
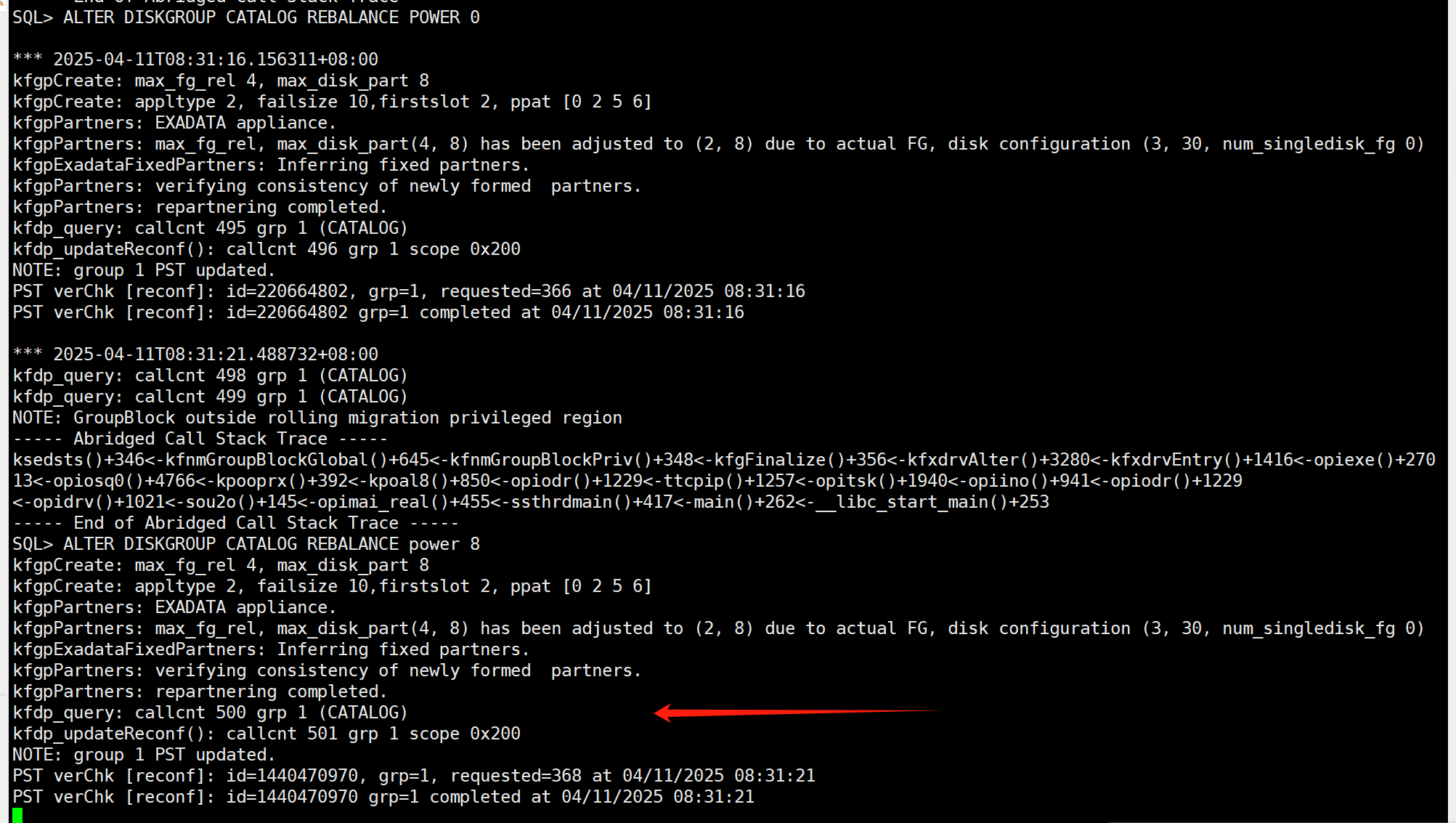
之前由于catalog磁盘组空间不足导致rebalance error,后面迁移数据文件到另外磁盘组后,重新发起rebalance,发现还是wait,日志有arb0启动后停止的操作。下面是具体的操作步骤和相关日志,麻烦大佬给分析下?
开始前的状态

ALTER DISKGROUP CATALOG REBALANCE POWER 0; 暂停平衡
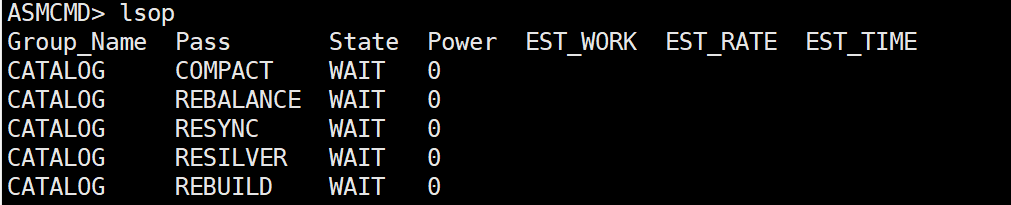
ALTER DISKGROUP CATALOG REBALANCE power 8; 重新发起后没有running,之前同样的操作就会running,估计执行次数多了?
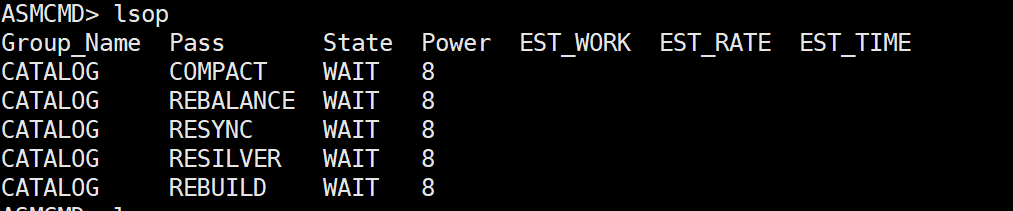
之前正常的情况应该这样,不是wait
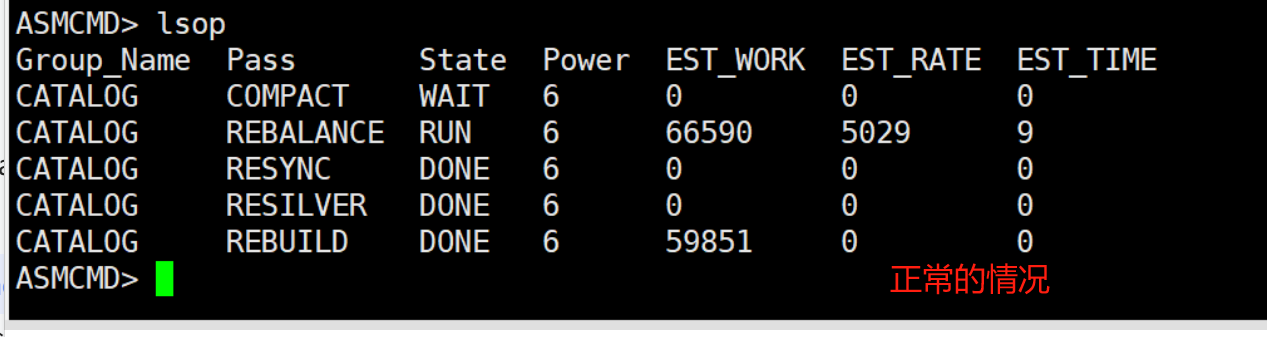
asm alert日志 arb0进程后面停止了
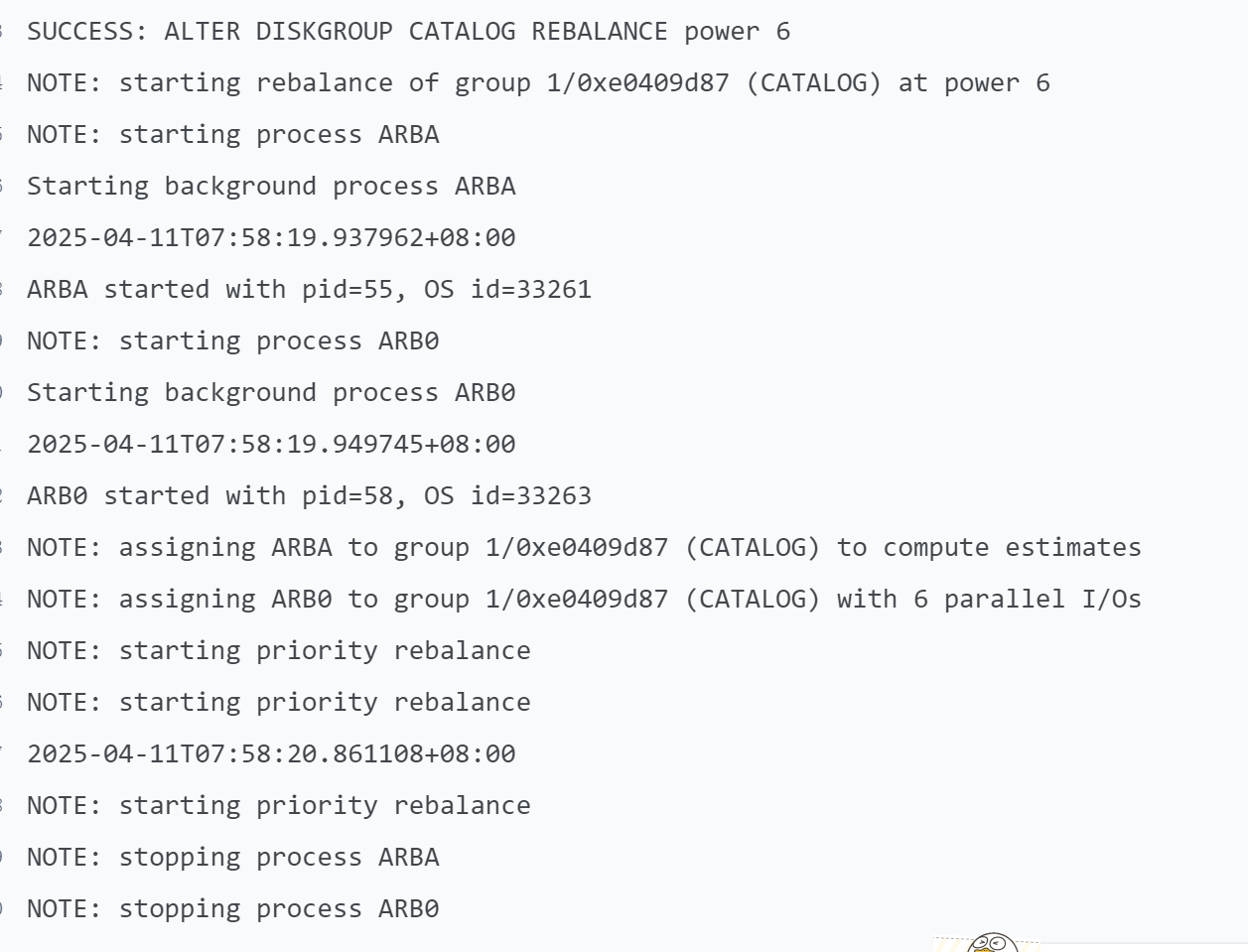
asm trace日志,有人说是pst槽位满了,但是这个没有相关报错

可以进ASM实例查询一下全局重平衡视图,可能你的重平衡操作在asm实例二上进行。
select * from gv$asm_operation;
 评论
评论 有用 0
有用 0
看之前正常情况下是还在这个阶段,但是时间很短了,还可以看一下是不是有盘的free小于300M,这个也会影响
评论 有用 0检查磁盘组中FREE_MB最小的信息
set linesize 300 pages 999
col path for a65
col disk_group_name for a15
col FAILGROUP for a25
col disk_name for a28
select a.group_number ,b.name as disk_group_name ,HEADER_STATUS,a.MODE_STATUS,a.STATE ,a.NAME as disk_name ,a.FAILGROUP ,a.TOTAL_MB,a.FREE_MB,a.path from v$asm_disk a,v$asm_diskgroup b
where a.group_number=b.group_number
and a.FREE_MB < 1000000
order by 1,2,7,6;
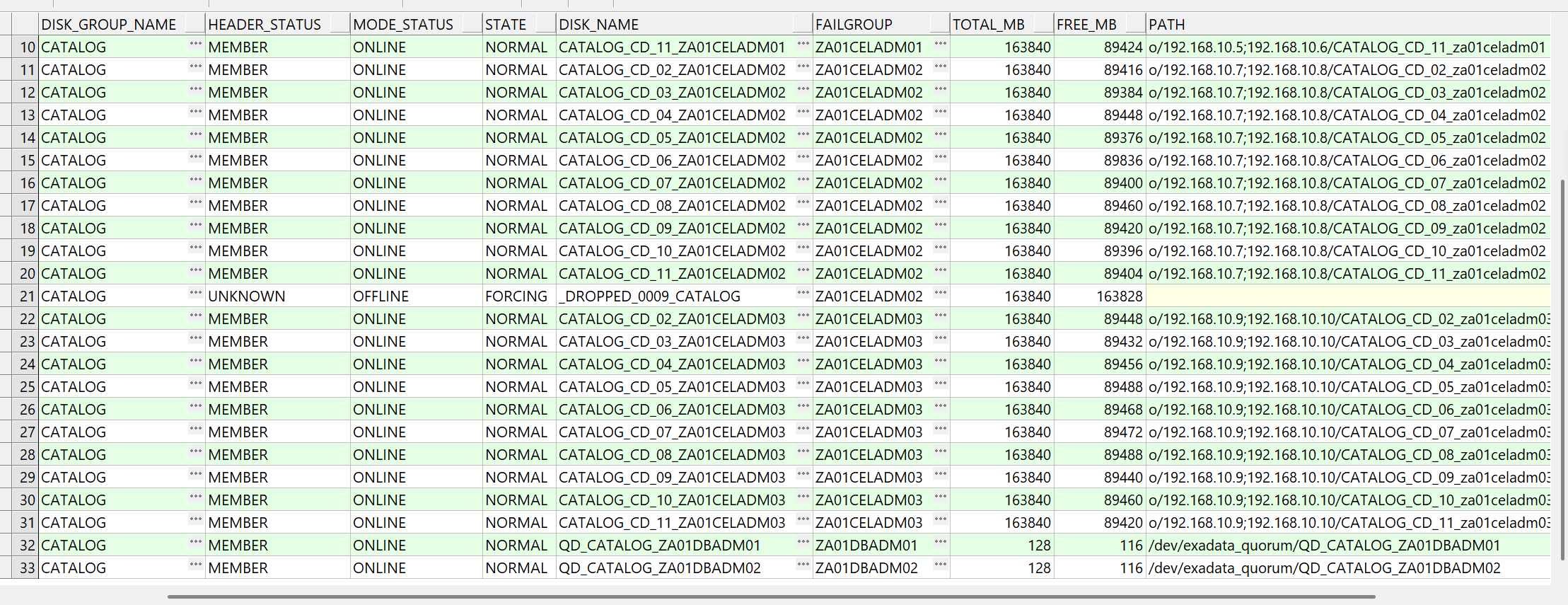
评论 有用 0我这个catalog磁盘组是hign冗余,votedisk用了5个磁盘,其中两个是quorum,磁盘大小是128m。目前_DROPPED_0009_CATALOG有这个一直去不掉,这个当时应该一个盘offline了,后面加上后,因为rebalance一直等待,所以这条记录一直没有被删除!
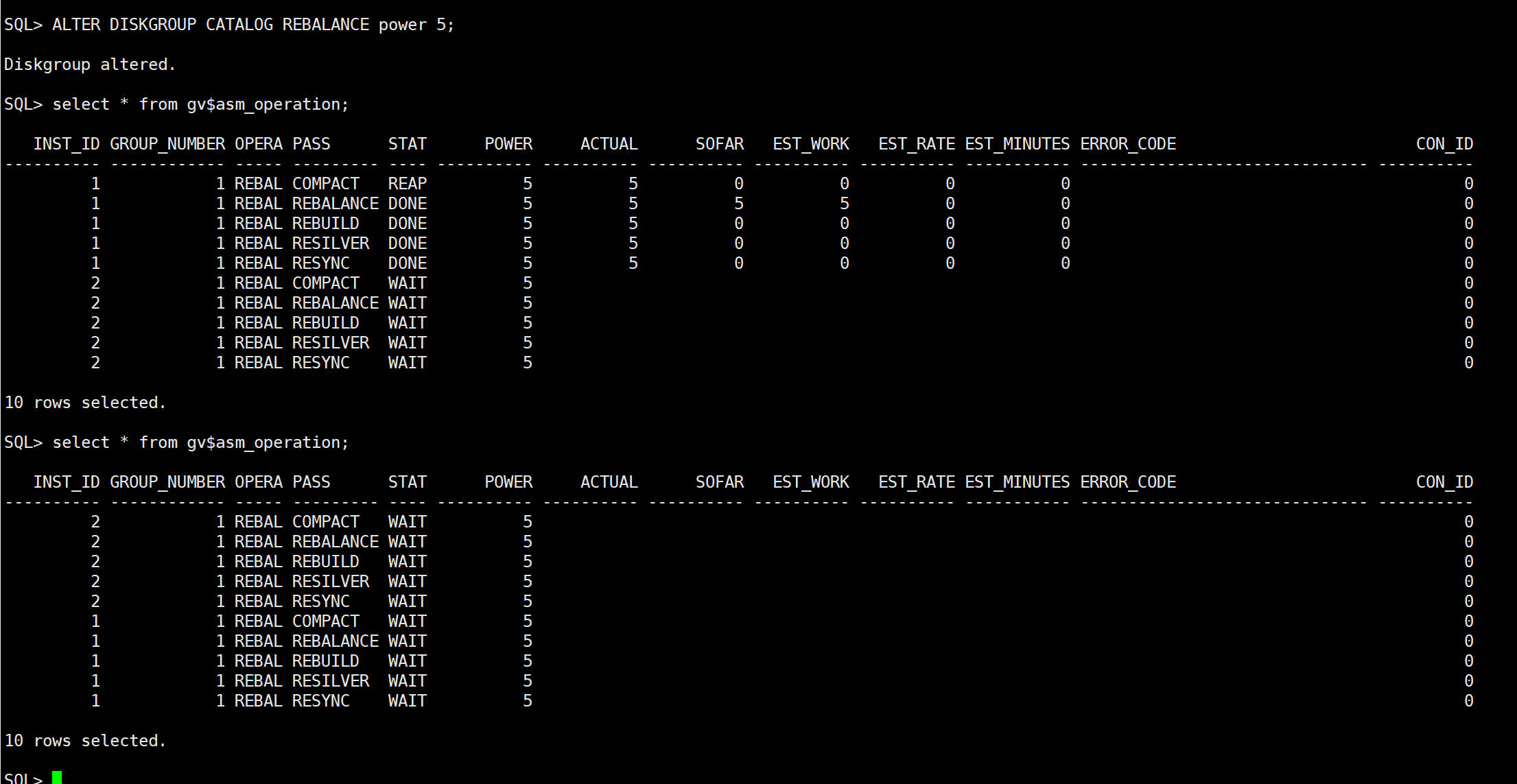
评论 有用 0我刚才暂停reblance后,重新发起平衡,可以看到有操作在跑,但是过会执行完,状态是wait,不是应该跑完查询v$asm_operationn视图是没有数据才正常吗?
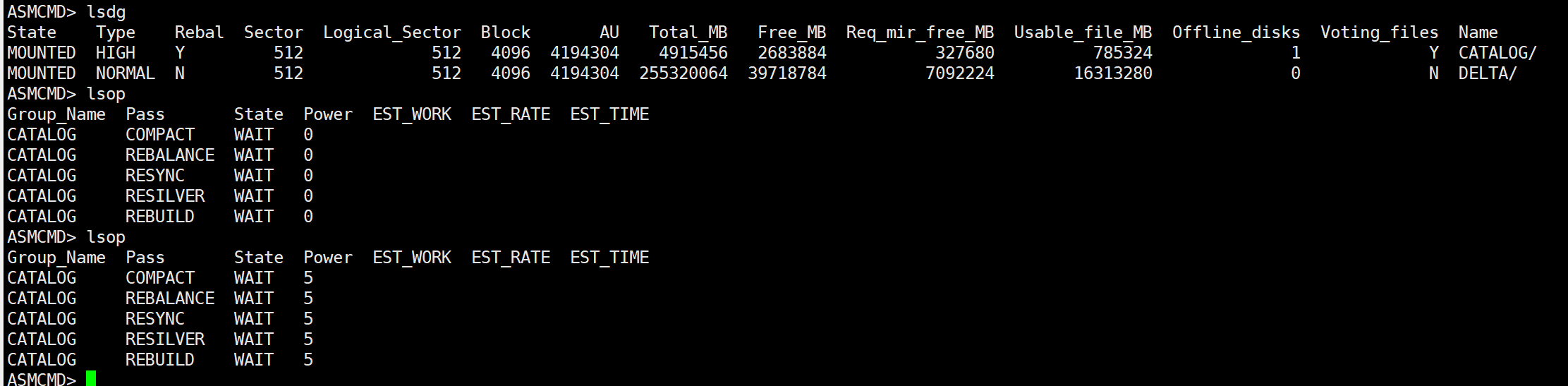
评论 有用 0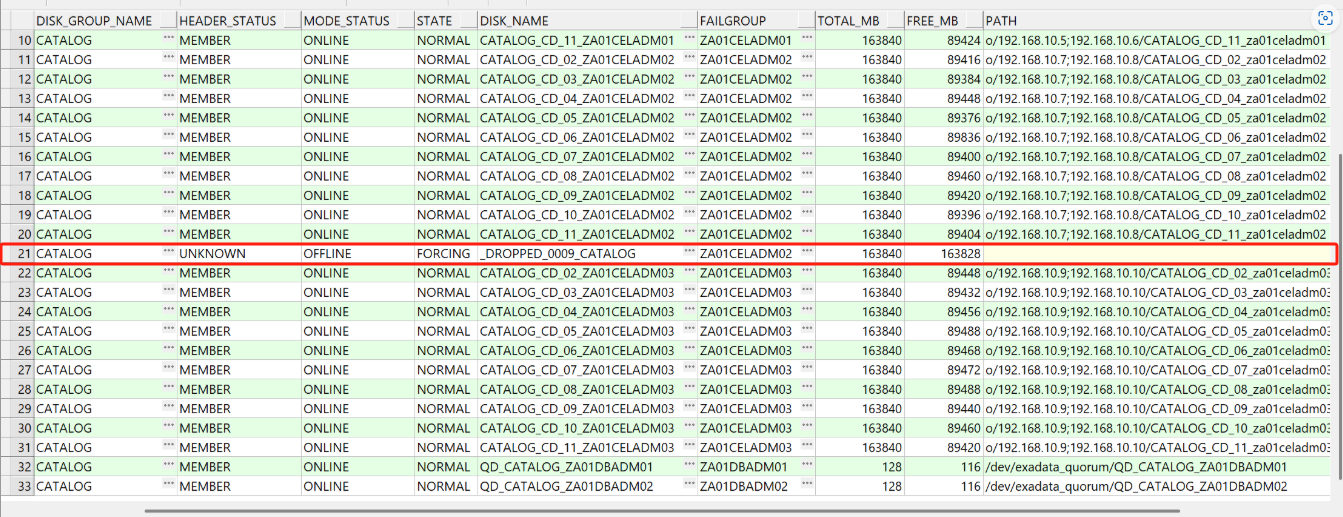
alter diskgroup xxx add failgroup xxx disk 'disk_path' rebalance power 12;
评论 有用 0这是刚才本地环境做的实验,删除一个磁盘,中间会被标记为drop,reblance结束这个记录就没了
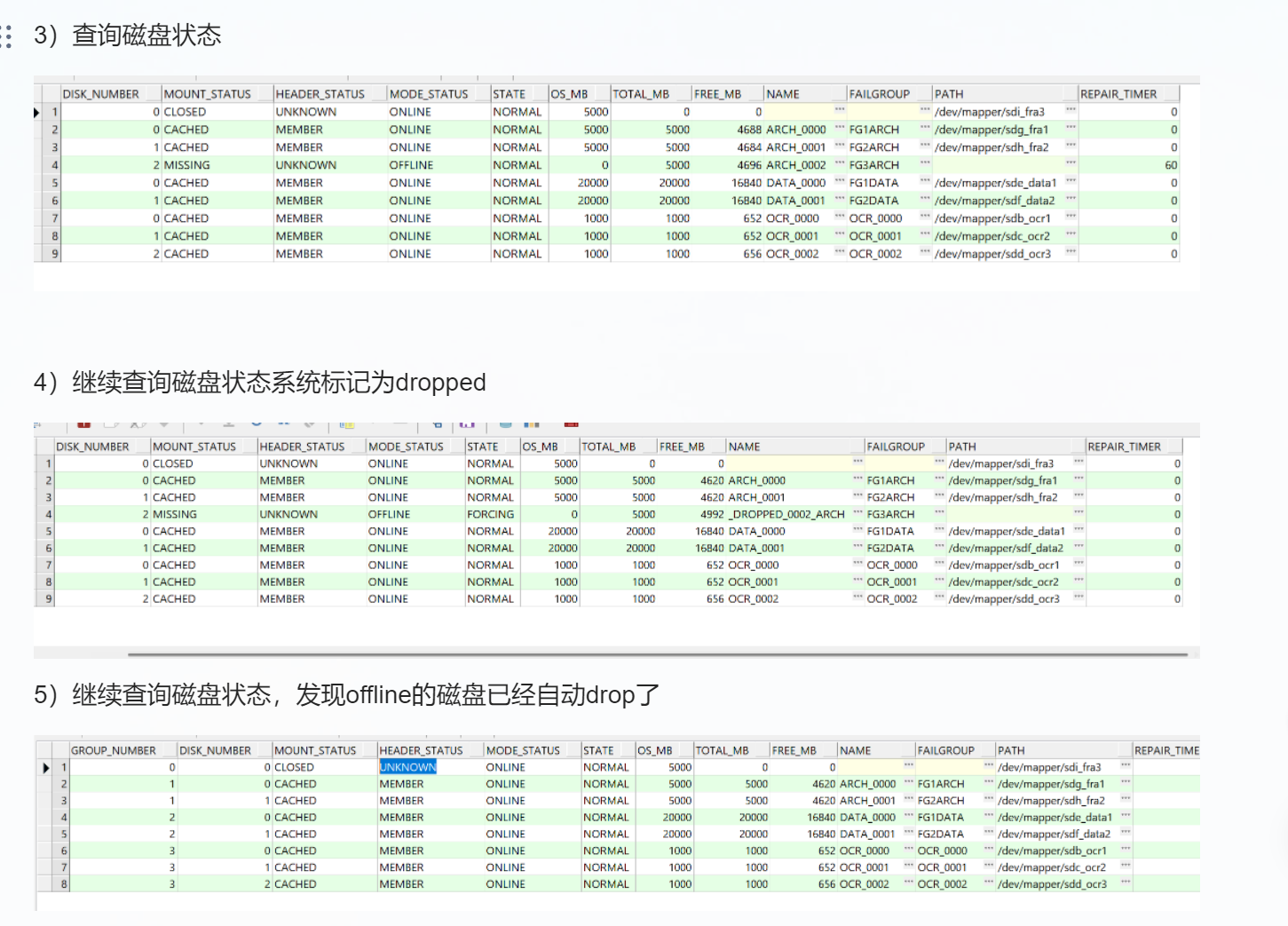
下图是我再次执行添加磁盘的时候提示已经存在
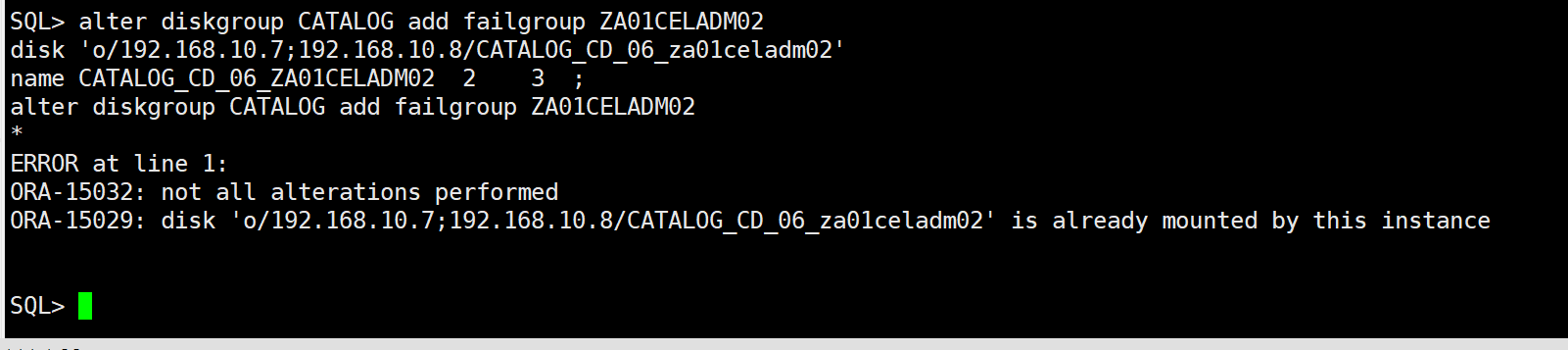
评论 有用 01.先试一下froce加一下
2.如果force加不进去的话就dd一下才能加到磁盘组里面
评论 有用 0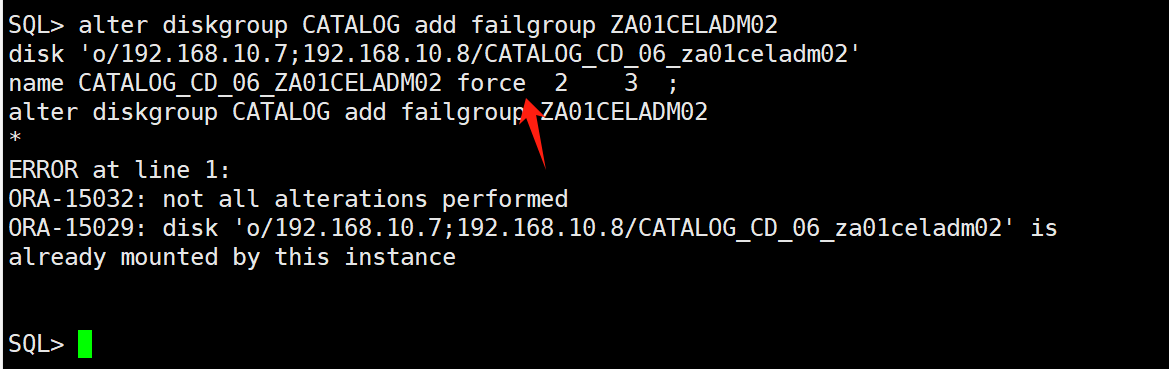
计算节点执行一下:cellcli -e list griddisk attributes name,asmmodestatus
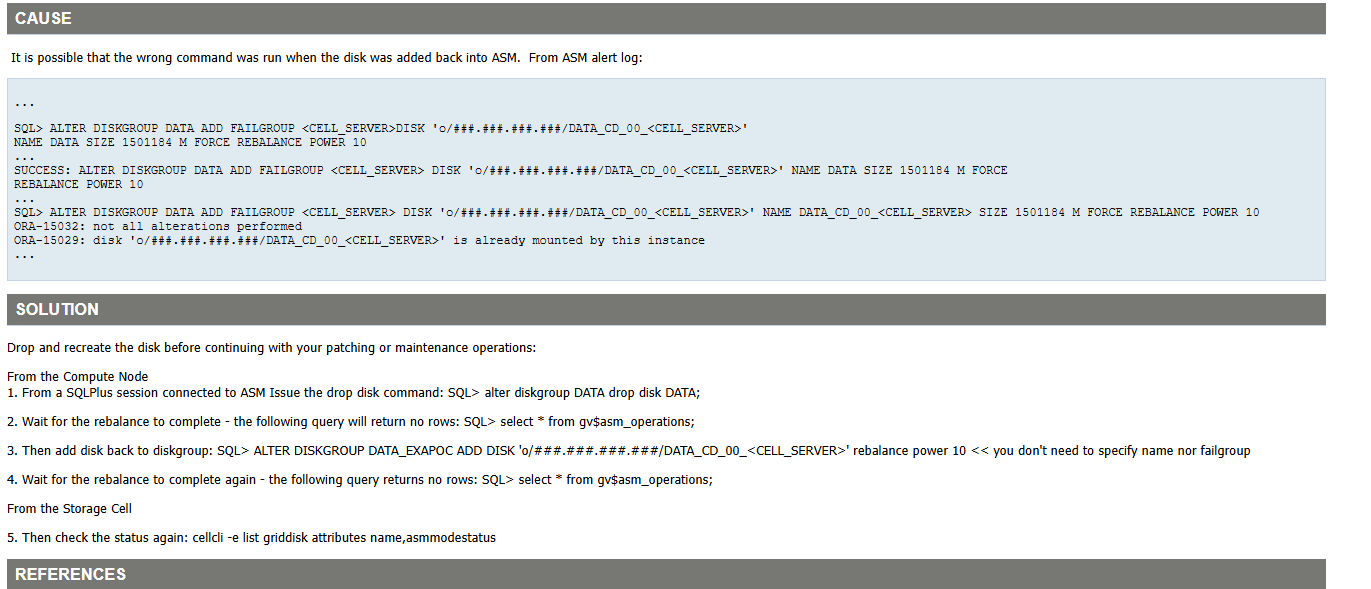
我看mos上类似的报错是先把那个磁盘drop,然后重新加
评论 有用 0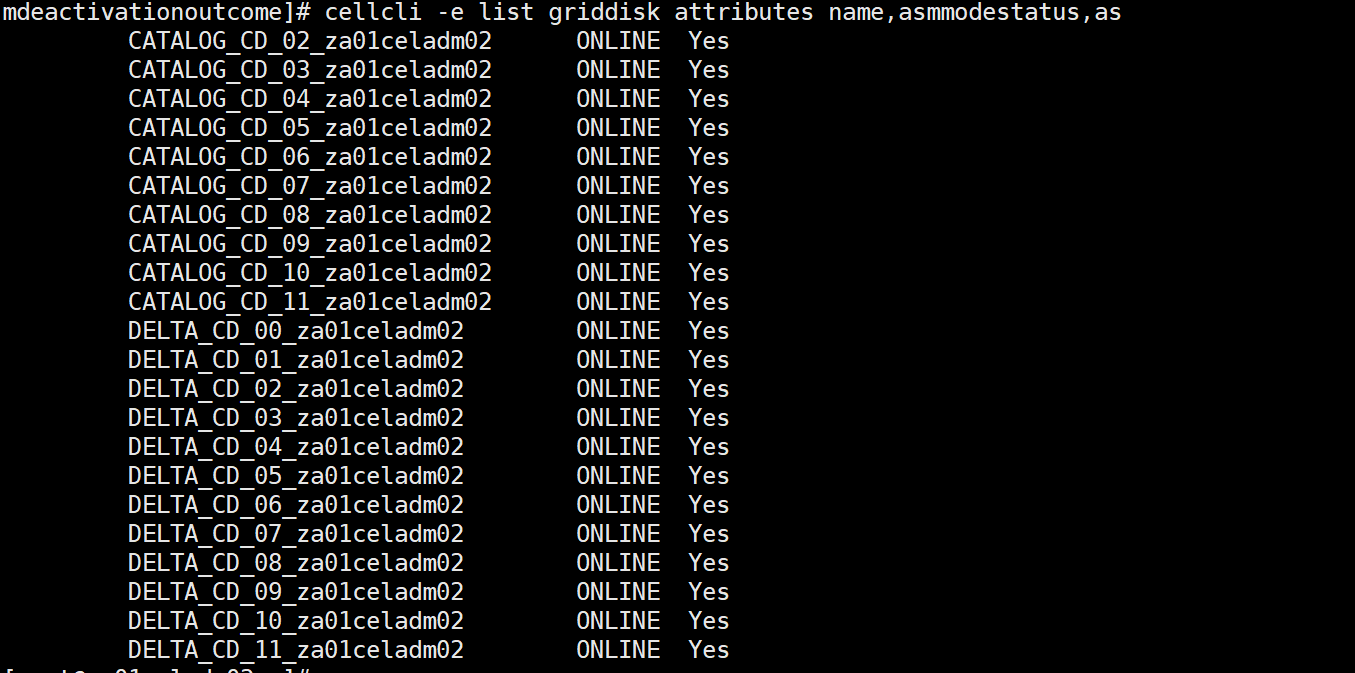



 墨值悬赏
墨值悬赏