, pclee@cse.cuhk.edu.hk, {cuiqiu, tl}@pingcap.com
Abstract—Persistent key-value (KV) stores are mainly designed
based on the Log-Structured Merge-tree (LSM-tree), which suffer
from large read and write amplifications, especially when KV
stores grow in size. Existing design optimizations for LSM-
tree-based KV stores often make certain trade-offs and fail to
simultaneously improve both the read and write performance on
large KV stores without sacrificing scan performance. We design
UniKV, which unifies the key design ideas of hash indexing and
the LSM-tree in a single system. Specifically, UniKV leverages da-
ta locality to differentiate the indexing management of KV pairs.
It also develops multiple techniques to tackle the issues caused by
unifying the indexing techniques, so as to simultaneously improve
the performance in reads, writes, and scans. Experiments show
that UniKV significantly outperforms several state-of-the-art KV
stores (e.g., LevelDB, RocksDB, HyperLevelDB, and PebblesDB)
in overall throughput under read-write mixed workloads.
I. INTRODUCTION
Persistent key-value (KV) storage organizes data in the form
of key-value pairs and forms a critical storage paradigm in
modern data-intensive applications, such as web search [1], [2],
e-commerce [3], social networking [4], [5], data deduplication
[6], [7], and photo stores [8]. Real-world KV workloads become
more diversified and are geared toward a mixed nature. For
example, four out of five Facebook’s Memcached workloads
are read-write mixed [9]; the read-write ratio of low-latency
workloads at Yahoo! has shifted from 8:2 to 1:1 in recent years
[10]; Baidu’s cloud workload also shows a read-write ratio
of 2.78:1 [11]. Such mixed workloads challenge the indexing
structure design of KV stores to achieve high read and write
performance, while supporting scalable storage.
The Log-Structured Merge-tree (LSM-tree) [12] is a popular
indexing design in modern persistent KV stores, including local
KV stores (e.g., LevelDB [2] and RocksDB [5]) and large-
scale distributed KV stores (e.g., BigTable [1], HBase [13], and
Cassandra [14]). The LSM-tree supports three main features
that are attractive for KV-store designs: (i) efficient writes, as
newly written KV pairs are batched and written sequentially
to persistent storage; (ii) efficient range queries (scans), as KV
pairs are organized in multiple levels in a tree-like structure
and sorted by keys in each level; and (iii) scalability, as KV
pairs are mainly stored in persistent storage and can also be
easily distributed across multiple nodes.
The LSM-tree, unfortunately, incurs high compaction and
multi-level access costs. As KV pairs are continuously written,
the LSM-tree flushes them to persistent storage from lower
levels to higher levels. To keep the KV pairs at each level sorted,
the LSM-tree performs regular compactions for different levels
by reading, sorting, and writing back the sorted KV pairs.
Such regular compactions incur I/O amplification (which can
reach a factor of 50
×
[15]), and hence severely hurt the I/O
performance and the endurance of storage systems backed by
solid-state drives (SSDs) [16]. Furthermore, as the LSM-tree
grows in size and expands to more levels, each lookup may
traverse multiple levels, thereby incurring high latency.
Many academic and industrial projects have improved the
LSM-tree usage for KV stores to address different performance
aspects and storage architectures (see §V). Examples include
new LSM-tree organizations (e.g., a trie-like structure in LSM-
trie [17] or a fragmented LSM-tree in PebblesDB [18]) and KV
separation [15], [19]. However, the indexing structure is still
largely based on the LSM-tree, and such solutions often make
delicate design trade-offs. For example, LSM-trie [17] trades
the scan support for improved read and write performance;
PebblesDB [18] relaxes the fully sorted requirement in each
level and sacrifices read performance; KV separation [15], [19]
keeps only keys and metadata in the LSM-tree and stores
values separately, but incurs extra lookup overhead to keys
and values in separate storage [19]. Thus, the full performance
potentials of KV stores are still constrained by the inherent
multi-level-based LSM-tree design.
Our insight is that hash indexing is a well-studied indexing
technique that supports a fast lookup of a specific KV pair.
However, combining hash indexing and the LSM-tree is
challenging, as each of them makes a different design trade-
off. For example, hash indexing supports high read and write
performance, but does not support efficient scans. Also, a
hash index is kept in memory for high performance, but the
extra memory usage poses scalability concerns when more KV
pairs are stored. On the other hand, the LSM-tree supports
both efficient writes and scans as well as high scalability, but
suffers from high compaction and multi-level access overheads.
Thus, we pose the following question: Can we unify both hash
indexing and the LSM-tree to simultaneously address reads,
writes, and scans in a high-performance and scalable fashion?
We observe that data locality, which also commonly exists in
KV storage workloads [9], [20], [21], offers an opportunity to
address the above problem. To leverage data locality, we design
UniKV, which unifies hash indexing and the LSM-tree in a
single system. Specifically, UniKV adopts a layered architecture
to realize differentiated data indexing by building a light-weight
in-memory hash index for the recently written KV pairs that
2
…
L0
…
L1
…
L2
…
…
L6
Immutable
MemTable
MemTable
memory
disk
flush
compaction
Log
kv pairs
…
bloom filter
data index
Footer
SSTable
Lowest
level
Highest
level
<key, value>
Fig. 1: Architecture of an LSM-tree-based KV store (LevelDB).
are likely to be frequently accessed (i.e., hot), and keeping the
large amount of infrequently accessed (i.e., cold) KV pairs in a
fully sorted order with an LSM-tree-based design. To efficiently
unify hash indexing and the LSM-tree without incurring large
memory and I/O overhead, UniKV carefully designs three
techniques. First, UniKV develops light-weight two-level hash
indexing to keep the memory overhead small while accelerating
the access to hot KV pairs. Second, to reduce the I/O overhead
incurred by migrating the hot KV pairs to the cold KV pairs,
UniKV designs a partial KV separation strategy to optimize
the migration process. Third, to achieve high scalability and
efficient read and write performance in large KV stores, UniKV
does not allow multiple levels among the cold KV pairs as
in conventional LSM-tree-based design; instead, it employs a
scale-out approach that dynamically splits data into multiple
independent partitions via a dynamic range partitioning scheme.
Based on the unified indexing with multiple carefully designed
techniques, UniKV simultaneously achieves high read, write,
scan performance for large KV stores.
We implement a UniKV prototype atop LevelDB [2] and
evaluate its performance via both micro-benchmarks and
YCSB [22]. For micro-benchmarks, compared to LevelDB [2],
RocksDB [5], HyperLevelDB [23], and PebblesDB [18], UniKV
achieves up to 9.6
×
, 7.2
×
, 3.2
×
, and 1.7
×
load throughput,
respectively. It also achieves significant throughput gains in both
updates and reads. For the six core YCSB workloads except for
scan-dominated workload E (in which UniKV achieves slightly
better performance), UniKV achieves 4.2-7.3
×
, 2.5-4.7
×
, 3.2-
4.8×, and 1.8-2.7× overall throughput, respectively.
II. BACKGROUND AND MOTIVATION
A. Background: LSM-tree
To support large-scale storage, many KV stores are designed
based on the LSM-tree (e.g., [2], [5], [15], [18], [19]). Figure 1
depicts the design of an LSM-tree-based KV store, using Lev-
elDB as an example. Specifically, it keeps two sorted skiplists in
memory, namely MemTable and Immutable MemTable, multiple
SSTables on disk, and a manifest file that stores the metadata of
the SSTables. SSTables on disk are organized as a hierarchy of
multiple levels, each of which contains multiple sorted SSTables
and has fixed data capacity. The data capacity in each level
increases from lower to higher levels in the LSM-tree. The
main feature of the LSM-tree is that data flows only from
lower to higher levels and KV pairs in each level are sorted to
balance the trade-off between read and write performance.
50GB 100GB
0
100
200
300
400
LevelDB RocksDB PebblesDB
(a) Read amplification
50GB 100GB
0
10
20
30
LevelDB RocksDB PebblesDB
(b) Write amplification
Fig. 2: Read & write amplification of LSM-tree-based KV stores.
The insertion of a new KV pair works as follows. The new
KV pair is first appended to an on-disk log file to enable
recovery. It is then added to the MemTable, which is sorted by
keys. Once the MemTable becomes full, it is converted to the
Immutable MemTable that will be flushed to level
L
0
on disk.
Thus, SSTables in L
0
could have overlaps. When L
i
becomes
full, the KV pairs at
L
i
will be merged into
L
i+1
through
compaction, which first reads out data in the two adjacent levels
and then rewrites them back to
L
i+1
after merging. Clearly, this
process introduces extra I/Os and causes write amplification.
The lookup of a KV pair search multiple SSTables. Specifi-
cally, it searches all the SSTables at level
L
0
, and one SSTable
from each of the other levels until the data is found. Although
Bloom filters [24] are adopted, due to their false positives and
limited memory for caching Bloom filters, multiple I/Os are
still needed for each read, thereby causing read amplification.
Limitations.
The main limitations of LSM-tree-based KV
stores are the large write and read amplifications. Prior studies
show that the write amplification factor of LevelDB could reach
up to 50
×
[15]. For example, when merging a SSTable from
L
i
to
L
i+1
, LevelDB may read up to 10 SSTables from
L
i+1
in the
worst case, and then write back these SSTables to
L
i+1
after
merging and sorting the KV pairs. Thus, some unique KV pairs
may be read and written many times when they are eventually
migrated from
L
0
to
L
6
through a series of compactions. This
degrades write throughput, especially for large KV stores.
The read amplification may be even worse due to two reasons.
First, there is no in-memory index for each KV pair, so a lookup
needs to search multiple SSTables from the lowest to highest
level. Second, checking an SSTable also needs to read multiple
index blocks and Bloom filter blocks within the SSTable. Thus,
the read amplification will be more serious when there are
more levels, and it may even reach over 300× [15].
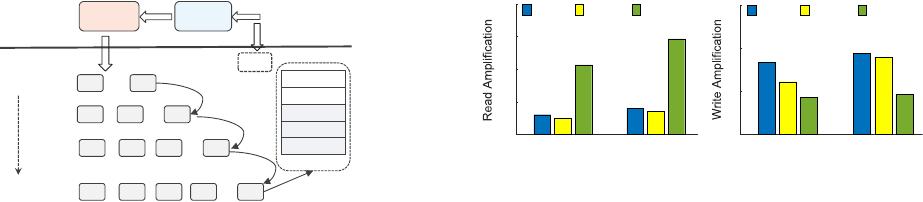
We evaluate various LSM-tree-based KV stores, including
LevelDB, RocksDB, and PebblesDB, to show the read and write
amplifications (see Figure 2). We test the read and write ampli-
fications for two different database sizes, 50 GB and 100 GB
(the KV pair size is 1 KB). For each KV store, we use the
default parameters, and do not use extra
SSTable_File_Level
Bloom filters for PebblesDB. We see that the read and write
amplifications increase to up to 292
×
and 19
×
, respectively,
as the database size increases to 100 GB. Thus, the read and
write performance degrades significantly in large KV stores.
B. Motivation
In-memory hash indexing.
Given the high write and read
amplifications in LSM-tree-based KV stores, we can leverage
of 12
免费下载
【版权声明】本文为墨天轮用户原创内容,转载时必须标注文档的来源(墨天轮),文档链接,文档作者等基本信息,否则作者和墨天轮有权追究责任。如果您发现墨天轮中有涉嫌抄袭或者侵权的内容,欢迎发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
下载排行榜

评论