




Attention Is All You Need 中文翻译.pdf
免费下载

________________________________________________________________________________________________________________________________
Attention Is All You Need
________________________________________________
Ashish Vaswani
Google Brain
avaswani@google.com
Noam Shazeer*
Google Brain
noam@google.com
Niki Parmar*
Google Research
nikip@google.com
Jakob Uszkoreit*
Google Research
usz@google.com
Llion Jones*
Google Research
llion@google.com
Aidan N. Gomez*
University of Toronto
aidan@cs.toronto.edu
Łukasz Kaiser*
Google Brain
lukaszkaiser@google.com
Illia Polosukhin*
illia.polosukhin@gmail.com
第31届神经网络信息处理系统会议(NIPS 2017),美国加州长滩市。
摘要
主流序列转导模型基于复杂的循环神经网络或卷积神经网络,这些神经网络包含一个编码器
和一个解码器。 性能最好的模型还通过attention机制将编码器和解码器连接起来。 我们提
出一种新的简单的网络架构Transformer,仅基于attention机制并完全避免循环和卷积。 对
两个机器翻译任务的实验表明,这些模型在质量上更加优越、并行性更好并且需要的训练时
间显著减少。 我们的模型在WMT 2014英语-德语翻译任务上达到28.4 BLEU,超过现有最
佳结果(包括整合模型)2个BLEU。 在WMT 2014英语-法语翻译任务中,我们的模型建立
了单模型新的最先进的BLEU分数41.8,它在8个GPU上训练了3.5天,这个时间只是目前文
献中记载的最好的模型训练成本的一小部分。 通过在解析大量训练数据和有限训练数据的两
种情况下将其应用到English constituency,我们表明Transformer可以很好地推广到其他
任务。
1 简介
在序列建模和转换问题中,如语言建模和机器翻译[35, 2, 5],循环神经网络特别是长短期记忆[13]和门控循
环[7]神经网络,已经被确立为最先进的方法。 自那以后,许多努力一直在推动循环语言模型和编码器-解码
器架构的界限[38, 24, 15]。
循环模型通常是对输入和输出序列的符号位置进行因子计算。 通过在计算期间将位置与步骤对齐,它们根
据前一步的隐藏状态
-1
和输入产生位置 的隐藏状态序列 。这种固有的顺序特性阻碍样本训练的并行化,
这在更长的序列长度上变得至关重要,因为有限的内存限制样本的批次大小。 最近的工作通过巧妙的因子
分解[21]和条件计算[32]在计算效率方面取得重大进展,后者还同时提高了模型性能。 然而,顺序计算的基
本约束依然存在。
在各种任务中,attention机制已经成为序列建模和转导模型不可或缺的一部分,它可以建模依赖关系而不
考虑其在输入或输出序列中的距离[2, 19]。 除少数情况外[27],这种attention机制都与循环网络一起使
用。
在这项工作中我们提出Transformer,这种模型架构避免循环并完全依赖于attention机制来绘制输入和输
出之间的全局依赖关系。 Transformer允许进行更多的并行化,并且可以在八个P100 GPU上接受少至十二
小时的训练后达到翻译质量的新的最佳结果。
2 背景
减少顺序计算的目标也构成扩展的神经网络GPU [16]、ByteNet [18]和ConvS2S [9]的基础,它们都使用卷
积神经网络作为基本构建模块、并行计算所有输入和输出位置的隐藏表示。 在这些模型中,关联任意两个
输入和输出位置的信号所需的操作次数会随着位置之间的距离而增加,ConvS2S是线性增加,而ByteNet
是对数增加。 这使得学习远距离位置之间的依赖关系变得更加困难[12]。 在Transformer中,这中操作减
少到固定的次数,尽管由于对用attention权重化的位置取平均降低了效果,但是我使用Multi-Head
Attention进行抵消,具体描述见 3.2。
Self-attention,有时称为intra-attention,是一种attention机制,它关联单个序列的不同位置以计算序列
的表示。 Self-attention已成功用于各种任务,包括阅读理解、摘要概括、文本蕴涵和学习与任务无关的句
子表征[4, 27, 28, 22]。
端到端的内存网络基于循环attention机制,而不是序列对齐的循环,并且已被证明在简单语言的问题回答
和语言建模任务中表现良好[34]。
然而,就我们所知,Transformer是第一个完全依靠self-attention来计算输入和输出表示而不使用序列对
齐RNN或卷积的转导模型。 在下面的章节中,我们将描述Transformer、引出self-attention并讨论它相对
[17, 18]和[9]几个模型的优势。
3 模型架构
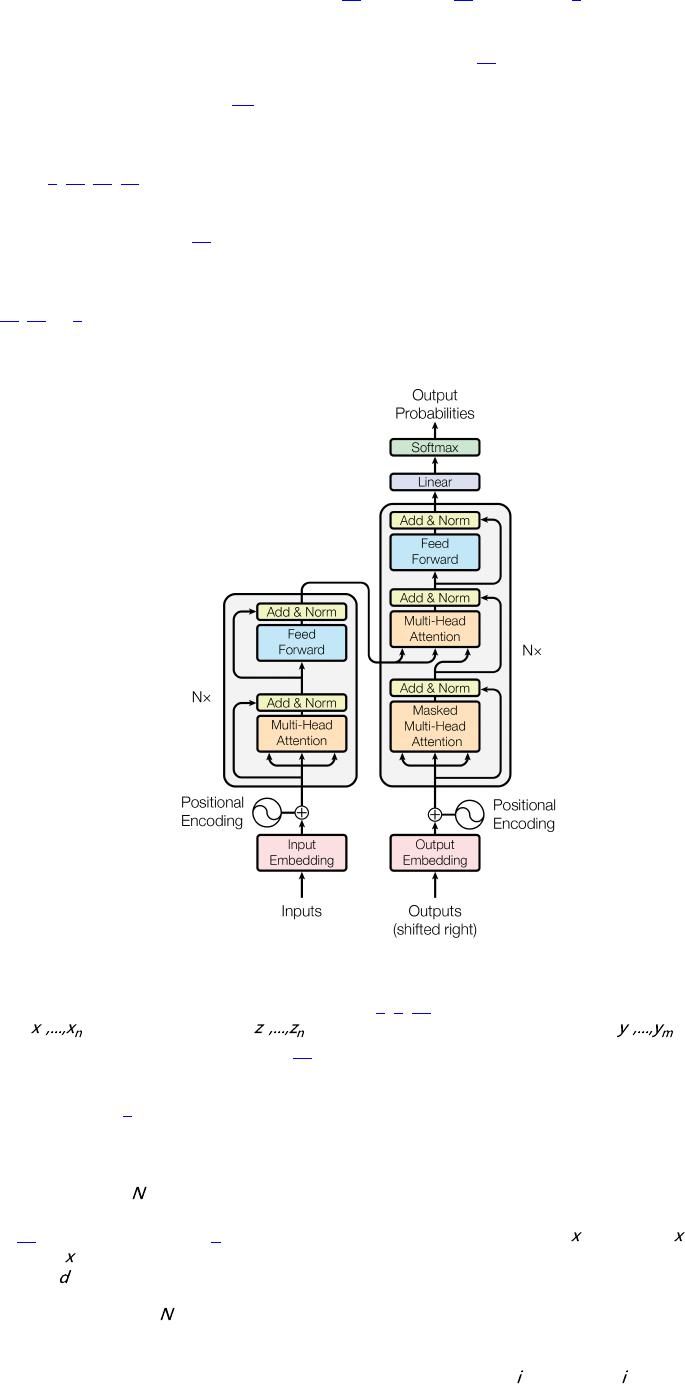
图1: Transformer — 模型架构。
大部分神经序列转导模型都有一个编码器-解码器结构[5, 2, 35]。 这里,编码器映射一个用符号表示的输入
序列(
1
) 到一个连续的表示z = (
1
)。 根据z,解码器生成符号的一个输出序列(
1
) ,一次一
个元素。 在每一步中,模型都是自回归的[10],当生成下一个时,消耗先前生成的符号作为附加输入。
Transformer遵循这种整体架构,编码器和解码器都使用self-attention堆叠和point-wise、完全连接的
层,分别显示在图1的左边和右边。
3.1 编码器和解码器堆栈
编码器: 编码器由 = 6 个完全相同的层堆叠而成。 每一层都有两个子层。 第一层是一个multi-head
self-attention机制,第二层是一个简单的、位置完全连接的前馈网络。 我们对每个子层再采用一个残差连
接[11] ,接着进行层标准化[1]。 也就是说,每个子层的输出是LayerNorm( + Sublayer( )), 其 中
Sublayer( ) 是由子层本身实现的函数。 为了方便这些残差连接,模型中的所有子层以及嵌入层产生的输出
维度都为 model = 512。
解码器: 解码器同样由 = 6 个完全相同的层堆叠而成。 除了每个编码器层中的两个子层之外,解码器还
插入第三个子层,该层对编码器堆栈的输出执行multi-head attention。 与编码器类似,我们在每个子层
再采用残差连接,然后进行层标准化。 我们还修改解码器堆栈中的self-attention子层,以防止位置关注到
后面的位置。 这种掩码结合将输出嵌入偏移一个位置,确保对位置的预测 只能依赖小于 的已知输出。
of 11
免费下载
【版权声明】本文为墨天轮用户原创内容,转载时必须标注文档的来源(墨天轮),文档链接,文档作者等基本信息,否则作者和墨天轮有权追究责任。如果您发现墨天轮中有涉嫌抄袭或者侵权的内容,欢迎发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
下载排行榜

评论