




Lightweight and Accurate Cardinality Estimation by Neural Network Gaussian Process.pdf
免费下载

Lightweight and Accurate Cardinality Estimation
by Neural Network Gaussian Process
Kangfei Zhao, Jerey Xu Yu, Zongyan He, Rui Li, Hao Zhang
The Chinese University of Hong Kong
Hong Kong S. A. R., China
{kfzhao,yu,zyhe,lirui,hzhang}@se.cuhk.edu.hk
ABSTRACT
Deep Learning (DL) has achieved great success in many real appli-
cations. Despite its success, there are some main problems when
deploying advanced DL models in database systems, such as hyper-
parameters tuning, the risk of overtting, and lack of prediction
uncertainty. In this paper, we study a lightweight and accurate
cardinality estimation for SQL queries, which is also uncertainty-
aware. By lightweight, we mean that we can train a DL model in
a few seconds. With uncertainty ensured, it becomes possible to
update the estimator to improve its prediction in areas with high
uncertainty. The approach we explore is dierent from the direction
of deploying sophisticated DL models as cardinality estimators in
database systems. We employ Bayesian deep learning (BDL), which
serves as a bridge between Bayesian inference and deep learning.
The prediction distribution by BDL provides principled uncertainty
calibration for the prediction. In addition, when the network width
of a BDL model goes to innity, the model performs equivalent to
Gaussian Process (GP). This special class of BDL, known as Neu-
ral Network Gaussian Process (NNGP), inherits the advantages
of Bayesian approach while keeping universal approximation of
neural networks, and can utilize a much larger model space to
model distribution-free data as a nonparametric model. We show
our NNGP estimator achieves high accuracy, is built fast, and is ro-
bust to query workload shift, in our extensive performance studies
by comparing with existing learned estimators. We also conrm
the eectiveness of NNGP by integrating it into PostgreSQL.
CCS CONCEPTS
• Information systems → Query optimization.
KEYWORDS
Cardinality Estimation; Machine Learning; Gaussian Process
ACM Reference Format:
Kangfei Zhao, Jerey Xu Yu, Zongyan He, Rui Li, Hao Zhang. 2022. Light-
weight and Accurate Cardinality Estimation by Neural Network Gaussian
Process. In Proceedings of the 2022 International Conference on Management
of Data (SIGMOD ’22), June 12–17, 2022, Philadelphia, PA, USA. ACM, New
York, NY, USA, 15 pages. https://doi.org/10.1145/3514221.3526156
Permission to make digital or hard copies of all or part of this work for personal or
classroom use is granted without fee provided that copies are not made or distributed
for prot or commercial advantage and that copies bear this notice and the full citation
on the rst page. Copyrights for components of this work owned by others than ACM
must be honored. Abstracting with credit is permitted. To copy otherwise, or republish,
to post on servers or to redistribute to lists, requires prior specic permission and/or a
fee. Request permissions from permissions@acm.org.
SIGMOD ’22, June 12–17, 2022, Philadelphia, PA, USA
© 2022 Association for Computing Machinery.
ACM ISBN 978-1-4503-9249-5/22/06.. .$15.00
https://doi.org/10.1145/3514221.3526156
1 INTRODUCTION
The learning approaches are shifting from the traditional ML (Ma-
chine Learning) models (e.g., KDE, GBDT) to DL (Deep Learning)
models (e.g., NN, MSCN, VAE, MADE, Transformer, SPN, LSTM).
The shifting is motivated by the powerful approximation capability
of neural networks in end-to-end applications and the high e-
ciency of DL frameworks. Compared with traditional ML, DL has
achieved a great improvement in estimation accuracy, and more
and more advanced DL architectures are devised to improve the per-
formance of the learning tasks with deeper layers to pursue more
powerful modeling capability. In database systems, the DL models
have been extensively studied for query optimization [
49
], index
recommendation [
11
], view materialization [
44
], and cardinality
estimation [
15
,
16
,
27
,
32
,
33
,
60
,
71
,
72
]. Despite the success of DL
approaches, complex DL approaches incur some main problems in
general.
The rst is hyper-parameters on which the performance of DL
models highly rely, including the training hyper-parameters and
network architecture congurations. Note that onerous eort of
parameter tuning must be paid to pursuing satisfying performance,
which is labor-intensive. Although autoML tools [
31
] have been
developed to avoid human-in-the-loop, deploying such tools in
database systems needs great eort as searching for a suitable
hyper-parameter combination needs a huge number of trials with
high computation cost. It is worth mentioning that a well-tuned
model for one database is dicult to transfer to other databases,
which means that the retraining/tuning needs repeating when the
underlying data changes signicantly.
The second is a high risk of overtting that DL models are ex-
posed to. Subject to a particular family of functions designed, gen-
eral DL models are indexed by a large number of parameters, fully
tted by the training data. It is assumed testing data is from the
same underlying distribution as the training data, otherwise, the
prediction may have a large variance. Many regularization tech-
niques can be used, but they can only alleviate the problem to
some degree. Collecting more data to enhance training helps to
reduce the variance. But this means a higher cost for acquiring the
data/ground truth and training.
The third is prediction belief. The issue is that DL models cannot
capture and convey their prediction belief, namely, how probably
their prediction is accurate or how much is the prediction uncer-
tainty. The uncertainty comes from dierent sources. For classi-
cation tasks, DL models predict the probability distribution that
one data point is associated with the candidate classes by a
somax
function, which is shown to be over-condent on the most likely
class [
25
]. For regression tasks (e.g., cardinality estimation), DL
models can only output a scalar value without any uncertainty
Session 13: ML for Data Management and Query Processing
SIGMOD ’22, June 12–17, 2022, Philadelphia, PA, USA
973
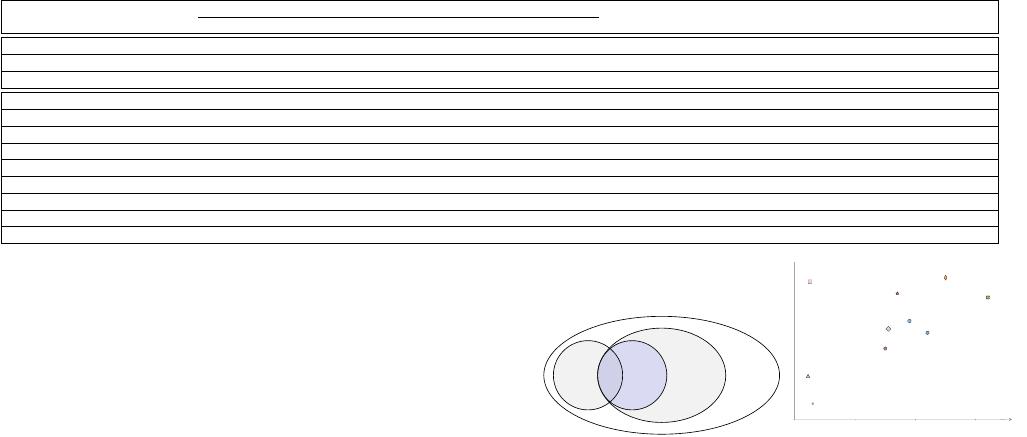
Table 1: ML/DL Approaches for AQP and Cardinality Estimation
Approach
Supported Queries
Learning Strategy Model Model Update
Join Selection Aggregate Group By
DBEst [46] precomp. join num., cate. cnt,sum,avg,etc. ✓ supervised & unsupervised KDE & GBDT ✗
DeepDB [28] precomp. join num., cate. cnt,sum,avg ✓ unsupervised SPN ✓
Thirumuruganathan et. al. [61] ✗ num., cate. cnt,sum,avg ✓ unsupervised VAE ✗
Kiefer et al. [32] Equi-join num., cate. cnt ✗ unsupervised KDE ✓
Kipf et al. [33] PK/FK join num., cate. cnt ✗ supervised MSCN ✗
Dutt et al. [16] ✗ num., cate. cnt ✗ supervised NN, GBDT ✗
Dutt et al. [15] PK/FK join num., cate. cnt ✗ supervised GBDT ✓
Sun et al. [60] PK/FK join num., cate., str. cnt ✗ supervised Tree LSTM ✓
Fauce [45] PK/FK join num. cnt ✗ supervised NN, Deep Ensemble ✓
Hasan et al. [27] ✗ num., cate. cnt ✗ unsupervised MADE ✗
Naru [72] precomp. join num., cate. cnt ✗ unsupervised MADE, Transformer ✓
NeuroCard [71] Full outer join num., cate., cnt ✗ unsupervised MADE, Transformer ✓
measurements of the prediction, such as variance and condential
interval. It is highly desirable to avoid situations where we have no
choice but trust the DL predictions being made in database systems.
In other words, as a database system supports a large number of
users in various applications, where user queries may be dierent
and databases will be updated from time to time, what database
systems require is not only an accurate model prediction, but also
an indication of how much the predictions can be trusted regarding
the learned model.
In this paper, we study a lightweight and accurate cardinality
estimation for SQL queries with selection, projection, and join. By
lightweight, we mean to train a model in a few seconds. Table 1
summarizes the recent ML/DL approaches studied for AQP (Approx-
imate Query Processing) (the top three) and cardinality estimation
(the bottom nine). These approaches are categorized into super-
vised learning approaches and unsupervised learning approaches.
Supervised learning approaches are query-driven, which learn a
function that maps the features of a query to its cardinality. Un-
supervised learning approaches are data-driven, which learn the
joint probability distribution of the underlying relational data. Su-
pervised learning approaches are easy to deploy with relatively low
training and prediction overhead, however, they lack robustness to
shifting query workloads. On the contrary, unsupervised learning
approaches are robust to dierent query workloads. But, model
construction consumes many resources as large volumes of data
need to be fed into the model multiple times. Furthermore, unsu-
pervised estimators suer from underestimation for range queries
as the prediction is conducted by integration over the learned dis-
tribution regarding the query condition. In this work, we study
cardinality estimation based on a supervised approach with a pre-
dictive uncertainty. It is important that the system is aware that
the estimator may be outdated and need retraining if the learned
estimator delivers a low condence level for a large fraction of
arrival queries.
Dierent from the direction of deploying sophisticated DL mod-
els in database systems, we employ Bayesian deep learning (BDL)
to build cardinality estimators, where BDL serves as a bridge be-
tween Bayesian inference and deep learning [
65
]. In a nutshell, BDL
imposes a prior distribution on the neural network weights, and
the derived models are ensembles of neural networks in particular
function space, which output a distribution as the prediction. The
predictive distribution provides principled uncertainty calibration
for the prediction. This uncertainty helps the model to improve
ML
• KDE
• GBDT
• SPN
DL
• DNN
• MSCN
• Tree LSTM
• Transformer
• MADE
• VAE
BDLGP
NNGP
(a)
1
10
10
2
10
3
Training time(s)
Low ⟵ Accuracy ⟶ High
GP
GBDT
NNGP(Ours)
NN
MSCN
Tree LSTM
DeepDB
NeuroCard
BNN
Fauce
(b)
Figure 1: (a) From ML/DL estimators To NNGP (GP & BDL)
(b) Accuracy and Training Time of Learned Estimators
itself explicitly, by collecting the information of testing data with
higher uncertainty and retraining/ne-tuning the model. In addi-
tion, the predictive distribution by BDL is robust to overtting. The
parameters and hyper-parameters of BDL models are much fewer
(i.e., the statistics of the prior distribution and the prior type, respec-
tively), in contrast to the parameters and hyper-parameters of DL
models (i.e., the weights of the neural networks and the network
architecture congurations, number of layers, number of hidden
units in each layer), and in DL training congurations (i.e., opti-
mization algorithm, learning rate, batch size, epochs, etc.). When
the network width of the BDL model goes to innity, the model
performs equivalent to Gaussian Process (GP) [
52
], named Neu-
ral Network Gaussian Process (NNGP). Exact Bayesian inference
can be used to train this special GP as a lightweight cardinality
estimator, while oering a more powerful generalization capabil-
ity than a nite wide neural network. NNGP keeps the exible
modeling capability of deep learning, while oering robustness
and interpretability by Bayesian inference. Fig. 1(a) delineates the
extraordinary standpoint of our NNGP estimator among the ex-
isting ML/DL-based estimators in Table 1. Here, KDE and GBDT
are classical ML models while SPN is a new type of probabilistic
graphical model with deeper layers. DL models are associated with
dierent neural network architectures. A BDL model is a special
kind of DL model in which the neural network parameters are prob-
ability distributions. The model we explore, NNGP, is a BDL model
with innite wide hidden layers and can be built using GP. We
show the training cost vs accuracy in Fig. 1(b) based on our exten-
sive experimental studies. Here, MSCN, SPN (DeepDB), MADE and
Transformer (NeuroCard) achieve high accuracy with high training
cost in the magnitude of 100-1,000 seconds. Tree LSTM and NN
Session 13: ML for Data Management and Query Processing
SIGMOD ’22, June 12–17, 2022, Philadelphia, PA, USA
974
of 15
免费下载
【版权声明】本文为墨天轮用户原创内容,转载时必须标注文档的来源(墨天轮),文档链接,文档作者等基本信息,否则作者和墨天轮有权追究责任。如果您发现墨天轮中有涉嫌抄袭或者侵权的内容,欢迎发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
下载排行榜

评论