
ORACLE RAC 11G 一个节点自动重启
 5M
5M双节点RAC,系统是redhat6.10,今天通过kettle大批量导入数据时发生故障,9点左右db1自动重启,重启后查看集群恢复正常,不知道哪里出现问题,top查看load average都在18左右,不知道正常不正常。
我来答
添加附件
收藏
复制链接
微信扫码分享

在小程序上查看
分享
添加附件
问题补充
8条回答
默认
最新
message文件内,大量的 Abts,ABTS全称为Abort Sequence
通俗的说,主机向存储设备发送IO命令,如果在超时时间内(不同的主机超时时间不一)还没有收到存储设备的响应,主机就会发起ABTS,要求存储中止这个命令执行;同时阵列侧不会有IO的任何信息;因此给主机回复RecvAbts。
原因:
可能是链路不稳,存在误码或者闪断,或者链路质量不良丢帧,需要排查链路
排查方向:
1、存储-----san交换机----hba卡-------物理机整个链条是否兼容,驱动版本和内核是否兼容
2、SAN交换机,存储,HBA卡各种端口模块光衰大小,光纤是否有弯折等等
3、multipath.conf参数是否满足阵列厂商的要求
4、对应时间段内,存储是否有问题
 评论
评论 有用 2
有用 2
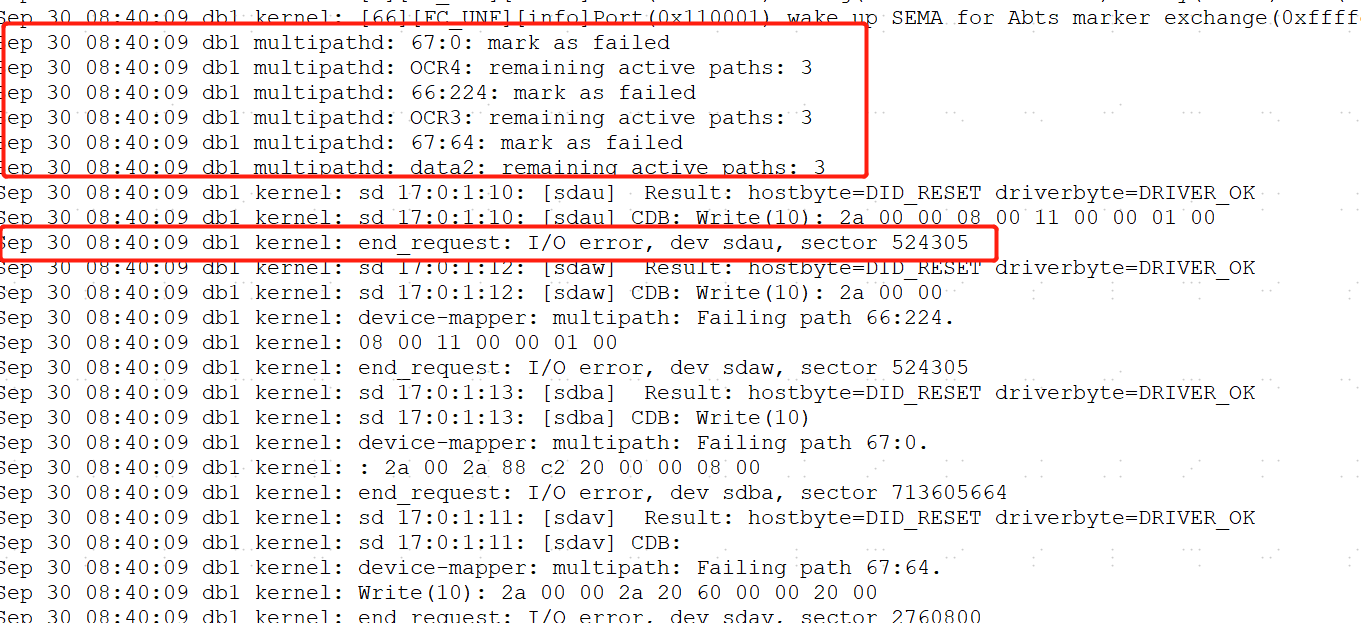
看节点1的/var/log/messages,对应时间段IO是不是有问题了
评论 有用 0看alert日志,从8:38分开始iio心跳就时断时续,

cssd日志:从8:36分开始大量的css的进程无法被调度,这是进程夯了。
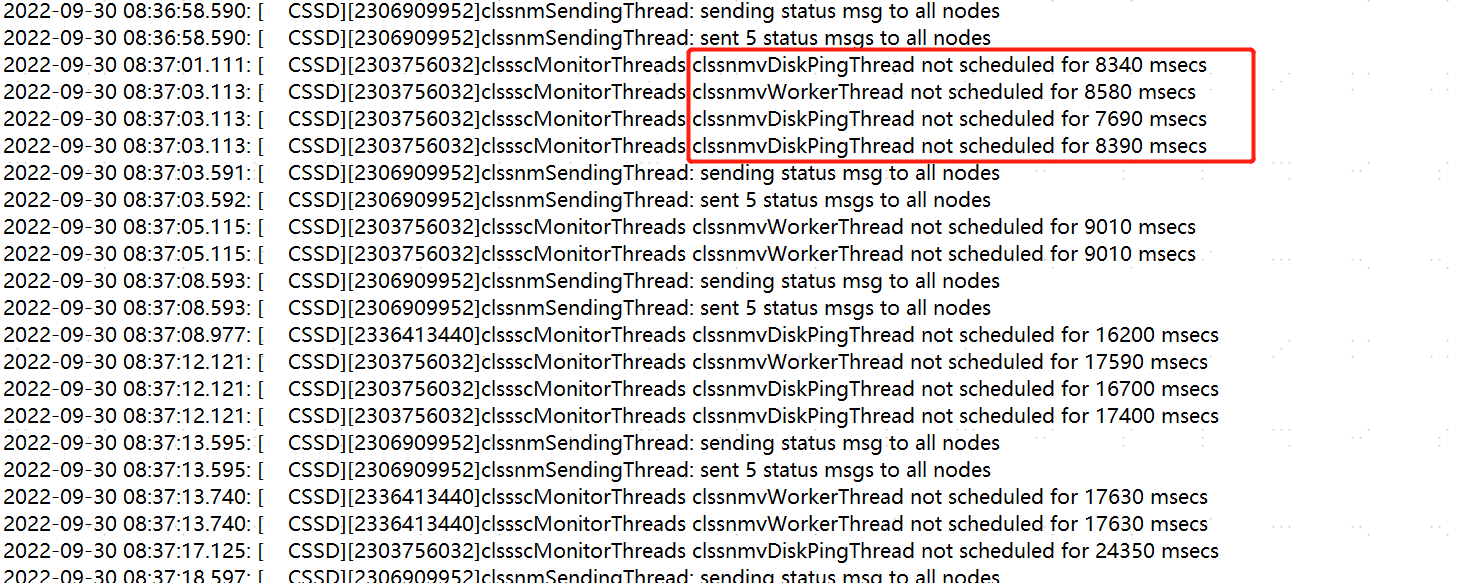
随后出现访问ocr盘的io丢失,最终重启。




8:59分,ocr磁盘全部offline,集群被重启。后面由于同样的原因多次被重启。
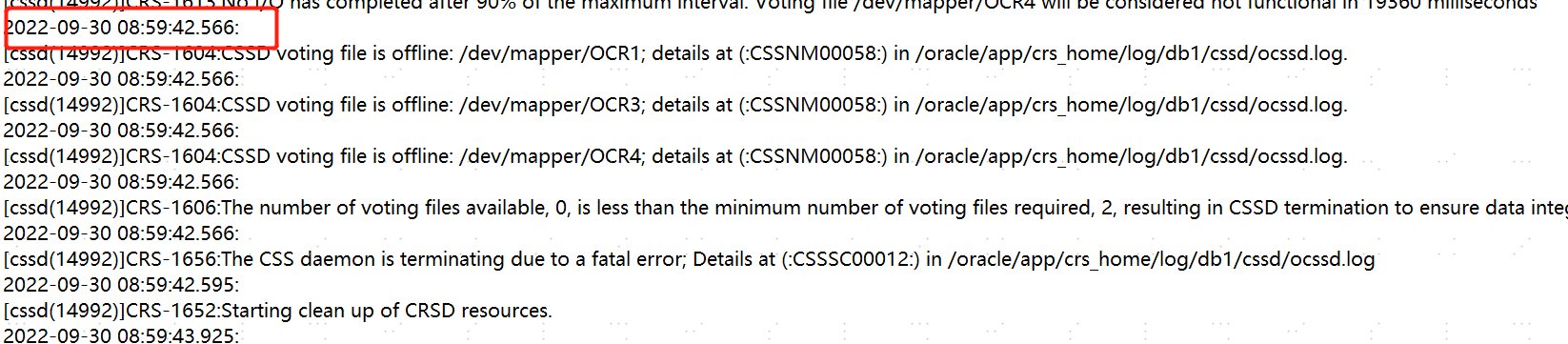
综上: 从alert日志和cssd日志看,应该是由于cssd进程夯,磁盘心跳丢失导致的集群重启。cssd进程夯有可能是cpu或内存太高,进程无法得到正常调度,或者是磁盘io异常导致进程无法调起。以上还需要拿操作系统层面的监控和日志才能确认,最好是有osw。
评论 有用 0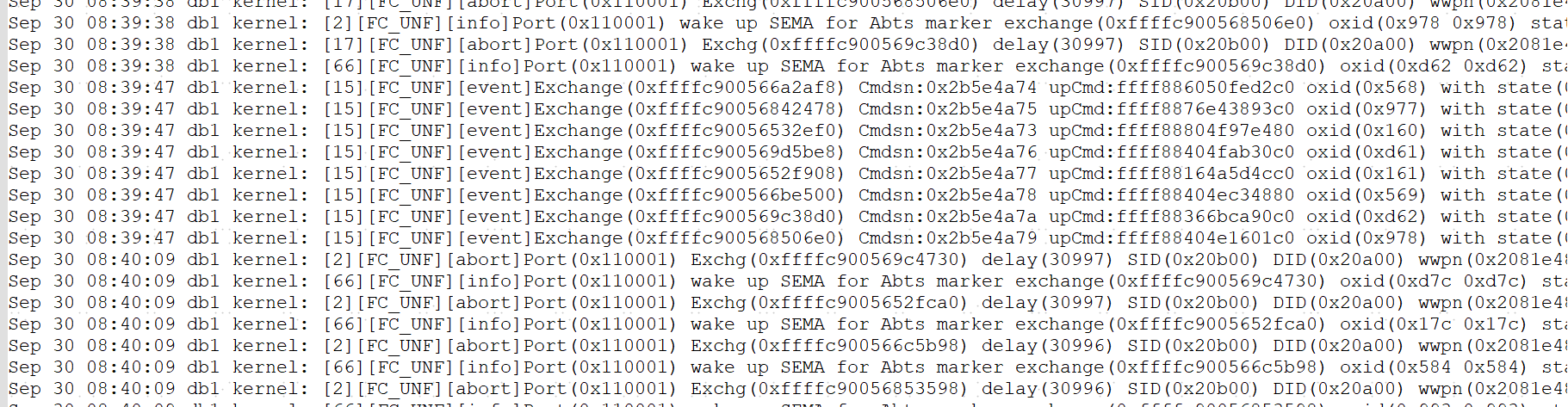
回答交流
提交
问题信息
请登录之后查看
附件列表
请登录之后查看
邀请回答
暂无人订阅该标签,敬请期待~~
墨值悬赏