




Toward Interpretable Deep Reinforcement Learning with Linear Model U-Trees.pdf
5墨值下载

【决策树】Toward Interpretable Deep Rei…
1807.05887.pdf
2.1MB
预览
Abstract
Q-function隐含着RL问题的知识,但是不可解释。因此本⽂提出⾸个DRL中Q-function的
模仿学习⽅法Linear Model U-trees (LMUTs)
1. Introduction
现在已有很多⽅法把深度模型蒸馏为决策树[5,2,7],但他们都是基于监督的⽅法,⽽强化学
习是⽆监督的,所以不适⽤。
贡献1
提出了新颖的强化学习模仿学习框架,包含在线和离线两个⽅法:
Experience Training:记录DRL训练过程中的所有(s,a)数据对,以Q值作为软标签。
Active Play:离线的数据量⼤,很耗时,因此提出在线⽅法进⾏动态更新。
贡献2
提出Linear Model U-Tree (LMUT)
U-tree [13,20] 是⼀个经典的在线强化学习⽅法,使⽤树结构表达Q-function。⽂章改进
了U-tree⽅法,在每个叶节点下增加了⼀个线性函数,提出Linear Model U-Tree (LMUT),⽤
来产⽣连续的Q值。
评估⽅法
3个基准环境,5个baseline⽅法
fidelity
play performance
...
2. Related Works
Reinforcement Learning and the Q-function
Mimic Learning
U-Tree Learning
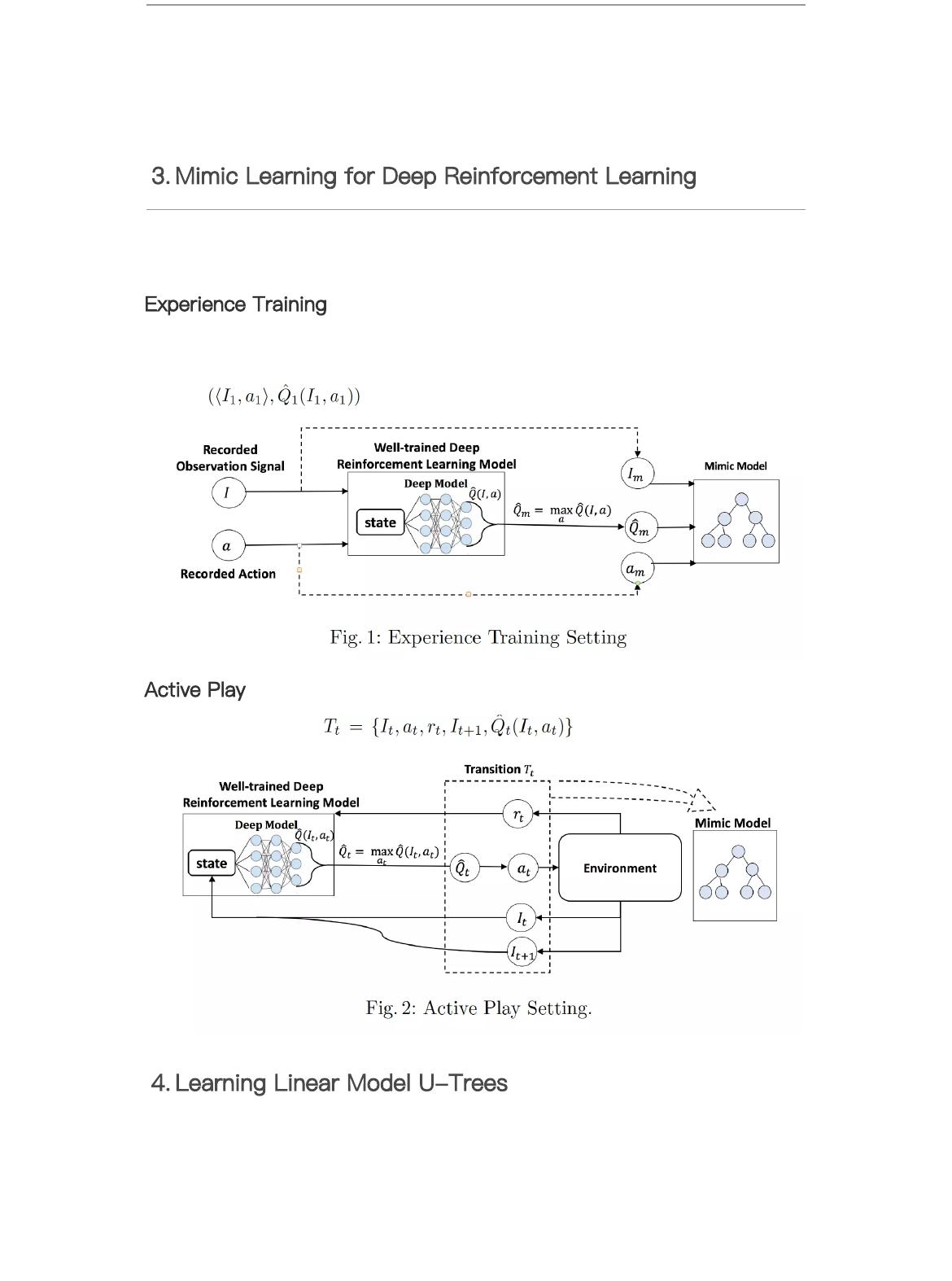
3. Mimic Learning for Deep Reinforcement Learning
提出了新颖的强化学习模仿学习框架,包含在线和离线两个⽅法
Experience Training
⽣成数据,进⾏批训练。
⾸先,记录下XRL过程中所有的观察和动作,然后,将观察输⼊到成熟的DRL模型中获得Q
值,获得 作为训练数据。
Active Play
从每⼀步迭代中获得 ,进⾏在线更新
4. Learning Linear Model U-Trees
of 3
5墨值下载
【版权声明】本文为墨天轮用户原创内容,转载时必须标注文档的来源(墨天轮),文档链接,文档作者等基本信息,否则作者和墨天轮有权追究责任。如果您发现墨天轮中有涉嫌抄袭或者侵权的内容,欢迎发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
下载排行榜

评论