

 匿名用户
匿名用户GBase8a慢SQL优化
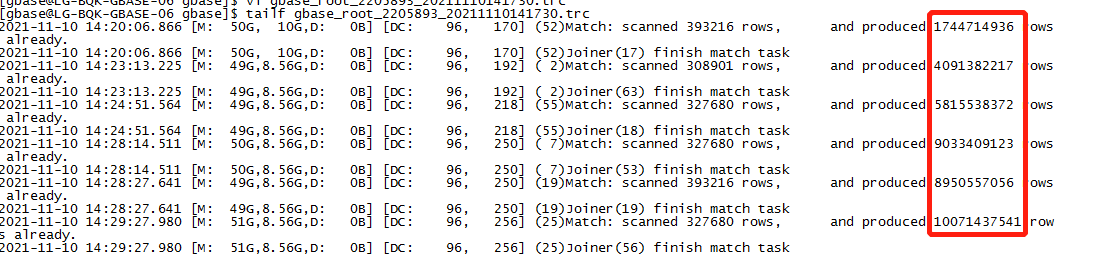
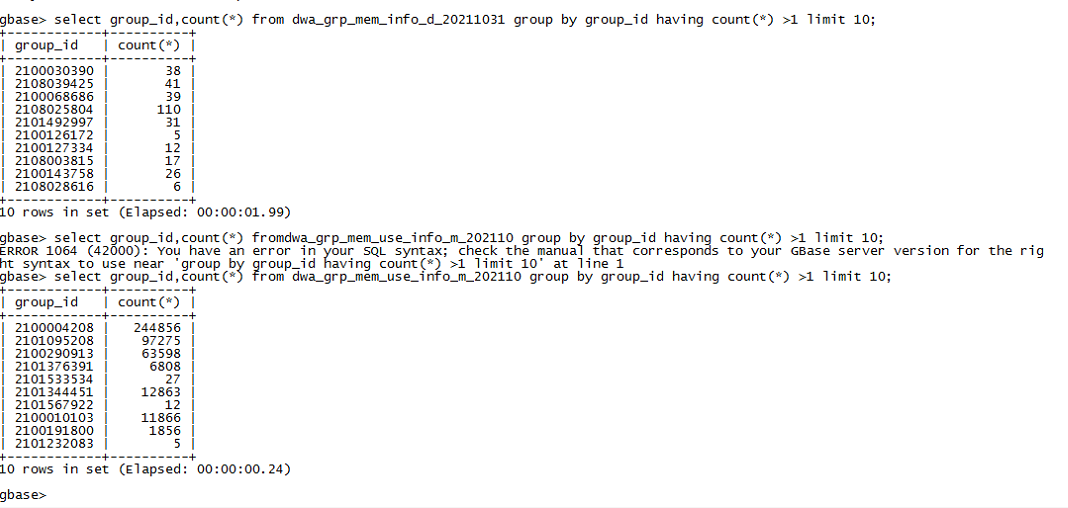
某移动现场一条insert select 语句执行时间超过2小时,需要分析,SQL语句如下:
insert into
tableXXX
select distinct
cast(ct.USER_ID as char) as USER_ID
from database.dwa_grp_mem_info_d_20211031
dgmid
join database.dwa_grp_mem_use_info_m_202110
ct
on cast(ct.GROUP_ID as char) = cast(dgmid.GROUP_ID
as char);
我来答
添加附件
收藏
分享
问题补充
1条回答
默认
最新
 评论
评论
回答交流
提交
问题信息
请登录之后查看
邀请回答
暂无人订阅该标签,敬请期待~~
 墨值悬赏
墨值悬赏