

2019-09-23
关于索引的clustering_factor
请教专家:
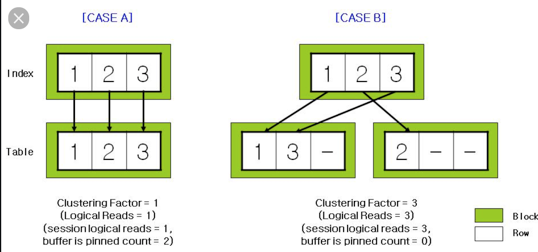
关于dba_indexes视图当中的 clustering_factor字段,表示着基表数据与索引之间数据排列顺序的契合程度。按照理解,clustering_factor的大小越接近基表的block数量就表示排序程度越高,索引效率也越高,如果clustering_factor越接近NUM_ROWS 则表示排序程度越低,索引效率也越低。
请教一下,这个地方NUM_ROWS通常在参考的时候,是参考的dba_indexes 里面的NUM_ROWS 字段,还是参考的dba_tables里面的NUM_ROWS字段,或者是实际 select count(*) from table 得到的结果?
因为dba_indexes里面的NUM_ROWS代表的是索引记录行数,假如索引参考的基表列,存在较多的NULL值的话,它是不会记录的,因此存在索引记录的行数和基表的实际行数有较大差距的问题。而dba_tables 里面的NUM_ROWS 通常是在搜集了统计信息之后才会有数据,但假如数据的自动信息搜集功能被关闭了,这个数据是不是会存在更新不及时的现象?
另外,一般参考范围的话,clustering_factor的值大约占 NUM_ROWS是的百分之多少,表示这个索引或者基表可以纳入重建的考虑范围?(重建索引也不会降低CF值。)
收藏
分享
7条回答
默认
最新
 评论
评论
回答交流
提交
问题信息
请登录之后查看
邀请回答
暂无人订阅该标签,敬请期待~~
 墨值悬赏
墨值悬赏