

2023-11-22
SQL优化求助!!!
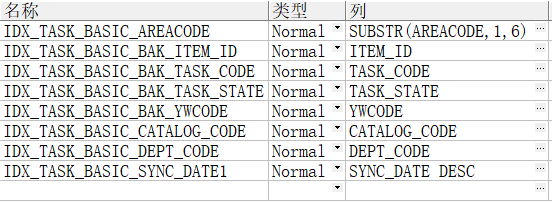
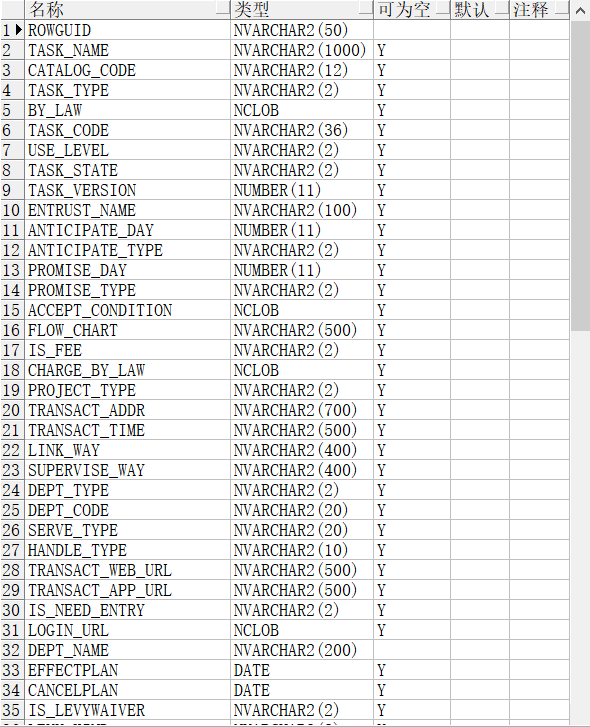
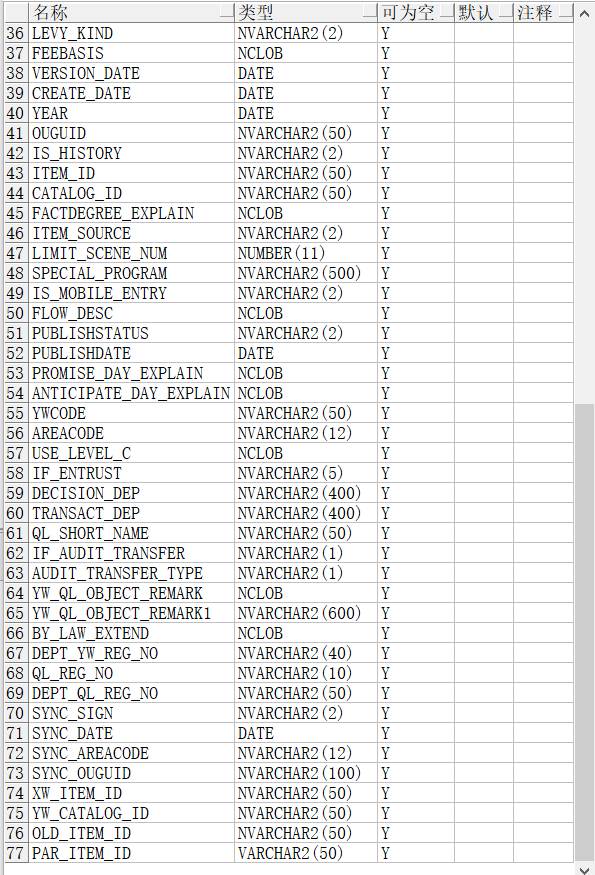
下面这个SQL有优化空间吗?
SELECT nvl(count(1), 0) TOTAL
FROM (SELECT L.*,
ROW_NUMBER() OVER(PARTITION BY L.ITEM_ID ORDER BY L.SYNC_DATE DESC) RN
FROM TABLE1 L)
WHERE 1 = 1
AND TASK_STATE = '1'
AND RN = 1
AND TASK_CODE ='1'
AND YWCODE = '2'
AND DEPT_CODE = '3'
AND SUBSTR(AREACODE, 1, 6) = '4'
AND CATALOG_CODE = '5'
我来答
添加附件
收藏
分享
问题补充
7条回答
默认
最新
 评论
评论

回答交流
提交
问题信息
请登录之后查看
邀请回答
暂无人订阅该标签,敬请期待~~
 墨值悬赏
墨值悬赏