

源端是一套Oracle 19c双节点RAC,只在1节点上部署了到另一个单机Oracle库上的抽取进程,用的集成模式,需要同步400张表,最近频繁出现抽取延迟的问题,不是每天都出现,但是只要出现都是在固定的几个时间段内,目前查到以下信息
1. 延迟时间段内40分钟左右未生成trail file文件,正常情况3分钟左右一个
-rw-r-----. 1 oracle oinstall 48M Aug 10 16:01 IV000416416
-rw-r-----. 1 oracle oinstall 48M Aug 10 16:42 IV000416417
2. 与正常时间段相比,延迟时间段内DB负载明显增高,大概在3倍左右,服务器32cpu,最高时候db time/elapsed time能达到40以上

3.延迟时间段内执行send trace和showtrans均报错OGG-15163
2022-08-10T16:07:26.083+0800 INFO OGG-00987 Oracle GoldenGate Command Interpreter for Oracle: GGSCI command (oracle): send XXX trace XXX_20220810.trc.
2022-08-10T16:08:26.142+0800 ERROR OGG-15163 Oracle GoldenGate Command Interpreter for Oracle: There was a problem sending a message to EXTRACT XXX (Timeout waiting for message).
4.此前以为是长事务导致,现在发现在晚上22点到1点的时间段内出现过01555的报错,但是在下午16~17的时间段未出现
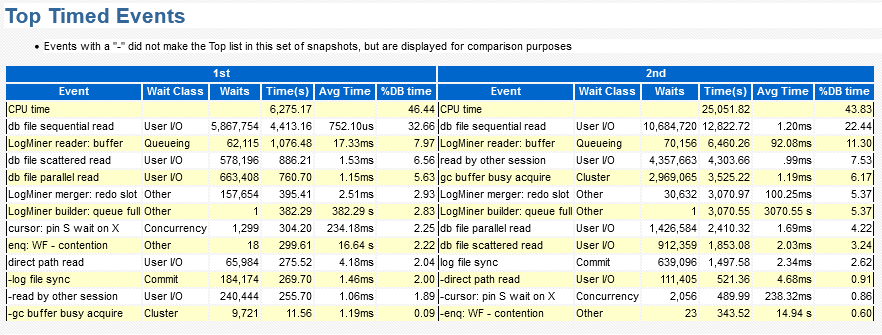
5.等待事件没看到有什么异常
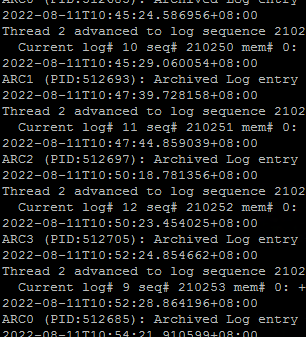
6.alert日志也没看到有什么异常,除了LOGMINER: Begin mining logfile for session这种就是偶尔出现的ORA-00060,不过ORA-00060这个正常时间段也有
7.redo 大小2g,平均每小时生成30个左右
各位大佬有什么排查思路么,谢谢
 评论
评论

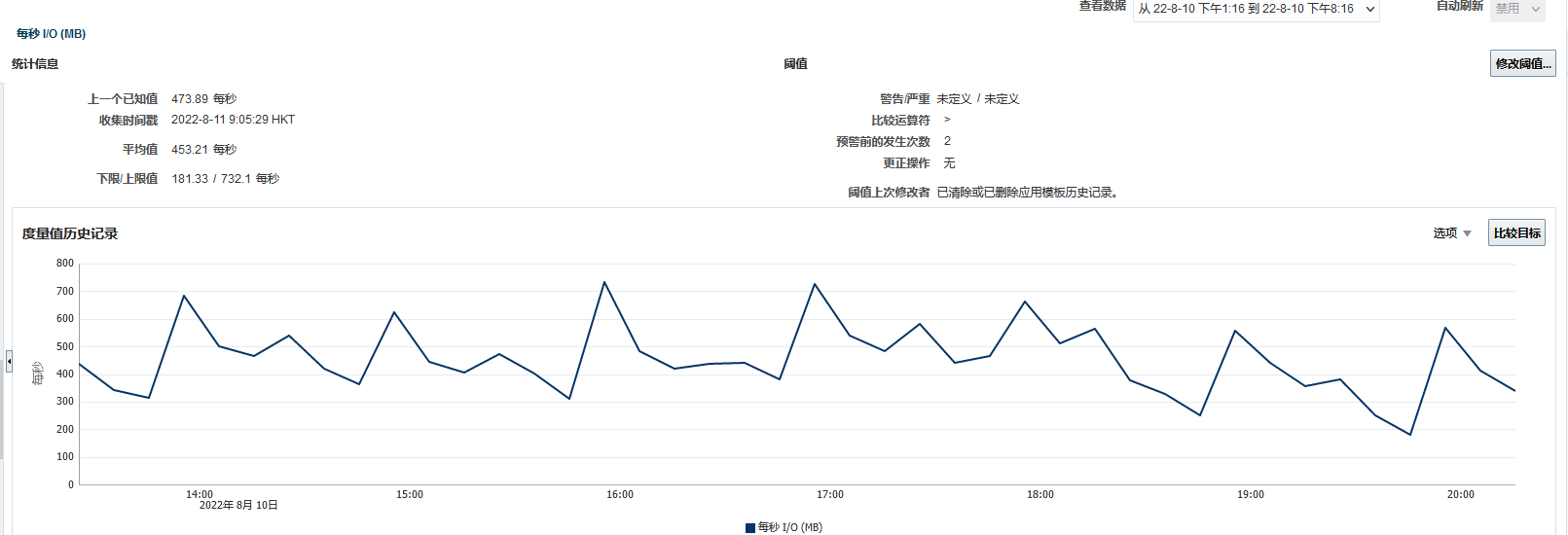 IO感觉没啥明显变化,应该不是网络问题吧,在抽取的时候就出现了延迟
IO感觉没啥明显变化,应该不是网络问题吧,在抽取的时候就出现了延迟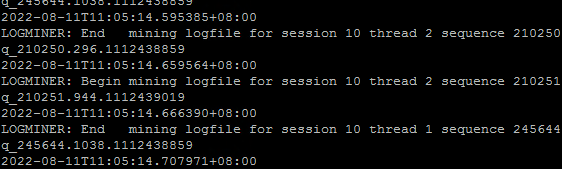
 墨值悬赏
墨值悬赏