
GreatDB 数据库介绍
GreatDB 数据库关键技术介绍
- 水平拆分:支持数据sharding和分布式部署
- 动态扩展:支持动态扩容,数据在线重分布
- 故障恢复:故障自动切换保证系统高可用性
- 分布式事务:提供ACID分布式事务支持
- 数据安全:提供企业级数据安全特性,例如安全审计,访问控制
- MySQL协议:完美适配mysql,继承mysql生态
- SQL语法兼容:支持视图、触发器、存储过程、自定义函数等对象
- 并行计算:基于分布式部署,通过分布式并行实现高性能
- HTAP融合:实现基于内存计算的TP与AP混合负载支撑
- 云化支持:支持OpenStack、容器、物理机等多种部署模式
- 国产硬件支持:支持国产软硬件龙芯、飞腾、鲲鹏、海光,中标麒麟芯片、银河麒麟、深之度、统一操作系统。
产品架构
GreatDB Cluster 采⽤了⽆共享(share-nothing)且计算和存储分离的架构设计,计算层由SQL节点 GreatSQL 组成,存储层由数据节点 GreatDB 组成。
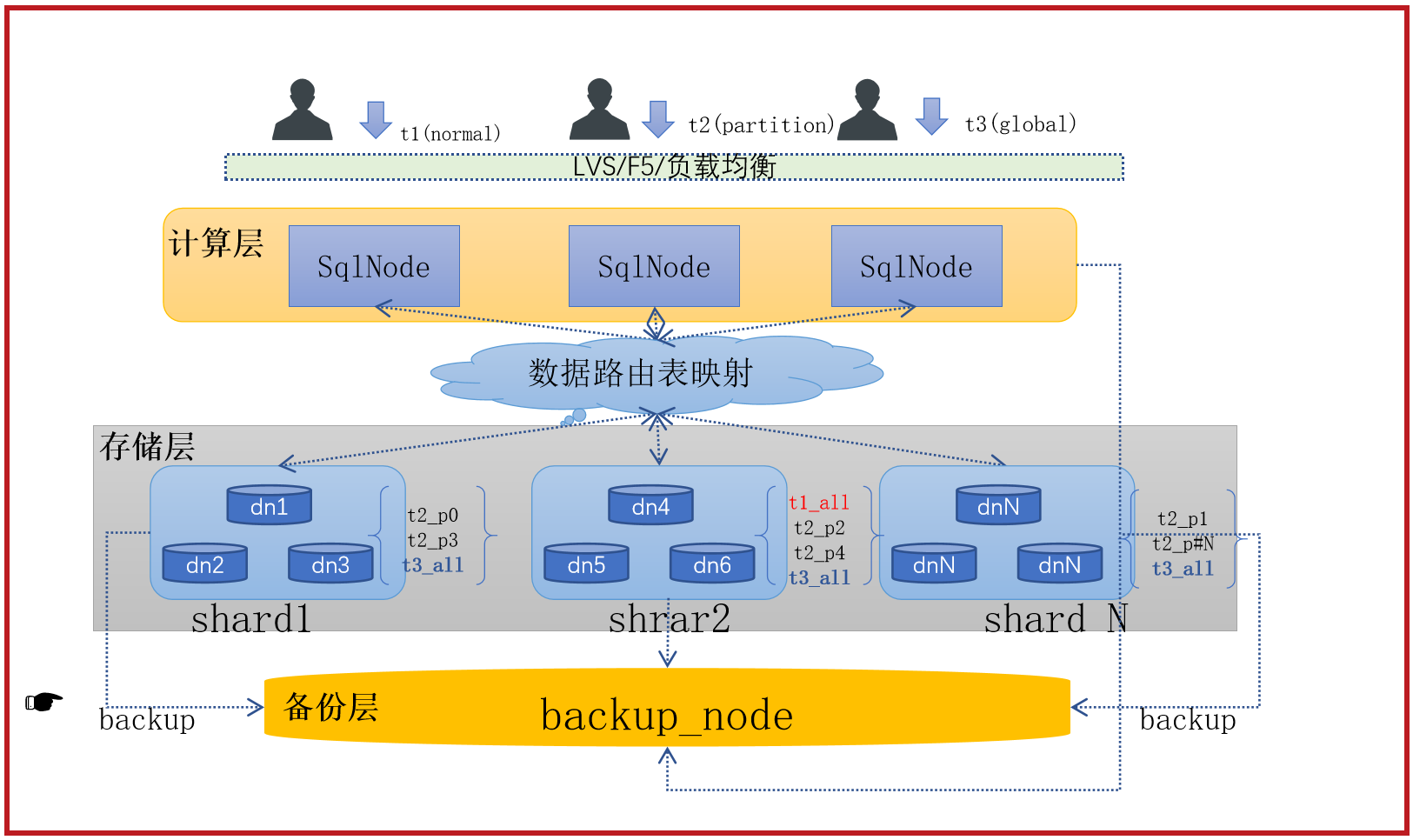
- GreatSQL: SqlNode节点。⽤于接收、处理⽤户请求,维护集群元数据,管理集群状态。
- GreatDB: DataNode节点,⽤于接收SQL节点的请求,进⾏简单的数据存取的操作;维护数据副本强⼀致性。
- 多个 GreatSQL 组成了计算层,计算层中的集群元数据通过 paxos 协议进⾏同步。
- 存储层以 shard 进⾏数据分⽚管理,同⼀个 shard 内的多个 GreatDB 组成⼀个 paxos 复制组,维护同⼀份数据,不同的 shard 之间数据⽆重叠。
SqlNode 节点
SqlNode 节点包含如下模块:
- GreatDB计算引擎,兼容MGR多主模式。
- 连接管理: 负责接受⽤户的连接、登陆请求。
- SQL解析: 将⽤户请求的SQL,解析成内部 parse tree 的格式。
- 计划⽣成: 根据表元数据信息和统计信息,⽣成最优执⾏计划。
- 执行SQL或SQL下推:根据执⾏计划,操作 DataNode,进⾏数据的获取与写⼊。
- Sequence,SqlNode/DataNode/backup_node 增删调整,配置执行。
DataNode 节点
⽤户数据存储在 DataNode 节点,节点间通过 paxos 协议保证⽤户数据的多副本的强⼀致性。GreatDB Cluster 的 DataNode 不仅仅是存储数据,本⾝具有相对完整的计算能⼒,可以进⾏较强的运算,分担计算层的计算压⼒。
- 主数据节点接收上层 SqlNode 下发命令。
- DataNode 为 Shard 的成员,一个 Shard 分片为一个 Paxos group 复制组。
- 存储节点层标准的一个 Shard 组为1主2从结构。
- Shard 内部存储表和本地索引数据,Shard 支持在线扩容、缩容。
- 扩缩容操作可以在新增 Shard 和原始 Shard 之间进行数据重分布。
- 故障自动切换,自身具备一定的健壮性。
GreatDB 分布式关系型数据库安装部署(三种安装方式,任选其一,推荐使用Ansible部署)
软硬件环境建议配置
GreatDB Cluster可以很好的部署和运⾏在 Intel 架构服务器环境、ARM 架构的服务器环境及主流虚拟化 环境,并⽀持绝⼤多数的主流硬件⽹络。作为⼀款⾼性能数据库系统。⽀持主流的Linux操作系统。
Linux 操作系统版本要求
|Linux操作系统|版本|服务器架构| |-|-|-| |Red Hat Enterprise Linux|7.2 及以上|x86_64,ARM_64| |CentOS|7.2 及以上|x86_64,ARM_64| |SUSE Enterprise Linux|12SP3 及以上|x86_64,ARM_64| |Ubuntu|16.04 及以上|x86_64,ARM_64| |Debian|8.3 及以上|x86_64,ARM_64|
服务器建议配置
- 开发及测试环境
|服务器类型|最⼩数量|最低配置| |-|-|-| |SQL节点|3(可和数据节点复⽤)|32C,64G,1TB,千兆⽹卡(可配置多块)| |数据节点|3|32C,64G,1TB SSD存储,千兆⽹卡(可配置多块)| SQL节点最⼩数量为3,最好配置成奇数个,如3,5,7。 数据节点个数建议为3的整数倍。每个shard内3副本。
- ⽣产环境
|服务器类型|最⼩数量|最低配置| |-|-|-| |SQL节点|3|32C,128G,1.5TB,万兆⽹卡(可配置多块)| |数据节点|3|32C,256G,2TB SSD存储,万兆⽹卡(可配置多块)| SQL节点最⼩数量为3,最好配置成奇数个,如3,5,7。SQL节点存储集群元数据,同时承担⼤部分计算任务,有些优化策略会⽣成临时表,故如果⽤户对性能要求很⾼,可以配置SSD。 数据节点最⼩数量为3,⼀个shard内最⼩副本数为3,最⼤副本数为9,推荐⼀个逻辑shard内副本个数为3。
BIOS 设置
- 选择 Performance Per Watt Optimized(DAPC) 模式,发挥 CPU 最大性能
- 关闭 C1E 和 CStates 等选项,目的也是为了提升 CPU 效率
- Memory Frequency(内存频率)选择 Maximum Performance(最佳性能)
- 内存设置菜单中,启用 Node Interleaving,避免NUMA问题
- 关闭 SMMU (非虚拟化场景使用),重启服务器过程中,进入 BIOS--MISC Config--Support Smmu 设置为 Disable
- 关闭预读,重启服务器过程中,进入BIOS--MISC Config--CPU Prefetching Configuration 设置为 Disabled
- 关闭 RAID 卡的预读一般配置项为 Read Policy,
- 经测试单机 GreatDB,将 stripe size 从 256k 调整到 64k,依据并发度的不同,性能提升有10%-25%
调整 CPU 模式
数据库服务器的CPU运⾏模式需要调整到 performance 模式,以追求⽐较稳定的性能。 以 centos7 为例,执⾏以下命令检查和设置 cpu 运⾏模式:
# 检查当前cpu模式,发现是 powersave 模式
[root@greatdb-test-01 ~]# cpupower frequency-info
...
available cpufreq governors: performance powersave
...
# 设置CPU为 performance 模式
[root@greatdb-test-01 ~]# cpupower frequency-set -g "performance"
# performance 模式检查
[root@greatdb-test-01 ~]# cat /sys/devices/system/cpu/cpu0/cpufreq/scaling_governor
performance
注:如果该步报文件不存在,则需要安装 kernel-tools
# CentOS 安装 kernel-tools
yum install kernel-tools -y
# Ubuntu 安装 CPU 模式无图形化切换器
apt install cpufrequtils
文件系统
建议使用xfs高性能文件系统 Linux ext系列的文件系统,应该是文件系统史上非常经典的杰作。在CentOS 7之前都是默认采用的这一系列文件系统。但是从CentOS 7开始默认的文件系统变成了xfs文件系统,在操作系统支持的情况下,选择顺序如下 xfs>ext4>ext3
io调度参数调整
修改 /sys/block/sda/queue/scheduler 调整io调度配置 如果是机械硬盘建议调整成 deadline 如果是 SSD&PCI-E 建议调整成 noop
配置拓扑结构
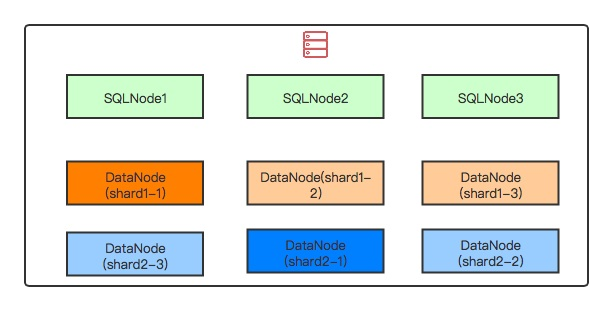
最⼩部署拓扑结构
最⼩部署拓扑结构⽤于个⼈快速尝试新功能,可以将所有的节点部署在⼀台服务器上,3个SQL节点,2个shard,每个shard内3个数据节点。具体的部署拓扑图如下:
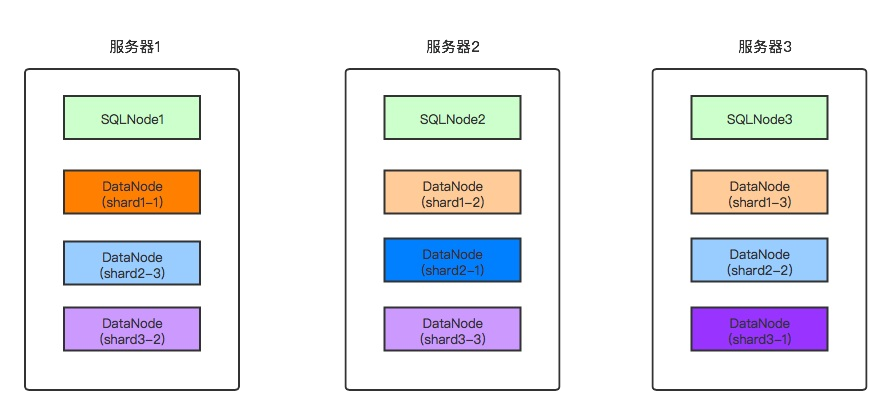
开发及测试环境部署拓扑,下面的部署测试使用的是这种拓扑
开发及测试环境⽤于团队⻓期开发或者团队内部⻓期进⾏功能测试的场景,不适合⾼性能场景。 下⾯以总共3台服务器,SQL节点与数据节点共⽤的情况,给出部署拓扑图。
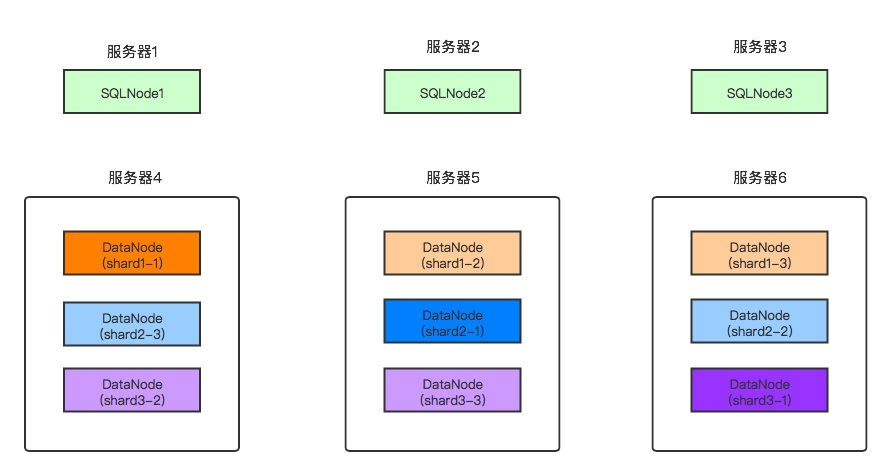
⽣产环境部署拓扑
下⾯以总共6台服务器,3台计算服务器,3台存储服务器的场景,给出部署架构图。
本次实验架构图
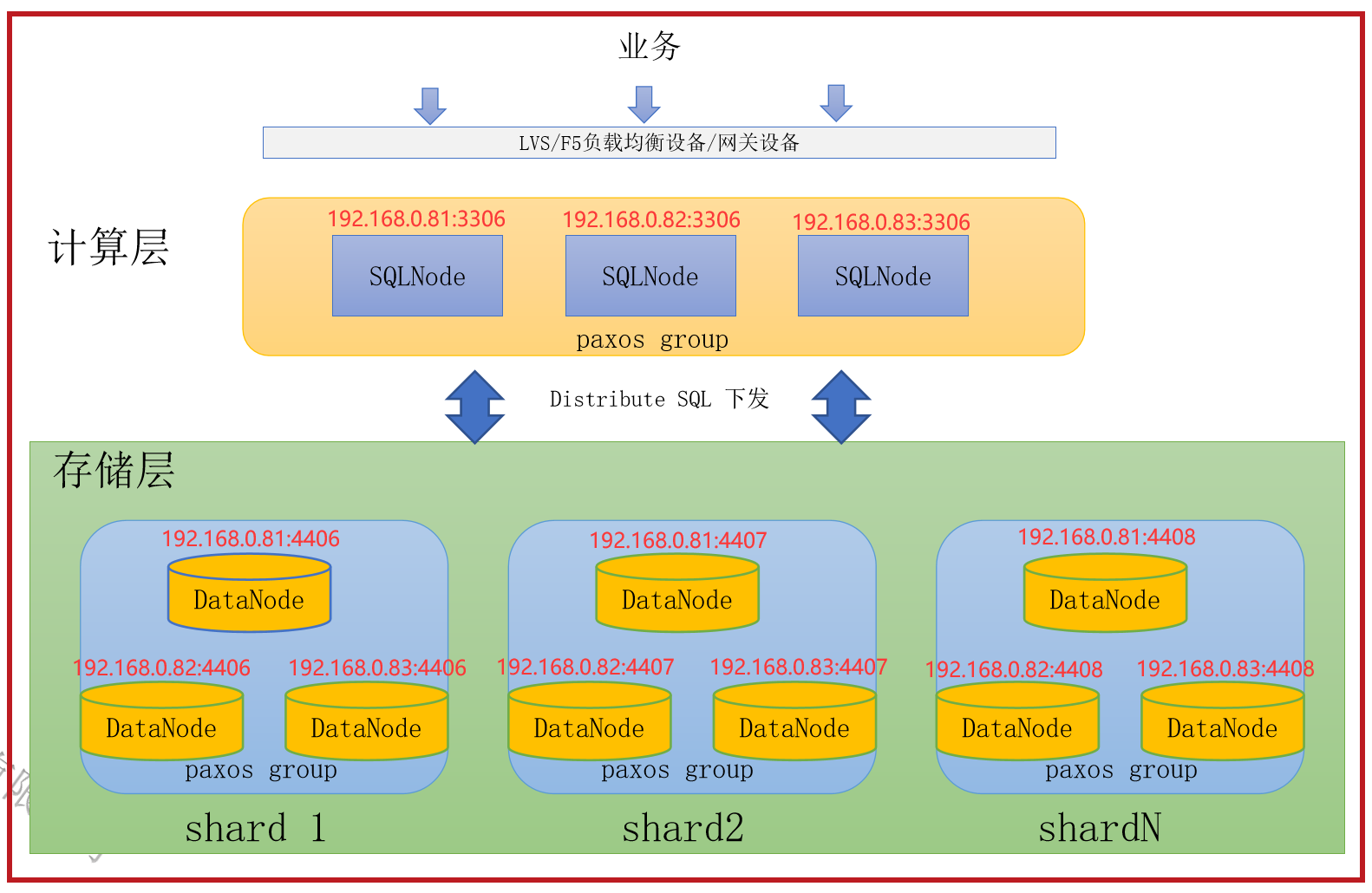
安装前准备(所有节点)
- 关闭操作系统防火墙和NetworkManager,使用Ansible部署会自动关闭防火墙
systemctl stop firewalld.service
systemctl disable firewalld.service
systemctl stop NetworkManager.service
systemctl disable NetworkManager.service
- 关闭SELINUX,使用Ansible部署会自动关闭SELINUX
sed -i "s/SELINUX=enforcing/SELINUX=disabled/g" /etc/selinux/config
setenforce 0
- 设置时区和时间,有条件的配置时间同步,使用Ansible部署会自动配置时区为 Asia/Shanghai
cp /usr/share/zoneinfo/Asia/Shanghai /etc/localtime
date -s "20201021 09:43:00"
[root@enmo ~]# timedatectl
Local time: Wed 2020-10-21 09:43:04 CST