




OceanBase 数据库系统概念之七.pdf
免费下载
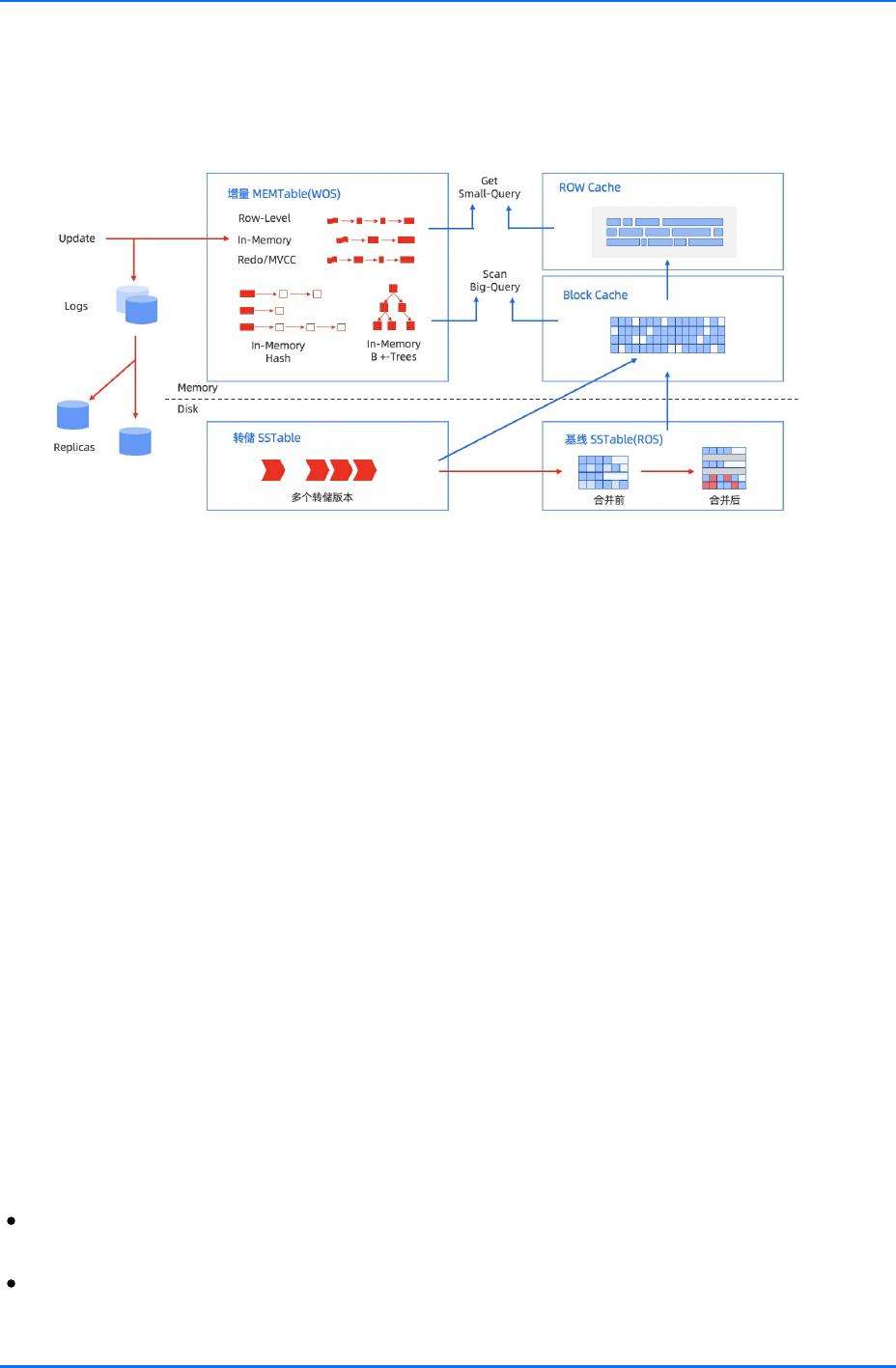
OceanBase 数据库的存储引擎基于 LSM Tree 架构,将数据分为静态基线数据(放在 SSTable 中)和动态增
量数据(放在 MemTable 中)两部分,其中 SSTable 是只读的,一旦生成就不再被修改,存储于磁盘;
MemTable 支持读写,存储于内存。数据库 DML 操作插入、更新、删除等首先写入 MemTable,等到
MemTable 达到一定大小时转储到磁盘成为 SSTable。在进行查询时,需要分别对 SSTable 和 MemTable
进行查询,并将查询结果进行归并,返回给 SQL 层归并后的查询结果。同时在内存实现了 Block Cache 和
Row cache,来避免对基线数据的随机读。
当内存的增量数据达到一定规模的时候,会触发增量数据和基线数据的合并,把增量数据落盘。同时每天晚
上的空闲时刻,系统也会自动每日合并。
OceanBase 数据库本质上是一个基线加增量的存储引擎,在保持 LSM-Tree 架构优点的同时也借鉴了部分传
统关系数据库存储引擎的优点。
传统数据库把数据分成很多页面,OceanBase 数据库也借鉴了传统数据库的思想,把数据文件按照 2MB 为
基本粒度切分多一个个宏块, 每个宏块内部继续拆分多多个变长的微块; 而在合并时数据会基于宏块的粒度进
行重用, 没有更新的数据宏块不会被重新打开读取, 这样能够尽可能减少合并期间的写放大, 相较于传统的
LSM-Tree 架构数据库显著降低合并代价。另外,OceanBase 数据库通过轮转合并的机制把正常服务和合并
时间错开,使得合并操作对正常用户请求完全没有干扰。
由于 OceanBase 数据库采用基线加增量的设计,一部分数据在基线,一部分在增量,原理上每次查询都是
既要读基线,也要读增量。为此,OceanBase 数据库做了很多的优化,尤其是针对单行的优化。OceanBase
数据库内部除了对数据块进行缓存之外,也会对行进行缓存,行缓存会极大加速对单行的查询性能。对于不
存在行的“空查”,我们会构建布隆过滤器,并对布隆过滤器进行缓存。OLTP 业务大部分操作为小查询,
通过小查询优化,OceanBase 数据库避免了传统数据库解析整个数据块的开销,达到了接近内存数据库的性
能。另外,由于基线是只读数据,而且内部采用连续存储的方式,OceanBase 数据库可以采用比较激进的压
缩算法,既能做到高压缩比,又不影响查询性能,大大降低了成本。
结合借鉴经典数据库的部分优点,OceanBase 数据库提供了一个更为通用的 LSM-tree 架构的关系型数据库
存储引擎, 具备以下特性:
低成本,利用 LSM-tree 写入数据不再更新的特点, 通过自研行列混合编码叠加通用压缩算法, OceanBase
数据库的数据存储压缩率能够相较传统数据库提升 10+ 倍。
易使用,不同于其他 LSM-tree 数据库,OceanBase 数据库通过支持活跃事务的落盘保证用户的大事务/
长事务的正常运行或回滚,多级合并和转储机制来帮助用户在性能和空间上找到更佳的平衡。
8.存储架构8.存储架构
8.1. 存储架构概述8.1. 存储架构概述
OceanBase 数据库 存储架构
> 文档版本:20220304 304

高性能,对于常见的点查,OceanBase 数据库提供了多级 cache 加速来保证极低的响应延时,而对于范
围扫描,存储引擎能够利用数据编码特征支持查询过滤条件的计算下压,并提供原生的向量化支持。
高可靠,除了全链路的数据检验之外,利用原生分布式的优势,OceanBase 数据库还会在全局合并时通过
多副本比对以及主表和索引表比对的校验来保证用户数据正确性,同时提供后台线程定期扫描规避静默错
误。
存储引擎的功能存储引擎的功能
从功能模块划分上,OceanBase 数据库存储引擎可以大致分为以下几个部分。
数据存储数据存储
数据组织
和其他 LSM-tree 数据库一样,OceanBase 数据库也将数据分为内存增量数据(MemTable)和存储静态
数据(SSTable)两个层次,其中 SSTable 是只读的,一旦生成就不再被修改,存储于磁盘;MEMTable
支持读写,存储于内存。数据库 DML 操作插入、更新、删除等首先写入 MEMTable,等到 MEMTable 达
到一定大小时转储到磁盘成为 SSTable。
另外在 OceanBase 数据库内,SSTable 会继续细分为 Mini SSTable、Minor SSTable、Major SSTable 三
类,MEMTable 转储后形成的我们称为 Mini SSTable,多个 Mini SSTable 会定期 compact 成为 Minor
SSTable,而当 OceanBase 数据库特有的每日合并开始后,每个分区所有的 Mini SSTable 和 Minor
SSTable 会整体合并为 Major SSTable。
存储结构
在 OceanBase 数据库中, 每个分区的基本存储单元是一个个的 SSTable,而所有存储的基本粒度是宏块,
数据库启动时,会将整个数据文件按照 2MB 定长大小切分为一个个宏块,每个 SSTable 实质就是多个宏
块的集合。
每个宏块内部又会继续切分为多个微块,微块的概念和传统数据库的 page/block 概念比较类似, 但是借
助 LSM-Tree 的特性,OceanBase 数据库的微块是做过压缩变长的,微块的压缩前大小可以通过建表的时
候指定 block_size 来确定。
而微块根据用户指定存储格式可以分别以 encoding 格式或者 flat 格式存储,encoding 格式的微块, 内部
数据会以行列混合模式存储;对于 flat 格式的微块,所有数据行则是平铺存储。
压缩编码
OceanBase 数据库对于微块内的数据会根据用户表指定的模式分别进行编码和压缩。当用户表打开
encoding 时, 每个微块内的数据会按照列维度分别进行列内的编码,编码规则包括字典/游程/常量/差值
等,每一列压缩结束后,还会进一步对多列进行列间等值/子串等规则编码。编码不仅能帮助用户对数据
进行大幅压缩,同时提炼的列内特征信息还能进一步加速后续的查询速度。
在编码压缩之后,OceanBase 数据库还支持进一步对微块数据使用用户指定的通用压缩算法进行无损压
缩,进一步提升数据压缩率。
转储合并转储合并
转储
OceanBase 数据库中的转储即 Minor Compaction 概念可以理解和其他 LSM-tree 架构数据库的
Compaction 概念类似,主要负责 MEMTable 刷盘转成 SSTable 以及多个 SSTable 之间的 Compaction
策略选择以及动作。OceanBase 数据库中采用的是 leveled 结合 size tired 的 Compaction 策略,大致可
以分为三层,其中 L1 和 L2 就是固定的 leveled 层次,L0 层是 size tired,L0 内部还会继续根据写放大系
数以及 SSTable 个数进行内部 Compaction 动作。
合并
OceanBase 数据库 存储架构
> 文档版本:20220304 305
of 19
免费下载
【版权声明】本文为墨天轮用户原创内容,转载时必须标注文档的来源(墨天轮),文档链接,文档作者等基本信息,否则作者和墨天轮有权追究责任。如果您发现墨天轮中有涉嫌抄袭或者侵权的内容,欢迎发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
下载排行榜

评论