




百度-DuSQL- A Large-Scale and Pragmatic Chinese Text-to-SQL Dataset.pdf
免费下载
Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing, pages 6923–6935,
November 16–20, 2020.
c
2020 Association for Computational Linguistics
6923
DuSQL: A Large-Scale and Pragmatic Chinese Text-to-SQL Dataset
Lijie Wang
1
, Ao Zhang
1
, Kun Wu
2
, Ke Sun
1
, Zhenghua Li
2
,
Hua Wu
1
, Min Zhang
2
, Haifeng Wang
1
1. Baidu Inc, Beijing, China
2. Institute of Artificial Intelligence, School of Computer Science and Technology,
Soochow University, Suzhou, China
{wanglijie,zhangao,sunke,wu_hua,wanghaifeng}@baidu.com
kwu@stu.suda.edu.cn; {zhli13,minzhang}@suda.edu.cn
Abstract
Due to the lack of labeled data, previous re-
search on text-to-SQL parsing mainly focuses
on English. Representative English datasets in-
clude ATIS, WikiSQL, Spider, etc. This paper
presents DuSQL, a larges-scale and pragmatic
Chinese dataset for the cross-domain text-to-
SQL task, containing 200 databases, 813 ta-
bles, and 23,797 question/SQL pairs. Our new
dataset has three major characteristics. First,
by manually analyzing questions from several
representative applications, we try to figure out
the true distribution of SQL queries in real-life
needs. Second, DuSQL contains a consider-
able proportion of SQL queries involving row
or column calculations, motivated by our analy-
sis on the SQL query distributions. Finally, we
adopt an effective data constr uction framework
via human-computer collaboration. The basic
idea is automatically generating SQL queries
based on the SQL grammar and constrained
by the given database. This paper describes in
detail the construction process and data statis-
tics of DuSQL. Moreover, we present and com-
pare performance of several open-source text-
to-SQL parsers with minor modification to ac-
commodate Chinese, including a simple yet ef-
fective extension to IRNet for handling calcula-
tion SQL queries.
1 Introduction
In the past few decades, a large amount of research
has focused on searching answers from unstruc-
tured texts given natural questions, which is also
known as the question answering (QA) task (Burke
et al., 1997; Kwok et al., 2001; Allam and Hag-
gag, 2012; Nguyen et al., 2016). However, a lot of
high-quality knowledge or data are actually stored
in databases in the real world. It is thus extremely
useful to allow ordinary users to directly inter-
act with databases via natural questions. To meet
this need, researchers have proposed the text-to-
SQL task with released English datasets for model
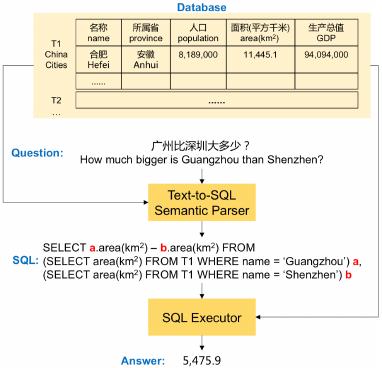
Figure 1: Illustration of the text-to-SQL task.
training and evaluation, such as ATIS (Iyer et al.,
2017), GeoQuery (Popescu et al., 2003), WikiSQL
(Zhong et al., 2017), and Spider (Yu et al., 2018b).
Formally, given a natural language (NL) ques-
tion and a relational database, the text-to-SQL task
aims to produce a legal and executable SQL query
that leads directly to the correct answer, as depicted
in Figure 1. A database is composed of multiple
tables and denoted as DB = {T
1
, T
2
, ..., T
n
}. A ta-
ble is composed of multiple columns and denoted
as T
i
= {col
1
, col
2
, ..., col
m
}. Tables are usually
linked with each other by foreign keys.
The earliest datasets include ATIS (Iyer et al.,
2017) , GeoQuery (Popescu et al., 2003), Restau-
rants (Tang and Mooney, 2001), Academic (Li and
Jagadish, 2014), etc. Each dat aset only has a sin-
gle database containing a certain number of ta-
bles. All question/SQL pairs of train/dev/test sets
are generated against the same database. Many in-
teresting approaches are proposed to handle those
datasets (Iyer et al., 2017; Yaghmazadeh et al.,
2017; Finegan-Dollak et al., 2018).
However, real-world applications usually in-
6924
volve more than one database, and require the
model to be able to generalize to and handle unseen
databases during evaluation. To accommodate this
need, the WikiSQL dataset is then released by
Zhong et al. (2017). It consists of 80,654 ques-
tion/SQL pairs for 24,241 single-table databases.
They propose a new data split setting to ensure that
databases in train/dev/test do not overlap. However,
they focus on very simple SQL queries containing
one SELECT statement with one WHERE clause.
In addition, Sun et al. (2020) released TableQA, a
Chinese dataset similar to the WikiSQL dataset.
Yu et al. (2018b) released a more challenging
Spider dataset, consisting of 10,181 question/SQL
pairs against 200 multi-table databases. Compared
with WikiSQL and TableQA, Spider is much more
complex due to two reasons: 1) the need of select-
ing relevant tables; 2) many nested queries and ad-
vanced SQL clauses like GROUP BY and ORDER
BY.
As far as we know, most existing datasets are
constructed for English. Another issue is that they
do not refer to the question distribution in real-
world applications during data construction. Tak-
ing Spider as an example. Given a database, anno-
tators are asked to write many SQL queries from
scratch. The only requirement is that SQL queries
have to cover a list of SQL clauses and nested
queries. Meanwhile, the annotators write NL ques-
tions corresponding to SQL queries. In particular,
all these datasets contain very few questions involv-
ing calculations between rows or columns, which
we find are very common in real applications.
This paper presents DuSQL, a large-scale and
pragmatic Chinese text-to-SQL dataset, contain-
ing 200 databases, 813 tables, and 23,797 ques-
tion/SQL pairs. Specifically, our contributions are
summarized as follows.
• In order to determine a more realistic distribution
of SQL queries, we collect user questions from
three representative database-oriented applica-
tions and perform manual analysis. In particular,
we find that a considerable proportion of ques-
tions require row/column calculations, which are
not included in existing datasets.
• We adopt an effective data construction frame-
work via human-computer collaboration. The ba-
sic idea is automatically generating SQL queries
based on the SQL grammar and constrained by
the given database. For each SQL query, we first
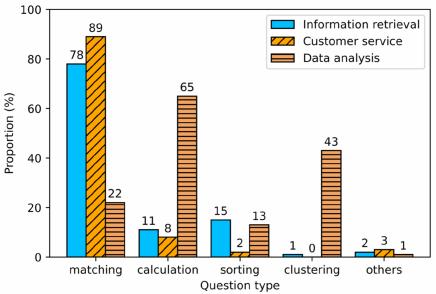
Figure 2: The SQL query distributions of the three ap-
plications. Please kindly note that a query may belong
to multiple types.
generate a pseudo question by traversing it in the
execution order and then ask annotators to para-
phrase it into a NL question.
• We conduct experiments on DuSQL using
three open-source parsing models. In par-
ticular, we extend the state-of-the-art IRNet
(Guo et al., 2019) model to accommodate
the characteristics of DuSQL. Results and
analysis show that DuSQL is a very chal-
lenging dataset. We will release our data at
https://github.com/luge-ai/luge-ai/
tree/master/semantic-parsing.
2 SQL Query Distribution
As far as we know, existing text-to-SQL datasets
mainly consider the complexity of SQL syntax
when creating SQL queries. For example, Wik-
iSQL has only simple SQL queries containing SE-
LECT and WHERE clauses. Spider covers 15 SQL
clauses including SELECT, WHERE, ORDER BY,
GROUP BY, etc, and allows nested queries.
However, to build a pragmatic text-to-SQL sys-
tem that allows ordinary users to directly interact
with databases via NL questions, it is very impor-
tant to know the SQL query distribution in real-
world applications, from the aspect of user need
rather than SQL syntax. Our analysis shows that
Spider mainly covers three types of SQL queries,
i.e., matching, sor ting, and clustering, whereas
WikiSQL only has matching queries. Neither of
them contains the calculation type, which we find
composes a large portion of questions in certain
real-world applications.
To find out the SQL query distribution in real-
life applications, we consider the following three
of 13
免费下载
【版权声明】本文为墨天轮用户原创内容,转载时必须标注文档的来源(墨天轮),文档链接,文档作者等基本信息,否则作者和墨天轮有权追究责任。如果您发现墨天轮中有涉嫌抄袭或者侵权的内容,欢迎发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
下载排行榜

评论