

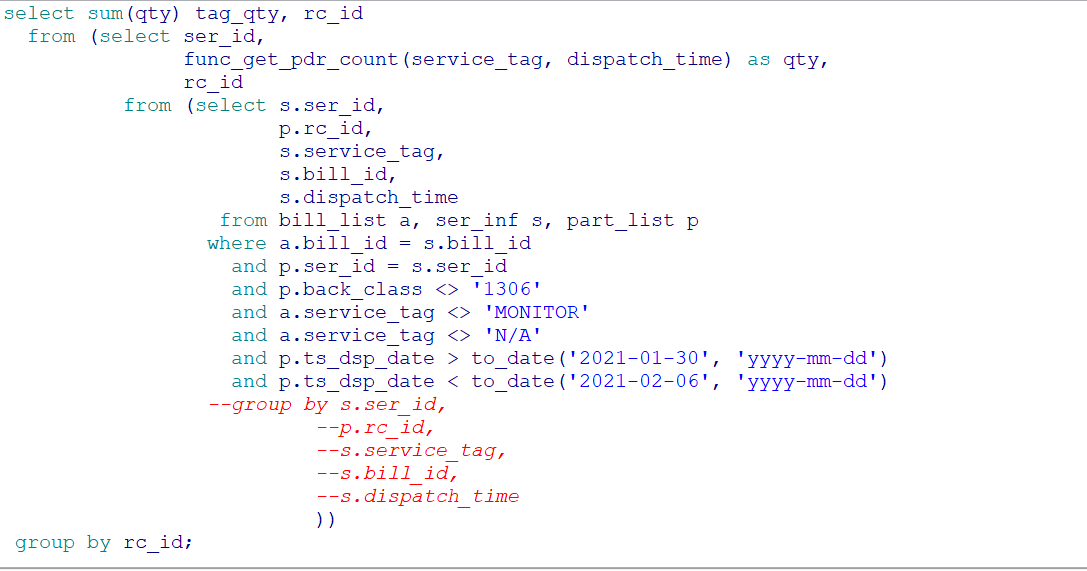
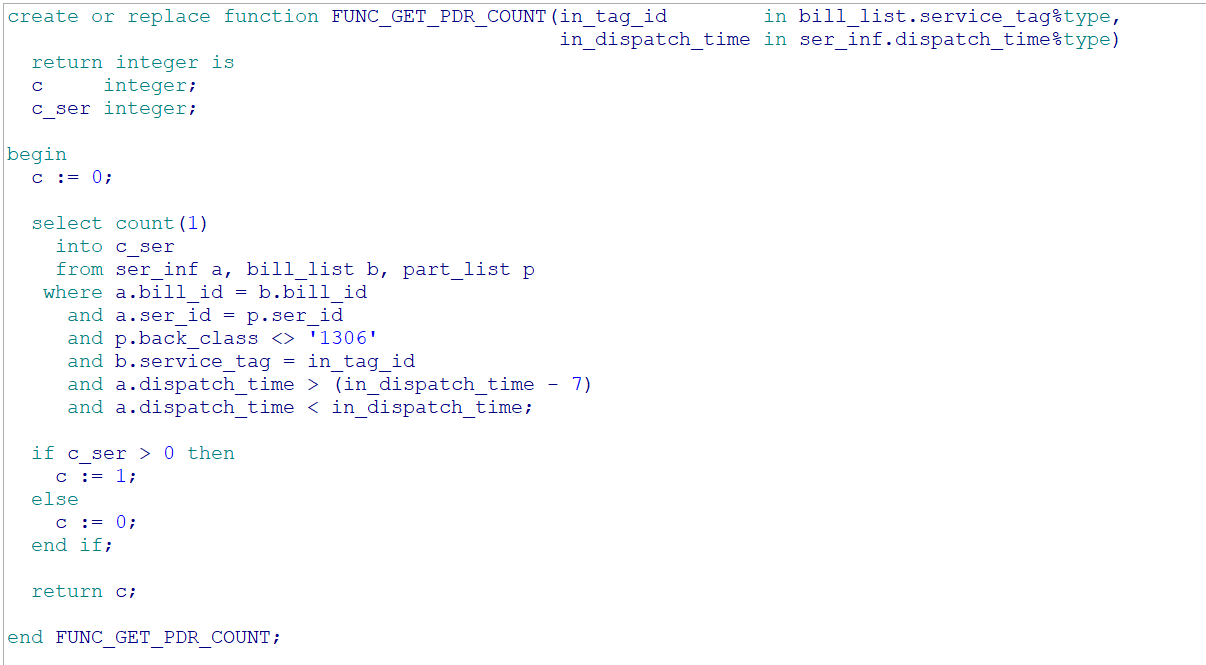
这是oracle 查询语句,查出来需要200s,返回行数100,表都不到100w,不加sum很快,加了sum很慢,sql如下:
select sum(qty) tag_qty, rc_id
from (select ser_id,
func_get_pdr_count(service_tag, dispatch_time) as qty,
rc_id
from (select s.ser_id,
p.rc_id,
s.service_tag,
s.bill_id,
s.dispatch_time
from bill_list a, ser_inf s, part_list p
where a.bill_id = s.bill_id
and p.ser_id = s.ser_id
and p.back_class <> ‘1306’
and a.service_tag <> ‘MONITOR’
and a.service_tag <> ‘N/A’
and p.ts_dsp_date > to_date(‘2021-01-30’, ‘yyyy-mm-dd’)
and p.ts_dsp_date < to_date(‘2021-02-06’, ‘yyyy-mm-dd’)
group by s.ser_id,
p.rc_id,
s.service_tag,
s.bill_id,
s.dispatch_time))
group by q.rc_id;
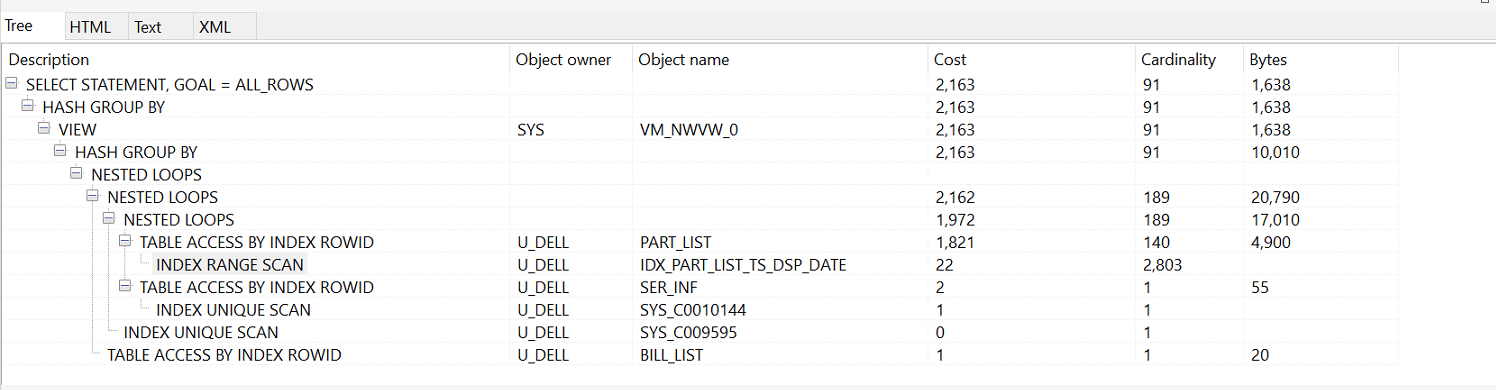
如下为sql执行计划:
Description Object owner Object name Cost Cardinality Bytes
SELECT STATEMENT, GOAL = ALL_ROWS 2,163 91 1,638
HASH GROUP BY 2,163 91 1,638
VIEW SYS VM_NWVW_0 2,163 91 1,638
HASH GROUP BY 2,163 91 10,010
NESTED LOOPS
NESTED LOOPS 2,162 189 20,790
NESTED LOOPS 1,972 189 17,010
TABLE ACCESS BY INDEX ROWID U_DELL PART_LIST 1,821 140 4,900
INDEX RANGE SCAN U_DELL IDX_PART_LIST_TS_DSP_DATE 22 2,803
TABLE ACCESS BY INDEX ROWID U_DELL SER_INF 2 1 55
INDEX UNIQUE SCAN U_DELL SYS_C0010144 1 1
INDEX UNIQUE SCAN U_DELL SYS_C009595 0 1
TABLE ACCESS BY INDEX ROWID U_DELL BILL_LIST 1 1 20
 评论
评论
 墨值悬赏
墨值悬赏