




Google_三大论文中文版.pdf
免费下载

Alex && OpenCould
又一个 Ixiezi.com 博客
首页
About
Google论文
小道消息
未分类
请输入关键字...
Bigtable:一个分布式的结构化数据存储系统[中文版]
2010年3月27日 blademaster 没有评论
Bigtable:一个分布式的结构化数据存储系统
译者:
alex
摘要
Bigtable是一个分布式的结构化数据存储系统,它被设计用来处理海量数据:通常是分布在数千台普通服
务器上的PB级的数据。Google的很多项目使用Bigtable存储数据,包括Web索引、Google Earth、
Google Finance。这些应用对Bigtable提出的要求差异非常大,无论是在数据量上(从URL到网页到卫
星图像)还是在响应速度上(从后端的批量处理到实时数据服务)。尽管应用需求差异很大,但是,针对
Google的这些产品,Bigtable还是成功的提供了一个灵活的、高性能的解决方案。本论文描述了Bigtable
提供的简单的数据模型,利用这个模型,用户可以动态的控制数据的分布和格式;我们还将描述Bigtable
的设计和实现。
1 介绍
在过去两年半时间里,我们设计、实现并部署了一个分布式的结构化数据存储系统 — 在Google,我们称
之为Bigtable。Bigtable的设计目的是可靠的处理PB级别的数据,并且能够部署到上千台机器上。
Bigtable已经实现了下面的几个目标:适用性广泛、可扩展、高性能和高可用性。Bigtable已经在超过60
个Google的产品和项目上得到了应用,包括Google Analytics、Google Finance、Orkut、
Personalized Search、Writely和Google Earth。这些产品对Bigtable提出了迥异的需求,有的需要高
吞吐量的批处理,有的则需要及时响应,快速返回数据给最终用户。它们使用的Bigtable集群的配置也有
很大的差异,有的集群只有几台服务器,而有的则需要上千台服务器、存储几百TB的数据。
在很多方面,Bigtable和数据库很类似:它使用了很多数据库的实现策略。并行数据库【14】和内存数据
库【13】已经具备可扩展性和高性能,但是Bigtable提供了一个和这些系统完全不同的接口。Bigtable不
支持完整的关系数据模型;与之相反,Bigtable为客户提供了简单的数据模型,利用这个模型,客户可以
动态控制数据的分布和格式
(
alex
注:也就是对
BigTable
而言,数据是没有格式的,用数据库领域的术语
说,就是数据没有
Schema
,用户自己去定义
Schema
),
用户也可以自己推测(alex
注:
reason about)
底层存储数据的位置相关性(alex
注:位置相关性可以这样理解,比如树状结构,具有相同前缀的数据的存
放位置接近。在读取的时候,可以把这些数据一次读取出来
)。数据的下标是行和列的名字,名字可以是任
意的字符串。Bigtable将存储的数据都视为字符串,但是Bigtable本身不去解析这些字符串,客户程序通
常会在把各种结构化或者半结构化的数据串行化到这些字符串里。通过仔细选择数据的模式,客户可以控
制数据的位置相关性。最后,可以通过BigTable的模式参数来控制数据是存放在内存中、还是硬盘上。
第二节描述关于数据模型更多细节方面的东西;第三节概要介绍了客户端API;第四节简要介绍了
BigTable底层使用的Google的基础框架;第五节描述了BigTable实现的关键部分;第6节描述了我们为了
提高BigTable的性能采用的一些精细的调优方法;第7节提供了BigTable的性能数据;第8节讲述了几个
Google内部使用BigTable的例子;第9节是我们在设计和后期支持过程中得到一些经验和教训;最后,在
第10节列出我们的相关研究工作,第11节是我们的结论。
2 数据模型
Bigtable是一个稀疏的、分布式的、持久化存储的多维度排序Map
(
alex
注:对于程序员来说,
Map
应该
不用翻译了吧。
Map
由
key
和
value
组成,后面我们直接使用
key
和
value
,不再另外翻译了)。
Map的索
引是行关键字、列关键字以及时间戳;Map中的每个value都是一个未经解析的byte数组。
(row:string, column:string,time:int64)->string
我们在仔细分析了一个类似Bigtable的系统的种种潜在用途之后,决定使用这个数据模型。我们先举个具
体的例子,这个例子促使我们做了很多设计决策;假设我们想要存储海量的网页及相关信息,这些数据可
以用于很多不同的项目,我们姑且称这个特殊的表为Webtable。在Webtable里,我们使用URL作为行关
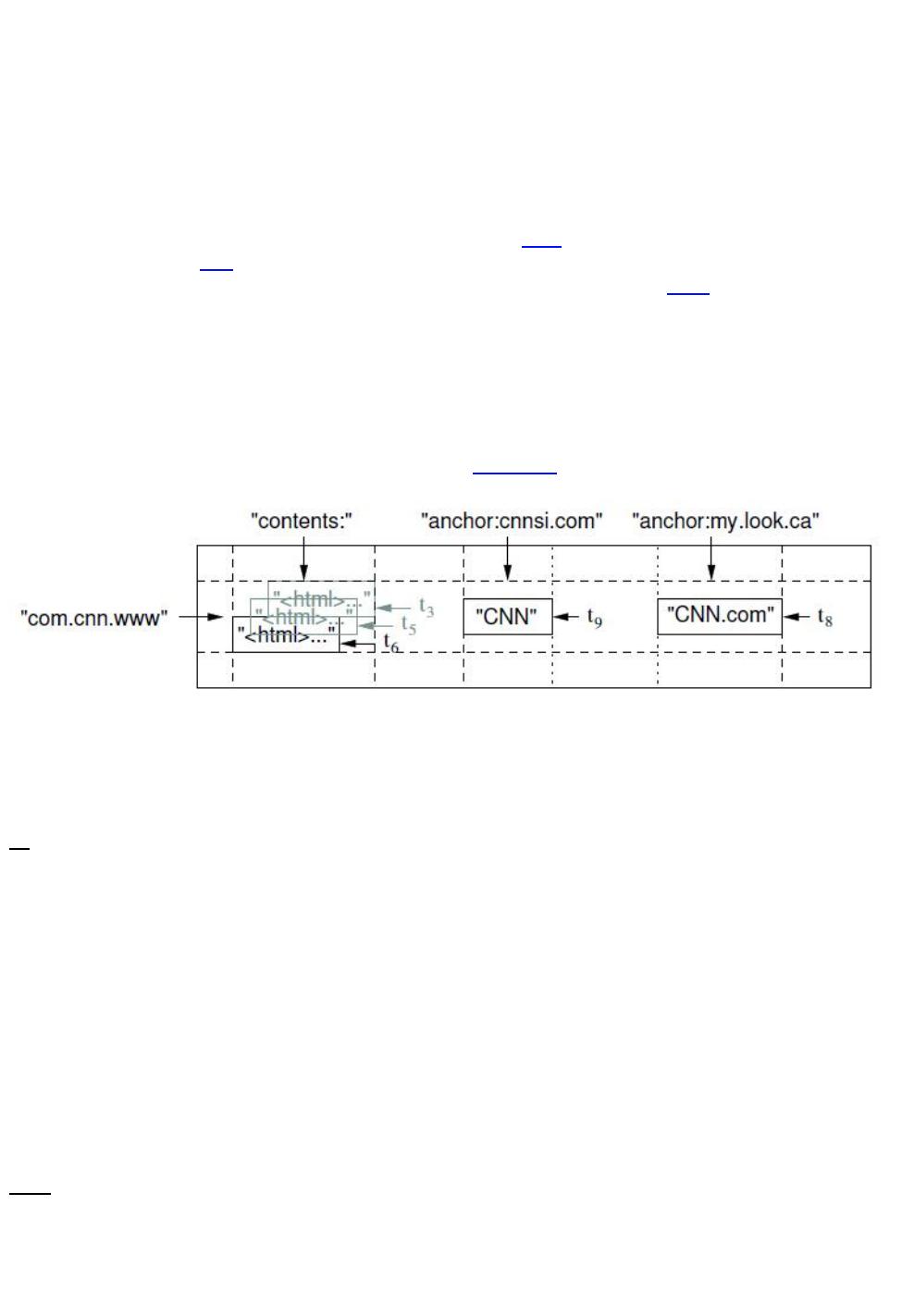
键字,使用网页的某些属性作为列名,网页的内容存在“contents:”列中,并用获取该网页的时间戳作为
标识(alex
注:即按照获取时间不同,存储了多个版本的网页数据
),如图一所示。
图一:一个存储Web网页的例子的表的片断。行名是一个反向URL。contents列族存放的是网页的内容,anchor列族存放引用该网页的锚链接文本
(
alex
注:如果不知道
HTML
的
Anchor
,请
Google
一把)。
CNN的主页被Sports Illustrater和MY-look的主页引用,因此该行包含了名为“anchor:cnnsi.com”和 “anchhor:my.look.ca”的列。每个锚链接只有一
个版本
(
alex
注:注意时间戳标识了列的版本,
t9
和
t8
分别标识了两个锚链接的版本);
而contents列则有三个版本,分别由时间戳t3,t5,和t6标识。
行
表中的行关键字可以是任意的字符串(目前支持最大64KB的字符串,但是对大多数用户,10-100个字节
就足够了)。对同一个行关键字的读或者写操作都是原子的(不管读或者写这一行里多少个不同列),这
个设计决策能够使用户很容易的理解程序在对同一个行进行并发更新操作时的行为。
Bigtable通过行关键字的字典顺序来组织数据。表中的每个行都可以动态分区。每个分区叫做一
个”Tablet”,Tablet是数据分布和负载均衡调整的最小单位。这样做的结果是,当操作只读取行中很少几
列的数据时效率很高,通常只需要很少几次机器间的通信即可完成。用户可以通过选择合适的行关键字,
在数据访问时有效利用数据的位置相关性,从而更好的利用这个特性。举例来说,在Webtable里,通过
反转URL中主机名的方式,可以把同一个域名下的网页聚集起来组织成连续的行。具体来说,我们可以把
maps.google.com/index.html的数据存放在关键字com.google.maps/index.html下。把相同的域中
的网页存储在连续的区域可以让基于主机和域名的分析更加有效。
列族
列关键字组成的集合叫做“列族“,列族是访问控制的基本单位。存放在同一列族下的所有数据通常都属于
同一个类型(我们可以把同一个列族下的数据压缩在一起)。列族在使用之前必须先创建,然后才能在列
族中任何的列关键字下存放数据;列族创建后,其中的任何一个列关键字下都可以存放数据。根据我们的
设计意图,一张表中的列族不能太多(最多几百个),并且列族在运行期间很少改变。与之相对应的,一
of 60
免费下载
【版权声明】本文为墨天轮用户原创内容,转载时必须标注文档的来源(墨天轮),文档链接,文档作者等基本信息,否则作者和墨天轮有权追究责任。如果您发现墨天轮中有涉嫌抄袭或者侵权的内容,欢迎发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
下载排行榜

评论