




Oracle Cache Fusion
5墨值下载

Abstract
Cache Fusion
TM
is a fundamental component of
Oracle’s Real Application Cluster configuration,
a shared-cache clustered-database architecture
that transparently extends database applications
from single systems to multi-node shared-disk
clusters. In classic shared-disk implementations,
the disk is the medium for data sharing and data
blocks are shipped between nodes through disk
writes and reads under the arbitration of a distrib-
uted lock manager. Cache Fusion extends this
capability of a shared-disk architecture by allow-
ing nodes to share the contents of their volatile
buffer caches through the cluster interconnect.
Using Cache Fusion, data blocks are shipped
directly from one node to another using intercon-
nect messaging, eliminating the need for extra
disk I/Os to facilitate data sharing. Cache Fusion
thus greatly improves the performance and scal-
ability characteristics of shared-disk clusters
while continuing to preserve the availability ben-
efits of shared-disk architectures.
1. Introduction
A cluster is a group of independent servers that cooperate
as a single system. The key components of a cluster are the
constituent server nodes, the interconnect, and the disk
subsystem. The Oracle Real Application Cluster (RAC)
architecture is a clustered database architecture running on
a shared-disk cluster, a form of cluster in which all nodes
have direct access to all disks. RAC is so called since it
transparently allows any database application to run on a
cluster without requiring any application changes. RAC
allows for improvements in application performance since
the application is executed in parallel across multiple sys-
tems, as well as improvements in availability, since the
application is available as long as at least one of the cluster
nodes is alive.
In a classic shared-disk clustered database, the disk is the
medium of data coherency across the cluster nodes. For
instance, if a node requires a copy of a block that is pres-
ently dirty in another node’s buffer cache, the second node
must first write the block to disk before the first node can
read the block.
However, recent advances in cluster hardware technology
merit a fresh approach to building clustered databases.
Storage Area Networks (SAN) now provide sophisticated
mechanisms for disk connectivity, circumventing the limi-
tations of directly attached disks by allowing each node to
be connected to a much larger number of disks. For exam-
ple, Infiniband
SM
[2] is an emerging standard for high-per-
formance clusters, and by using the same protocol for I/O
and inter-node messaging allows cluster networks that
carry both data and cluster interconnect messages. Other
high-performance commodity interconnect standards such
as Virtual Interface Architecture (VIA)[4] now allow ven-
dors to build high-performance clusters from standard
components. These advances mean that clusters are now
becoming mainstream, capable of high data volumes and
high data-transfer bandwidths.
Cache Fusion exploits these advances in clustering tech-
nology by using the network rather than the disk as the
medium for data sharing between nodes. With the Cache
Fusion protocol, blocks can be shipped directly between
Oracle Instances through fast inter-node messaging, with-
out requiring expensive disk I/O. Oracle instances there-
fore directly share the contents of their volatile buffer
caches, resulting in a shared-cache clustered database
architecture.
Permission to copy without fee all or part of this material
is granted provided that the copies are not made or dis-
tributed for direct commercial advantage, the VLDB
copyright notice and the title of the publication and its
date appear, and notice is given that copying is by per-
mission of the Very Large Data Base Endowment. To
copy otherwise, or to republish, requires a fee and/or
special permission from the Endowment.
Proceedings of the 27th VLDB Conference,
Roma, Italy 2001
Cache Fusion: Extending Shared-Disk Clusters with Shared Caches
Tirthankar Lahiri, Vinay Srihari, Wilson Chan, Neil Macnaughton, Sashikanth Chandrasekaran
Oracle Corporation
{tirthankar.lahiri, vinay.srihari, wilson.chan, neil.macnaughton, sashikanth.chandrasekaran}@oracle.com
The rest of this paper is organized as follows: Section 2
contains a brief overview of the Real Application Cluster
architecture. Section 3 describes Cache Fusion protocols,
highlighting techniques for read-sharing, write-sharing, as
well as efficient inter-node messaging. Section 4 briefly
discusses RAC mechanisms for Decision Support work-
loads. Section 5 describes recovery mechanisms with
Cache Fusion. Finally, Section 6 concludes.
2. Overview of Real Application Clusters
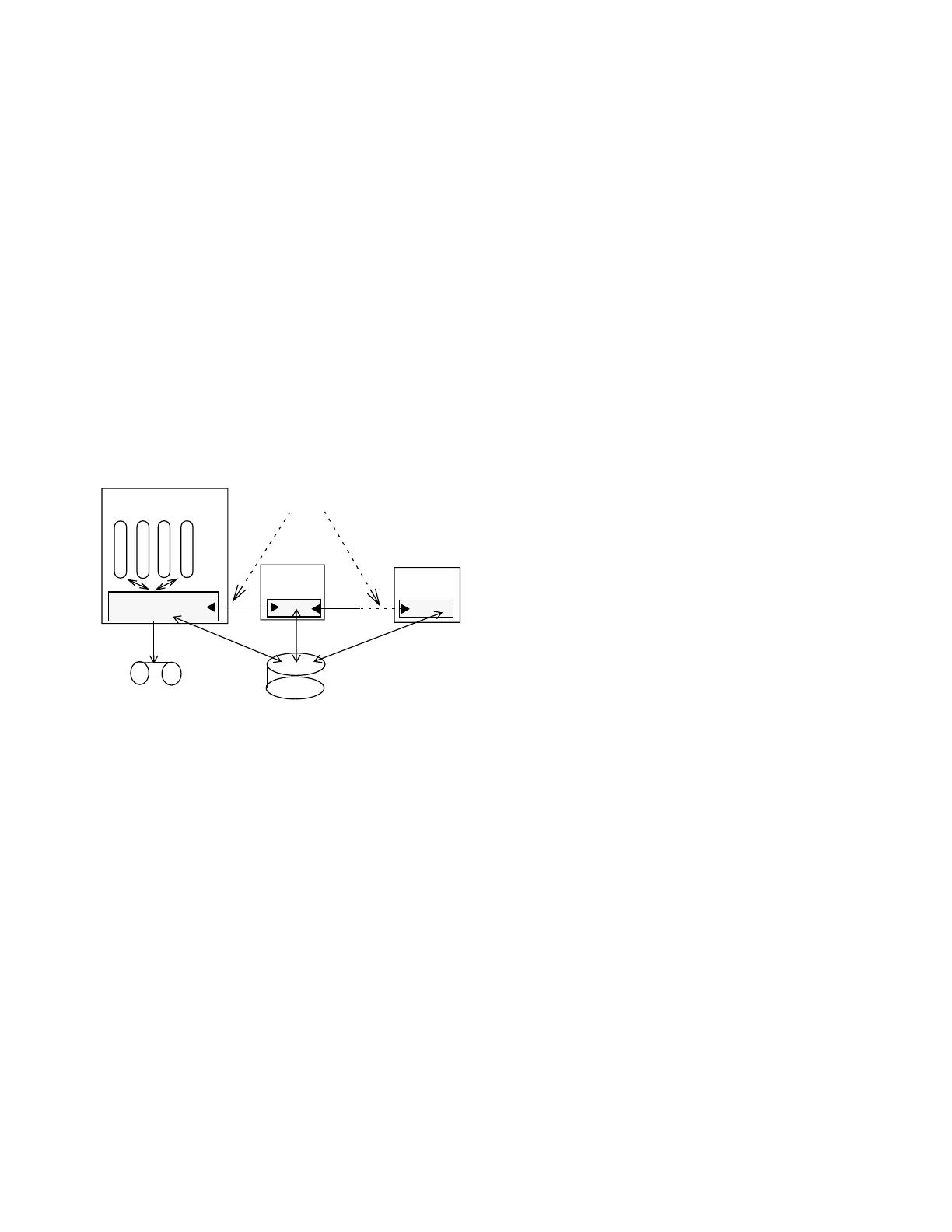
An Oracle Instance is a collection of processes and mem-
ory accessing a shared set of data files (see Figure 1
below). Each Oracle instance inside RAC has its own pri-
vate set of log files referred to as a Redo Thread. Each
instance also has its own buffer cache of disk buffers, and
taken together, these local caches form a global buffer
cache. In order to maintain cache coherency in this global
cache, global resource control is needed. We call this
resource control mechanism the Global Cache Service
(GCS). For additional details on RAC and GCS, see [3].
The GCS tracks and maintains the locations and access
modes of all cache resources (data blocks) in the global
cache. It synchronizes global cache accesses, allowing
only one instance at a time to modify a cache resource.
The GCS adopts a distributed architecture. Each instance
shares the responsibility of managing a subset of the glo-
bal cache. There are several advantages to this approach.
First, the work of handling cache resource requests can be
evenly divided among all existing database instances. Sec-
ond, in case of hardware or software failure in a node, only
the instance running on the failed node is affected. Access
to cache resources managed by this instance may be tem-
porarily unavailable. However, all other resources will
continue to be accessible.
The assignment of global resources to a particular instance
takes into account the access pattern of cache resources.
Resources accessed most frequently by an instance will be
likely to be managed by the same instance.
By knowing the global view of all data blocks, GCS can
direct a read or write request to the instance that can best
serve it. For example, suppose an instance issues an upda-
tee request for a particular block to the GCS. The GCS
will then forward the request to the instance which has the
current cached buffer for that block. This current holder
will transfer the cache buffer to the requester instance
directly, and the GCS will then update the holder informa-
tion to reflect the fact that the requesting instance is now
the holder.
3. Cache Fusion
Cache fusion refers to the protocol for sharing of instance
buffer cache contents through fast inter-node messaging,
resulting in a cluster-wide global buffer cache. There are
two types of sharing involved: Read-Sharing, which refers
to the mechanism used by a query to access the contents of
another instance’s buffer cache, and Write-Sharing which
refers to the mechanism by which an update operation
accesses data in another instance’s cache. In the following
subsections, we describe both kinds of sharing, followed
by a brief description of inter-node messaging.
3.1 Cache Fusion Read-Sharing
The mechanism for read-sharing in Cache Fusion exploits
Oracle’s Consistent Read (CR) mechanism [1]. CR is a
version-based concurrency control protocol which allows
transactions to perform reads without acquiring any locks.
Each transaction in Oracle is associated with a snapshot
time, known as the System Change Number (SCN), and
the CR mechanism guarantees that any data read by a
transaction is transactionally consistent as of that SCN.
When a transaction performs a change to a block, it stores
the information required to undo that change in a rollback
segment. When a transaction reads a block, the CR mecha-
nism uses the stored undo information to create an earlier
version of the block (a clone) which is consistent as of the
reading transaction’s SCN. Clones are created in-memory
and are never written to disk. A read operation therefore
never needs to wait for another transaction to commit or
abort since the CR mechanism automatically reconstructs
the version of the block required by the operation. This
mechanism therefore allows high concurrency for read
operations.
In RAC, when Instance A requires read access to a block
that is present in the buffer cache in Instance B, it requests
a copy of the block from Instance B without requiring any
change of resource ownership. Instance B creates a trans-
server and system
buffer cache
instance 2
instance N
instance 1
shared datafiles
redo
processes
Figure 1: Oracle Instances in RAC
thread
Fast Inter Node Messaging
of 4
5墨值下载
【版权声明】本文为墨天轮用户原创内容,转载时必须标注文档的来源(墨天轮),文档链接,文档作者等基本信息,否则作者和墨天轮有权追究责任。如果您发现墨天轮中有涉嫌抄袭或者侵权的内容,欢迎发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
下载排行榜

评论