




Oracle Streaming Data with GoldenGate
免费下载

OpenWorld London:
Streaming Data with GoldenGate
O R A C L E D E V E L O P M E N T , F E B - 2020
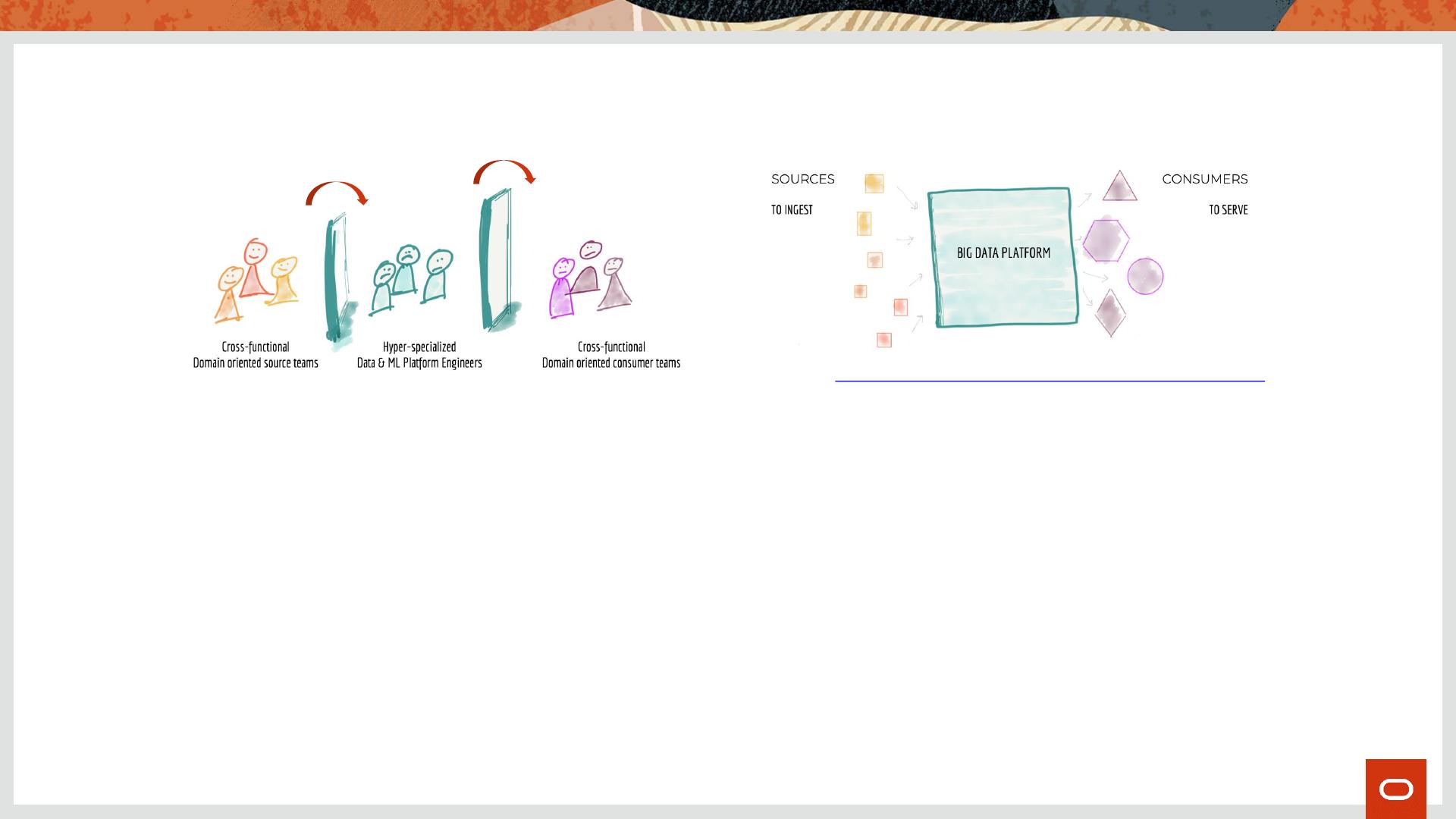
The Problems of Monolithic Data Architecture
Copyright © 2020 Oracle and/or its affiliates.
People Process
Technology
• Business units may have few
incentives work across boundaries
• Hyper-specialization in tech teams
narrow the focus on technology
rather than outcomes or solutions
• Pressure on all stakeholders to
produce value, but org structures
still a carry-over from older EDW
projects
• The classical Lambda/Kappa
“Ingest -> Process -> Serve” design
institutionalizes Batch Processing
into the team processes
• Conceptually it is still “Extract -
> Transform -> Load” but with
other words/syntax
• The monolithic data lake is big and
slow by design, not by accident
• Architecture decomposition
happens at several layers, but Big
Data is inarguably “storage centric”
• From HDFS (Hadoop) to Object
Storage (Cloud) the classical
approach is “the Lake” as a physical
area where we pile up data
• But data is not static, data is in a
constant state of dynamic
equilibrium
Images: https://martinfowler.com/articles/data-monolith-to-mesh.html
2
of 24
免费下载
【版权声明】本文为墨天轮用户原创内容,转载时必须标注文档的来源(墨天轮),文档链接,文档作者等基本信息,否则作者和墨天轮有权追究责任。如果您发现墨天轮中有涉嫌抄袭或者侵权的内容,欢迎发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
下载排行榜

评论