




Kudu--入门指南.docx
5墨值下载
Kudu--
入门指南
一、
介绍
、背景介绍
在
之前,大数据主要以两种方式存储;
【
】:静态数据
以
引擎作为存储引擎,适用于高吞吐量的离线大数据分析场景。这类存储的局限性是数据无
法进行随机的读写。
【
】:动态数据以
、
作为存储引擎,适用于大数据随机读写场景。 局限性是批量
读取吞吐量远不如
,不适用于批量数据分析的场景。
这两种数据在存储方式上完全不同,进而导致使用场景完全不同,但在真实的场景中,边界可能没有那么
清晰,面对既需要随机读写,又需要批量分析的大数据场景,该如何选择呢? 个场景中,单种存储引擎
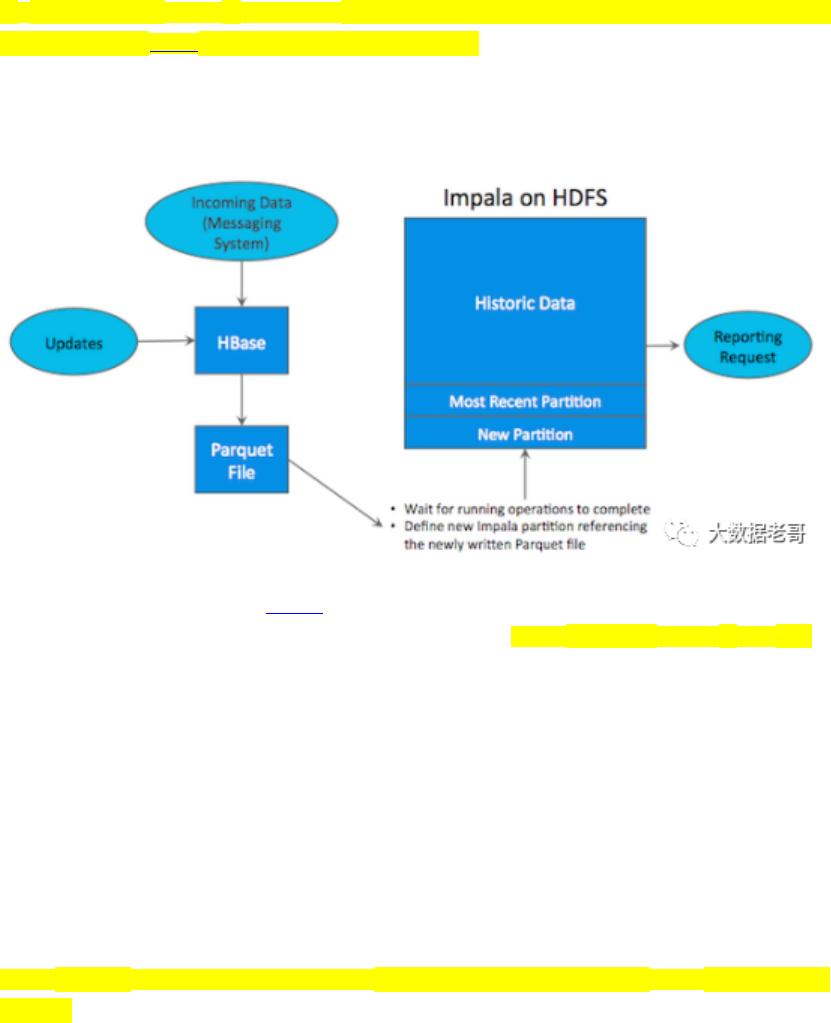
无 法 满 足 业 务 需 求 , 我 们 需 要 通 过 多 种 大 数 据 工 具 组 合 来 满 足 这 一 需 求 , 如 下 图 所 示 :
如上图所示,数据实时写入
,实时的数据更新也在
完成,为了应对
需求,我
们定时将
数据写成静态的文件(如:
)导入到
引擎(如:
、
)。这
一架构能满足既需要随机读写,又可以支持
分析的场景,但他有如下缺点:
架构复杂。从架构上看,数据在
、消息队列、
间流转,涉及环节太多,运维成本很高。并
且每个环节需要保证高可用,都需要维护多个副本,存储空间也有一定的浪费。最后数据在多个系统上,
对数据安全策略、监控等都提出了挑战。
时效性低。数据从
导出成静态文件是周期性的,一般这个周期是一天(或一小时),在时效
性上不是很高。
难以应对后续的更新。真实场景中,总会有数据是延迟到达的。如果这些数据之前已经从
导出到
,新到的变更数据就难以处理了,一个方案是把原有数据应用上新的变更后重写一遍,但这代价又
很高。为了解决上述架构的这些问题,
应运而生。
的定位是
!"#
,是一个既支持随机读写、又支持
分析的大数据存
储引擎。

从上图可以看出,
是一个折中的产品,在
和
这两个偏科生中平衡了随机读写和批
量分析的性能。从
的诞生可以说明一个观点:底层的技术发展很多时候都是上层的业务推动的,
脱离业务的技术很可能是空中楼阁。
新的硬件设备
内存(
$%
)的技术发展非常快,它变得越来越便宜,容量也越来越大。
#
的客户数据显示,
他们的客户所部署的服务器,
&
年每个节点仅有
'($%
,现如今增长到每个节点有
)(
或
*+($%
。存储设备上更新也非常快,在很多普通服务器中部署
也是屡见不鲜。
、
、以及其他的
##
工具都在不断自我完善,从而适应硬件上的升级换代。然而
根本上,
基于
&'
年
(
,
基于
&*
年
,-.
,在当时系统瓶颈主要取决于底层磁盘
速度。 当磁盘速度较慢时,
利用率不足的根本原因是磁盘速度导致的瓶颈,当磁盘速度提高了之后,
利用率提高,这时候
往往成为系统的瓶颈。
、
由于年代久远,已经很难从基本
架构上进行修改,而
是基于全新的设计,因此可以更充分地利用
$%
、
/
资源,并优化
利
用率。
可以理解为:
相比与以往的系统,
使用降低了,
/
的使用提高了,
$%
的利用更充分了 。
、
是什么
官方介绍:
是为
"##
平台开发的列式存储管理器。
具有
##
生态系统应
用程序的共同技术属性:它在商品硬件上运行,具有水平可扩展性,并支持高可用操作。简单来说:
0
是一个与
.
类似的列式存储分布式数据库。
'
为什么需要
0
?
与
的数据存储的缺点目前数据存储有了
与
,为什么还要额弄一个
0
呢?
1
使用列式存储格式
"2"$
,适合离线分析,不支持单条记录级别的
操作,随机读写能力差
:可以进行高效读写,却并不是适合基于
3
的数据分析方向,大批量数据获取的性能差。
01
正因为
与
有上面这些缺点,
0
较好的解决了
与
的这些特点,它
不及
批处理快,也不及
随机读写能力强,但反过来它比
批处理快
2
而且比
随
of 38
5墨值下载
【版权声明】本文为墨天轮用户原创内容,转载时必须标注文档的来源(墨天轮),文档链接,文档作者等基本信息,否则作者和墨天轮有权追究责任。如果您发现墨天轮中有涉嫌抄袭或者侵权的内容,欢迎发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
下载排行榜

评论