
 10M
10M
如图,怎么拿到ID=A的三条数据
有个难点就是怎么找到与ID=A重复的数据,找到后 再一次开窗就解决了吧,最好有简洁的写法。
请大佬解答

对于需求我不是很理解,这样写行不:
select min(id),column1,column2,column3 from table group by column1,column2,column3;
 评论
评论 有用 0
有用 0不行哦,需求是ID=A,有三条数,首先column1是b1\b2\b3, column2是c1\c2\c3,column3是d1\d2\d3的为一组数据,要找到跟这组数据相符,但是ID却不同的另一组数据,然后再任意选择其一。想图下中ID=C的组数据,因为只有两条不符合,因此这个图最终结果是AC 或者 BC 的组数据。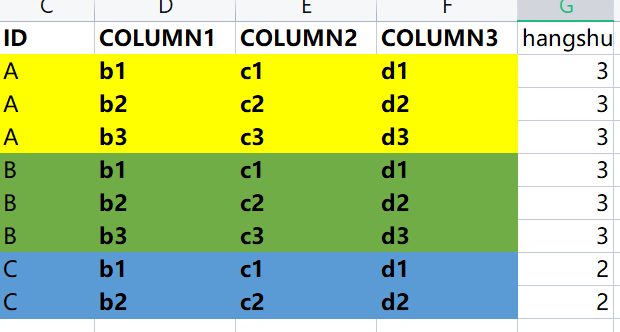
评论 有用 0以ID=A的三条数据为参考,要求找出ID<>A,比如是B,同时也有三条数据,且每条数据的COLUMN1,COLUMN2,COLUMN3三列内容与ID=A的记录相同,是吧
评论 有用 0你能写出来证明你就是大佬,大佬能否贴出脚本让我学习下。
评论 有用 0select distinct id from aa t where id<>'A' and not exists (select column1,column2,column3 from aa where id='A' minus
select column1,column2,column3 from aa where id=t.id);
评论 有用 0我跑了你的SQL,好像报错啊:
) ) T2 ON T1.AN = T2.AN AND T1.ID <> T2.ID);
union ALL
*
ERROR at line 2:
ORA-00923: FROM keyword not found where expected
原始建表语句是这个对吧:
create table aa (id varchar(1),column1 varchar2(5),column2 varchar2(5),column3 varchar2(3));
insert into aa values ('A','b1','c1','d1');
insert into aa values ('A','b2','c2','d2');
insert into aa values ('A','b3','c3','d3');
insert into aa values ('B','b1','c1','d1');
insert into aa values ('B','b2','c2','d2');
insert into aa values ('B','b3','c3','d3');
insert into aa values ('C','b1','c1','d1');
insert into aa values ('C','b2','c2','d2');
commit;
评论 有用 0假设表里没有两条记录完全相同,那还可以如下写法,我认识的一个高手写的:
select a2.ID
from aa a1 join aa a2 on a1.id ='A' and a1.column1 = a2.column1 and a1.column2 = a2.column2 and a1.column3 = a2.column3
where a2.id<>'A'
group by a2.ID
having count(*) = (select count(*) from aa where ID = 'A');
评论 有用 0墨值悬赏