
1.pg_bulkload 概述
1.1 pg_bulkload 介绍
pg_bulkload是一种用于PostgreSQL的高速数据加载工具,相比copy命令。最大的优势就是速度。优势在让我们跳过shared buffer,wal buffer。直接写文件。pg_bulkload的direct模式就是这种思路来实现的,它还包含了数据恢复功能,即导入失败的话,需要恢复。 pg_bulkload 旨在将大量数据加载到数据库中。您可以选择是否检查数据库约束以及在加载期间忽略多少错误。例如,当您将数据从另一个数据库复制到 PostgreSQL 时,您可以跳过性能完整性检查。另一方面,您可以在加载不干净的数据时启用约束检查。
pg_bulkload 的最初目标是COPY在 PostgreSQL 中更快地替代命令,但 3.0 或更高版本具有一些 ETL 功能,例如输入数据验证和具有过滤功能的数据转换。 在 3.1 版本中,pg_bulkload 可以将加载数据转换成二进制文件,作为 pg_bulkload 的输入文件。如果在将加载数据转换成二进制文件时检查加载数据是否有效,从二进制文件加载到表时可以跳过检查。这将减少加载时间本身。同样在 3.1 版中,并行加载比以前更有效。
pg_bulkload 加载数据时,在内部它调用PostgreSQL 的用户定义函数 pg_bulkload() 并执行加载。pg_bulkload() 函数将在 pg_bulkload 安装期间安装。
1.2 性能对比
从 COPY 和 pg_bulkload 加载数据的性能对比来看,WRITER = PARALLEL 模式下的 Pg_bulkload 的数据加载效果几乎是COPY一倍。另外没有索引的COPY并不比有索引的COPY快。因为它必须从初始开始为表的总记录创建索引。
另外:
1.PostgreSQL 参数 maintenance_work_mem 会影响 pg_bulkload 的性能。如果将此参数从 64 MB 更改为 1 GB,则持续时间将缩短近 15%。
2.FILTER 功能在各种操作中转换输入数据,但它不是免费的。实际测量显示,SQL 函数的加载时间增加了近 240%,而 C 函数的加载时间增加了近 140%。
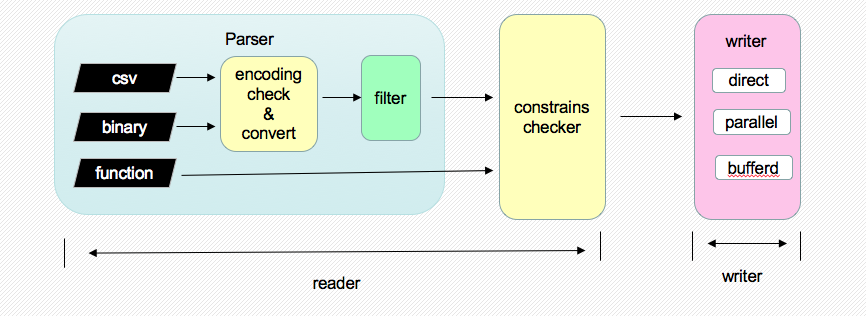
2.pg_bulkload架构图
2.1 架构图
pg_bulkload主要包括两个模块:reader和writer。reader负责读取文件、解析tuple,writer负责把解析出的tuple写入输出源中。pg_bulkload最初的版本功能很简单,只是加载数据。3.1版本增加了数据过滤的功能。
2.2 控制文件参数
在使用pg_bulkload时可以指定以下加载选项。控制文件可以用绝对路径或相对路径来指定。如果您通过相对路径指定它,它将相对于执行 pg_bulkload 命令的当前工作目录。如果你没有指定控制文件,你应该通过 pg_bulkload 的命令行参数传递所需的选项。
部份参数说明
#TYPE = CSV | BINARY | FIXED | FUNCTION
CSV : 从 CSV 格式的文本文件加载 , 默认为CSV
BINARY | FIXED:从固定的二进制文件加载
FUNCTION :从函数的结果集中加载。如果使用它,INPUT 必须是调用函数的表达式。
# WRITER | LOADER = DIRECT | BUFFERED | BINARY | PARALLEL
DIRECT :将数据直接加载到表中。绕过共享缓冲区并跳过 WAL 日志记录,但需要自己的恢复过程。这是默认的,也是原始旧版本的模式。
BUFFERED:通过共享缓冲区将数据加载到表中。使用共享缓冲区,写入WAL,并使用原始 PostgreSQL WAL 恢复。
BINARY :将数据转换为二进制文件,该文件可用作要从中加载的输入文件。创建加载输出二进制文件所需的控制文件样本。此示例文件创建在与二进制文件相同的目录中,其名称为 <binary-file-name>.ctl。
PARALLEL:与“WRITER=DIRECT”和“MULTI_PROCESS=YES”相同。如果指定了 PARALLEL,则忽略MULTI_PROCESS。如果为要加载的数据库配置了密码验证,则必须设置密码文件。
