产品特点
-
易用的平台管理界面
H3C DataEngine提供可视化的集群安装部署界面,方便快捷的进行资源管理,主机分配等操作,支持组件服务一键安装、升级和图形化运维,实时监测各项服务的健康状态以及运行指标,超过一定配置阈值后进行告警并邮件通知管理员,大幅提升运维效率。 -
无共享大规模并行计算
MPP集群中的所有节点完全对等,不需要主节点,数据加载、数据导出和查询都可以并行地在所有节点同时执行。由于没有资源共享,增加节点就可以线性地扩展MPP的数据容量和计算能力,可以轻松从几个节点到上千节点、或从几个TB到数10PB规模扩展和收缩,满足业务规模增长的要求。 -
分级存储
在大数据时代,数据产生越来越快,而合规性和深度挖掘要求保留更多的数据,因此数据库中存放的数据越来越多。分析性能、高速磁盘高成本和大数据容量要求常常是矛盾。MPP的分级存储特性可以有效地化解这一矛盾。MPP可以为不同的Schema、表等对象、以及表分区指定不同的存储策略,指定不同的存储位置(可以采用不同性能、成本和容量的存储介质),从而优化存储成本。 -
自动优化设计
MPP内置包含专家知识的数据库优化设计器。用户只需要指定逻辑模式(Schema),装载样例数据,并提供典型查询SQL语句, MPP的数据库优化设计器就会根据专家知识自动设计数据的水平分布方式、每个列的排序方式和压缩算法,平衡查询性能和存储空间大小要求,实现数据库整体的最优化。 -
强大的数据接入能力
通过面向服务的数据接入平台,将异构数据源集成过程封装为数据服务单元的形式对外提供服务,形成四通八达的数据传输服务,让数据不再成为孤岛。支持从DBMS、互联网、物联网、企业生产系统等各种数据源中提取数据,并将处理结果快速存入到H3C DataEngine平台中。使得用户不用再关注底层数据的传输过程,轻松易用,专注于上层平台应用的开发。 -
通用数据服务接口
提供统一SQL服务和可编程API,提取数据存储计算平台的数据处理结果,屏蔽底层细节,为上层应用提供数据服务。数据服务接口主要包括SQL接口、MapReduce/Spark/Storm/Flink等多种计算框架的可编程API、全文搜索接口、业务定向接口、关联查询接口,满足数据查询、可视化BI展示、数据分析、综合查询等业务应用的需要。提供接口文档、二次开发指导手册与二次开发示例程序,满足开发人员的使用需求。 -
安全的数据管控中心
H3C DataEngine基于安全协议Kerberos实现安全认证,使用LDAP作为账户管理系统;同时利用Range提供统一的用户和角色的管理体系,遵从RBAC(Role-Based Access Control)模型规范,通过角色绑定用户进行权限管理。此外DataEngine还支持用户对各组件的审计日志及检索能力,全组件管理界面均支持单点登录,使得平台真正做到安全可靠。 -
智能数据分析挖掘
支持R语言,集成机器学习算法库Spark MLlib,包含聚类分析、分类算法、频度关联分析和推荐系统在内的常用机器学习算法。满足批处理统计分析、在线数据检索、R语言数据挖掘、实时流处理、全文搜索等全方位需求。可帮助企业建立高速可扩展的数据仓库和数据集市,结合多种报表工具提供交互式数据分析、即时报表和BI可视化展示能力。 -
多形态部署模式
数据平台支持独立模式和共享模式两种资源划分模式,满足不同场景下业务需求。共享模式下可以创建一个大集群,不同用户申请集群的共享存储和计算资源,并通过权限进行隔离,适合对资源管控严格且各二级部门数据交换频繁的企业使用。独立模式下不同用户可申请创建单独的集群,独享集群的所有资源,不同集群之前使用网络进行隔离,适用于资源比较充分且各二级部门之间业务相对独立的企业。
此外为满足企业稳定性要求,DataEngine还提供了常用服务的独立产品模式,包括NoSQL数据库HBase、内存数据库Redis、消息中间件Kafka、搜索服务Solr和Elasticsearch,避免不同组件之间资源抢占影响集群稳定性。 -
深度融合H3C CloudOS
H3C DataEngine大数据平台做为H3C CloudOS云服务提供,充分发挥云计算与大数据融合优势,利用云IaaS能力提供虚拟化资源池和裸金属资源池,用户可以根据具体业务场景灵活选择数据平台部署模式。虚拟机部署适合小数据量、性能要求不高的应用场景,最大化服务器资源利用率;裸金属部署适合大数据量、高性能场景,提升用户业务能力。
功能特性
-
可视化安装运维管理
大数据平台提供一体化的安装运维管理界面,通过Web界面化的方式实现一站式安装部署、监控告警、参数配置、服务管理、日志审计、用户管理、多集群管理等功能,避免用户在多个管理界面间切换;对集群的各项服务做集中式管理,提供启动服务、停止服务、修改属性和设定运行参数等功能,实现集群各项服务运行状态(基本信息、告警、运行健康状态)实时监控,保障集群稳定运行。 -
实时数据接入
数据接入服务以可视化的方式构建数据接入任务,轻松完成多种数据源的采集、处理以及分发,提供离线数据迁移、实时数据同步以及日志采集等功能,以实时数据流形式将传统数据库、日志文件、IoT等数据源数据接入到DataEngine存储服务中,适用于数据迁移、数据灾备等场景。 -
多样化分布式计算框架
DataEngine提供MapReduce、Tez和Spark三种分布式批处理框架,分别满足稳定、高效、快速迭代三类应用场景,同时支持Hive、SparkSQL等SQL on Hadoop工具,简化计算任务编写过程,快速进行数据开发工作。
Hive默认执行引擎采用Tez计算框架,将多个具有依赖的作业转换为DAG作业,避免复杂任务多次读写HDFS过程,大幅提升作业运行性能,复杂计算场景下相比MapReduce作业能够提升10倍以上性能。
数据平台还提供Spark内存计算框架,通过RDD之间的血缘关系管理算子之间依赖关系,确保数据能够快速恢复并重新计算,中间结果数据支持灵活选择内存、SSD等缓存模式,在迭代式计算场景提供更高性能的算力,计算性能可达MapReduce的10-100倍。
-
实时流式处理
H3C DataEngine采用Flink计算框架统一流批处理,一个计算引擎可同时满足流计算业务和批处理业务,支持自实现状态管理和Exactly-Once语义,具有容错机制,保证数据零丢失,具有极佳的吞吐量及亚秒级延迟性能。同时支持完善Flink SQL语法,快速实现双流join、流批join等业务场景,降低流式作业开发难度 。 -
自研SQL引擎
DataEngine大数据平台提供自研Sparrow组件,对外提供统一的SQL访问服务。兼容通用标准SQL,从数据库平滑过渡到大数据平台,提升SQL兼容性,可对接ES、HBase、Hive等数据源,降低平台使用门槛;提供增强型统一SQL on Hadoop方案,支持图计算与机器学习SQL,大幅度提升平台易用性。 -
云化大数据服务
采用基于云计算平台的大数据服务,用户通过云端申请大数据集群,H3C CloudOS云平台会为大数据集群分配和管理主机资源,用户只需专注于自己的业务层面,按需购买大数据服务,并可为大数据集群提供扩容、缩容的功能。提供两种部署方式:裸金属与虚拟化。虚拟机部署适合小数据量、性能要求不高的应用场景,提升服务器资源利用率;裸金属部署适合大数据量、高性能场景,提升用户业务能力。 -
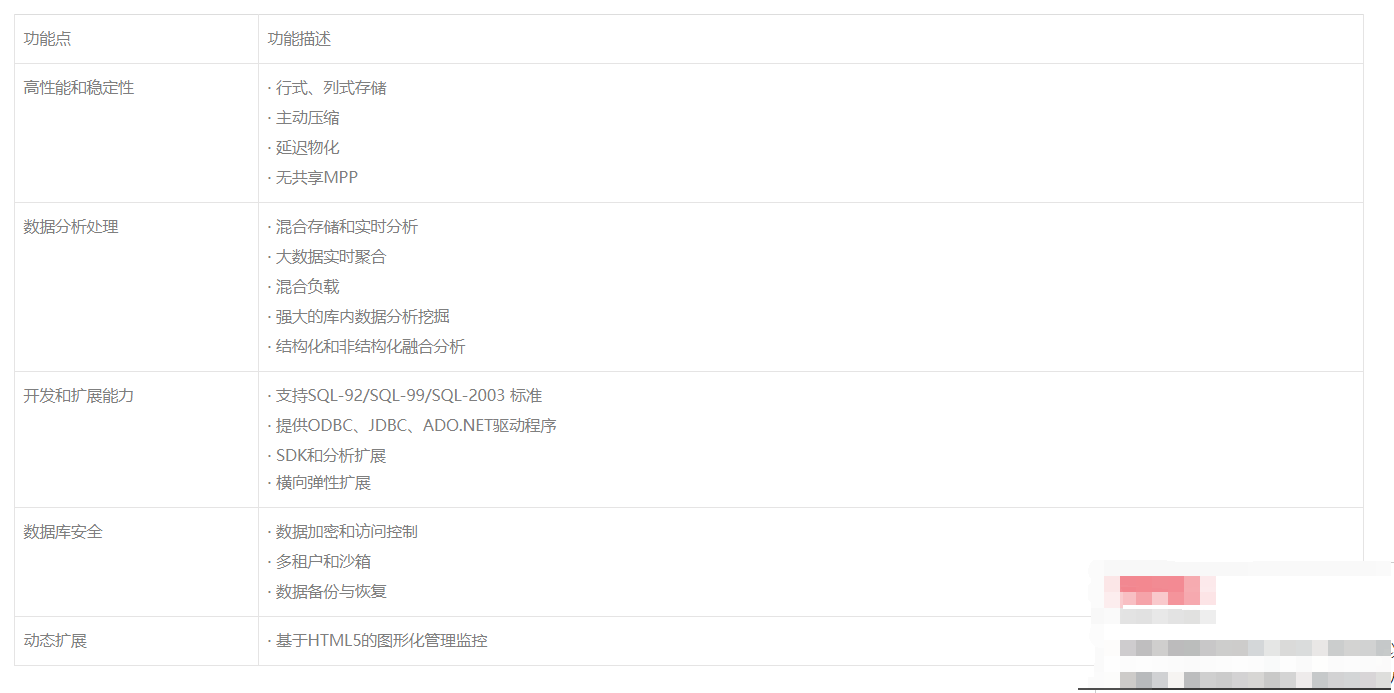
MPP交互式查询
安全认证和权限管理
为保障用户的数据信息安全,DataEngine集成了用户身份认证和权限管理功能,在创建大数据集群时根据实际需求进行启用安全管理即可。
开启安全管理的集群统一使用Kerberos认证协议进行安全认证,kerberos认证支持密码认证和keytab认证两种模式,集群管理员可在用户管理模块为集群使用者分配用户和设置认证密码,避免外部用户登录集群,提高集群安全性。
由于集群每个特定用户可能拥有集群资源的不同访问和使用权限,为保护不同业务数据的信息安全,安全集群利用Ranger进行鉴权,确保认证用户拥有集群资源的访问权限。如果用户权限不足,需要管理员为用户授予对应资源的权限后才能进行访问。