




Apache IoTDB Time-Series Database For Internet Of Things.pdf
免费下载

Apache IoTDB: Time-series Database for Internet of Things
Chen Wang
1,2
, Xiangdong Huang
1∗
, Jialin Qiao
1
, Tian Jiang
1
, Lei Rui
1
, Jinrui Zhang
3
, Rong Kang
1
,
Julian Feinauer
4
, Kevin A. McGrail
5
, Peng Wang
6
, Diaohan Luo
1
, Jun Yuan
1
, Jianmin Wang
1
,
Jiaguang Sun
1
1
School of Software, Tsinghua University,
2
EIRI, Tsinghua University,
3
Microsoft,
4
Pragmatic Industries GmbH,
5
InfraShield.com,
6
Fudan University
huangxdong@tsinghua.edu.cn
ABSTRACT
The amount of time-series data that is generated has exploded due
to the growing popularity of Internet of Things (IoT) devices and
applications. These applications require efficient management of the
time-series data on both the edge and cloud side that support high
throughput ingestion, low latency query and advanced time series
analysis. In this demonstration, we present Apache IoTDB managing
time-series data to enable new classes of IoT applications. IoTDB
has both edge and cloud versions, provides an optimized columnar
file format for efficient time-series data storage, and time-series data-
base with high ingestion rate, low latency queries and data analysis
support. It is specially optimized for time-series oriented operations
like aggregations query, down-sampling and sub-sequence similarity
search. An edge-to-cloud time-series data management application
is chosen to demonstrate how IoTDB handles time-series data in real-
time and supports advanced analytics by integrating with Hadoop
and Spark. An end-to-end IoT data management solution is shown
by integrating IoTDB with PLC4x, Calcite, and Grafana.
PVLDB Reference Format:
Chen Wang
1,2
, Xiangdong Huang
1∗
, Jialin Qiao
1
, Tian Jiang
1
, Lei Rui
1
,
Jinrui Zhang
3
, Rong Kang
1
, Julian Feinauer
4
, Kevin A. McGrail
5
, Peng
Wang
6
, Diaohan Luo
1
, Jun Yuan
1
, Jianmin Wang
1
, Jiaguang Sun
1
. Apache
IoTDB: Time-series Database for Internet of Things. PVLDB, 13(12): 2901 -
2904, 2020.
doi:10.14778/3415478.3415504
1 INTRODUCTION
Nowadays, IoT applications are becoming increasingly popular in
many areas. Examples can be found in consumer electronics in-
cluding smart home devices, wearables and connected healthcare
as well as in industrial applications with the rise of Industrial IoT
(IIoT). Compared to traditional time-series usage for IT such as
infrastructure monitoring, the major characteristics of these IoT ap-
plications are real-time data management with lower latency and
more advanced analytics on the time-series datasets. Furthermore,
when IoT is used in industrial applications, intelligent equipment
usually produces one to two orders of magnitude more data than
consumer-oriented IoT devices. This makes it even harder for ana-
lytics to produce valuable insights in a reasonable amount of time.
This work is licensed under the Creative Commons BY-NC-ND 4.0 International
License. Visit https://creativecommons.org/licenses/by-nc-nd/4.0/ to view a copy of
this license. For any use beyond those covered by this license, obtain permission by
emailing info@vldb.org. Copyright is held by the owner/author(s). Publication rights
licensed to the VLDB Endowment.
Proceedings of the VLDB Endowment, Vol. 13, No. 12 ISSN 2150-8097.
doi:10.14778/3415478.3415504
As an illustrative example, a single wind turbine can generate hun-
dreds of data points every 20 ms [
7
] to monitor conditions, detect
faults and make decisions. Future operations can then be decided
by a set of sophisticated queries against the acquired time-series by
data scientists. Typical uses are signal decomposition and filtration,
segmentation for different working conditions, and failure pattern
matching.
Consequently, the IoT-related service market has spawned new
workloads on time-series processing blended by:
Edge computing
: As edge devices have gained more computa-
tional power and edge computing has grown more popular, managing
time-series data and supporting advanced analysis on the edge side is
trending. It requires the time-series database to be capable of running
on both edge and cloud side, while remaining well organized for
data synchronization.
Long-life, large volume historical data
: The volume of data
in IIoT is large. For example, the sensors on a Boeing model 787
airliner produce upwards of half a terabyte of data per flight [
8
].
Compared with data center monitoring applications where the data
is kept for a week or month, industrial users usually choose to keep
all historical data for audit and statistical analysis of the whole life
cycle of devices.
High throughput data ingestion
: As illustrated in the wind tur-
bine example, the database needs to handle the ingestion of tens of
millions of time-series data points per second stably in a 24
×7×
365
manner. It becomes more challenging when the arrival of time-series
data cannot be guaranteed to be in order due to various device and
network problems including device failure, weak communication
signal or network congestion.
Low latency and complex queries
: Queries are typically used in
three scenarios. (1) The value of the latest data point is required for
real-time monitoring with a short on boarding interval. (2) Applica-
tions, like those for fault detection, regularly retrieve time-series data
having a timestamp or time window filter for given time-series IDs,
and the results are ordered by time. (3) The interactive, exploratory
queries by data scientists are more complicated and unpredictable,
where conditions on value and similarity of sub-sequence are applied
on arbitrary lengths of historical time-series.
Advanced data analytics
: Besides queries, advanced IoT data
analytics like signal processing and machine learning algorithms
are also necessary for data scientists to process the historical data.
However, the support by big data ecosystems such as Apache Spark
requires ETL from time-series database and keeping two costly
copies of huge historical data respectively.
Time-series databases, like OpenTSDB [
9
] and KairosDB [
2
], are
built on top of existing NoSQL stores but suffer from insufficient
2901
Chen Wang
1,2
, Xiangdong Huang
1∗
, Jialin Qiao
1
, Tian Jiang
1
, Lei Rui
1
, Jinrui Zhang
3
, Rong Kang
1
, Julian Feinauer
4
, Kevin A. McGrail
5
, Peng Wang
6
, Diaohan Luo
1
,
Jun Yuan
1
, Jianmin Wang
1
, Jiaguang Sun
1
Spark
Adaptor
series
register
PLC data
MQTT etc..
TsFile TsFile
Edge-side IoTDB TsFile LibPLC Controller
IoT Devices
Cluster Engine
Query Engine
Index
Manager
Data Reader Manager
Cache
Manager
TsFile
O3-
TsFile
D-File
Index
File
Storage Engine
Time
Detector
Ordered Memtable
Out-of-order Memtable
File Sync
Raft Protocol
Series-based
Partitioner
Single-node IoTDB
Time-based
Partitioner
Metadata Management
Schema
Management
TsFile
Hive
Adaptor
Hadoop
Eco-
systems
Restful
APi
JDBC
+
SQL-like
Language
Native
API
Client
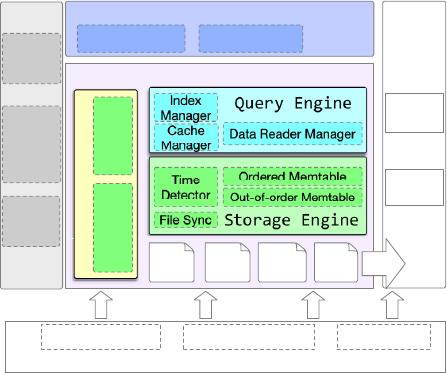
Figure 1: Main modules of IoTDB
performance and poor compression for IoT workloads. InfluxDB
has about 10x improvements on these aspects [
5
], but still has a gap
on query performance especially when aggregating large amounts of
historical data. In practice, Parquet [
3
] is the choice for time-series
storage for analytics and OLAP workloads with Hadoop ecosystem,
but it requires ETL from the time-series database. Moreover, opti-
mization is needed to support native time-series data for both storage
and query efficiency beyond columnar storage.
In this demo, we introduce Apache IoTDB [
1
], a native time-series
storage format and database for both edge and cloud computing. It
has the following key features: (1) IoTDB has a lightweight archi-
tecture running on the edge appliances, and a cluster version for
the data center under the same code base, as well as efficient data
synchronization from edge to cloud. (2) IoTDB provides a novel
columnar file format, called TsFile (Time-series File), as the main
storage format to optimize the data organization, size reduction, and
query performance with time-series data. (3) IoTDB supports high
throughput ingestion by an elaborate buffering design and storage
strategy to handle frequent out-of-order data ingestion and sorted
data query. (4) IoTDB leverages metadata in TsFiles and index files
to support low latency queries and complex similarity search. (5)
TsFile, as the file format of IoTDB, can also be accessed directly in
Hadoop ecosystem by Spark and Hive for data analysis.
Currently, IoTDB supports the ingestion rate up to 30 million
data points per second on a single node, and the latency of hundreds
of milliseconds for raw data queries and tens of milliseconds for
aggregation queries on billions of data points. A more comprehensive
functional and experimental evaluation can be accessed in public [
4
].
IoTDB has been deployed in the production environment by several
industry users.
2 SYSTEM OVERVIEW
The architecture of IoTDB is shown in Figure 1. IoTDB is designed
to manage huge volumes of time-series data points from IoT de-
vices, where one data point is logically depicted as (<device, sensor,
timestamp, value>. Herein the device and sensor identifiers together
present a unique time-series ID. The Metadata Management module
manages the naming space of devices with a tree structure. For in-
stance, Location1.Windfarm2.Manufactuer3.Turbine4 is a full path
to describe a single wind turbine. The design of IoTDB chooses
to store the data in an open native time-series file format for both
database access with Query/Storage Engine and Hadoop/Spark ac-
cess against a single copy of the data. It also serves as a distributed
time-series database, where data is partitioned by grouping of time-
series in Cluster Engine among different nodes while time-based
data slicing is implemented on each node to improve the perfor-
mances. IoTDB provides an SQL-like language, native API, and
restful API to access the data. We then introduce the main features
in the following subsections.
2.1 Uniform Edge-Cloud Design
In IoT scenario, edge computing and cloud side deployment are
equally important. Therefore, IoTDB is designed to fit three deploy-
ment models: 1) file-based storage or embedded time-series database
on edge appliance like Raspberry PI, 2) standalone time-series data-
base on Industrial PC and 3) distributed time-series database or
Hadoop cluster with TsFile storage format.
Typically, IoT devices collect data from sensors and industrial
controllers, and send data to data center using customized or stan-
dard protocols like MQTT in real-time. However, in some cases, the
edge intelligence requires real-time analytics, such as fault alerts,
to retrieve data from a local data store. Therefore, IoTDB has a
lightweight, embedded version to be deployed on the IoT devices,
where the minimal runtime memory requirement is 32MB and com-
putation is supported with an ARM7 processor. Local storage is also
mandatory to prevent data loss in case of the temporary network
outage. In this scenario, TsFile Lib allows the devices to persist
data in TsFile format, and afterwards the generated TsFiles can be
directly synchronized and merged with active IoTDB instance on
the cloud using the File Sync module.
On the cloud side, using the Cluster Engine, a raft-based protocol
is implemented to manage multiple IoTDB nodes. In the cluster
mode, data partitions can be defined according to both time slice
and time-series ID. The distribution of data and query operations are
completely transparent to the end users.
2.2 TsFile Format
TsFile is the primary data file format for time-series data storage
in IoTDB. Figure 2 shows the structure of the TsFile. TsFile is
similar to Parquet but optimized for time-series data. A TsFile mainly
consists of two parts: the data content (Chunks, Pages) and the
index. Each chunk stores the data of a time-series for a certain time
range. Inside a chunk, the data is split into several pages, which
is the fundamental unit of the data storage on the disk. Each page
stores data points in a pair of columns, i.e. the timestamps and the
value. Timestamps are encoded by second order difference and the
value field supports compression algorithms like bitmap, Gorilla,
RLE, etc. to save disk space. Snappy is also employed for advanced
compression on historical data.
To accelerate the query, the data in the chunks of each time-series
is ordered by time in TsFile. In this way, queries with time range
filters can quickly skip the chunks out of the given time window.
2902
of 4
免费下载
【版权声明】本文为墨天轮用户原创内容,转载时必须标注文档的来源(墨天轮),文档链接,文档作者等基本信息,否则作者和墨天轮有权追究责任。如果您发现墨天轮中有涉嫌抄袭或者侵权的内容,欢迎发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
下载排行榜

文档被以下合辑收录
评论