




巨杉数据库-P6SparkSQL实例管理.pdf
免费下载
6.1SparkSQL 实例创建与使用
课程介绍
本课程将带领您在已经部署 SequoiaDB 巨杉数据库引擎及创建了 MySQL 实例的环境中,进行 SparkSQL 实例的安
装部署并启动 Spark Thrift Server 服务使用 Beeline 客户端进行数据操作。
SparkSQL 简介
SparkSQL 是 Spark 产品中一个组成部分,SQL 的执行引擎使用 Spark 的 RDD 和 Dataframe 实现。目前 SparkSQL
已经可以完整运行 TPC-DS99 测试,标志着 SparkSQL 在数据分析和数据处理场景上技术进一步成熟。SequoiaDB
巨杉数据库为 Spark 开发了 SequoiaDB for Spark 的连接器,让 Spark 支持从 SequoiaDB 中并发获取数据,再完成
相应的数据计算。
Spark Thrift Server 介绍
Spark Thrift Server 是 Spark 社区基于 HiveServer2 实现的一个 Thrift 服务,旨在无缝兼容 HiveServer2。
Spark Thrift Server 的接口和协议都和 HiveServer2 完全一致,因此部署好 Spark Thrift Server 后,可以直接使用
hive 的 beeline 客户端访问 Spark Thrift Server 执行相关语句。
请点击右侧选择使用的实验环境
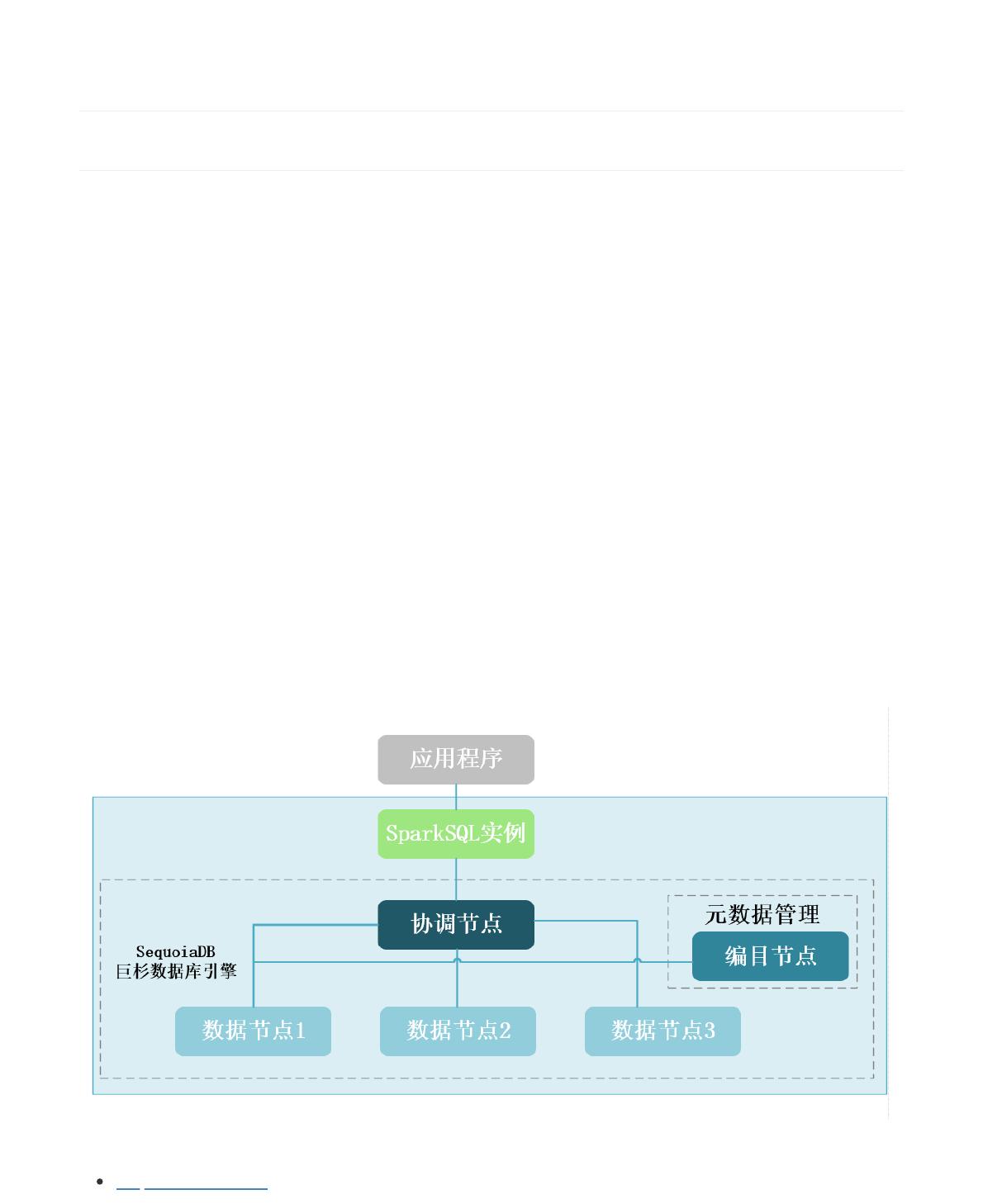
部署架构:
本课程中 SequoiaDB 巨杉数据库的集群拓扑结构为三分区单副本,其中包括:1 个 SparkSQL 实例节点, 1 个引擎
协调节点, 1 个编目节点与 3 个数据节点。
详细了解 SequoiaDB 巨杉数据库系统架构:
SequoiaDB 系统架构
实验环境
课程使用的实验环境为 Ubuntu Linux 16.04 64 位版本;SequoiaDB 巨杉数据库引擎、SequoiaSQL-MySQL 实例和
SequoiaDB-Spark 连接组件均为 3.4 版本;SparkSQL 版本为 2.4.4;JDK 版本为 openjdk1.8。
切换用户及查看数据库版本
切换到系统用户 sdbadmin,并查看 SequoiaDB 巨杉数据库引擎的版本。
切换到 sdbadmin 用户
部署 SequoiaDB 巨杉数据库和 SequoiaSQL-MySQL 实例的操作系统用户为 sdbadmin。
su - sdbadmin
Note:
用户 sdbadmin 的密码为 sdbadmin 。
查看巨杉数据库版本
查看 SequoiaDB 巨杉数据库引擎版本:
sequoiadb --version
操作截图:
查看节点启动列表
查看 SequoiaDB 巨杉数据库引擎节点列表:
sdblist
操作截图:
Note:
of 51
免费下载
【版权声明】本文为墨天轮用户原创内容,转载时必须标注文档的来源(墨天轮),文档链接,文档作者等基本信息,否则作者和墨天轮有权追究责任。如果您发现墨天轮中有涉嫌抄袭或者侵权的内容,欢迎发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
下载排行榜

评论