




目录
产品介绍
KaiwuDB - 分布式多模数据库
产品介绍
KaiwuDB 是一款分布式、多模融合,支持原生 AI 的数据库产品,拥有就地计算重点技术,具备高速写入、极速查询、SQL 支持、随需压缩、智能预计算、订阅发布、集群部署等特性,具有稳定安全、高可用、易运维等特点。
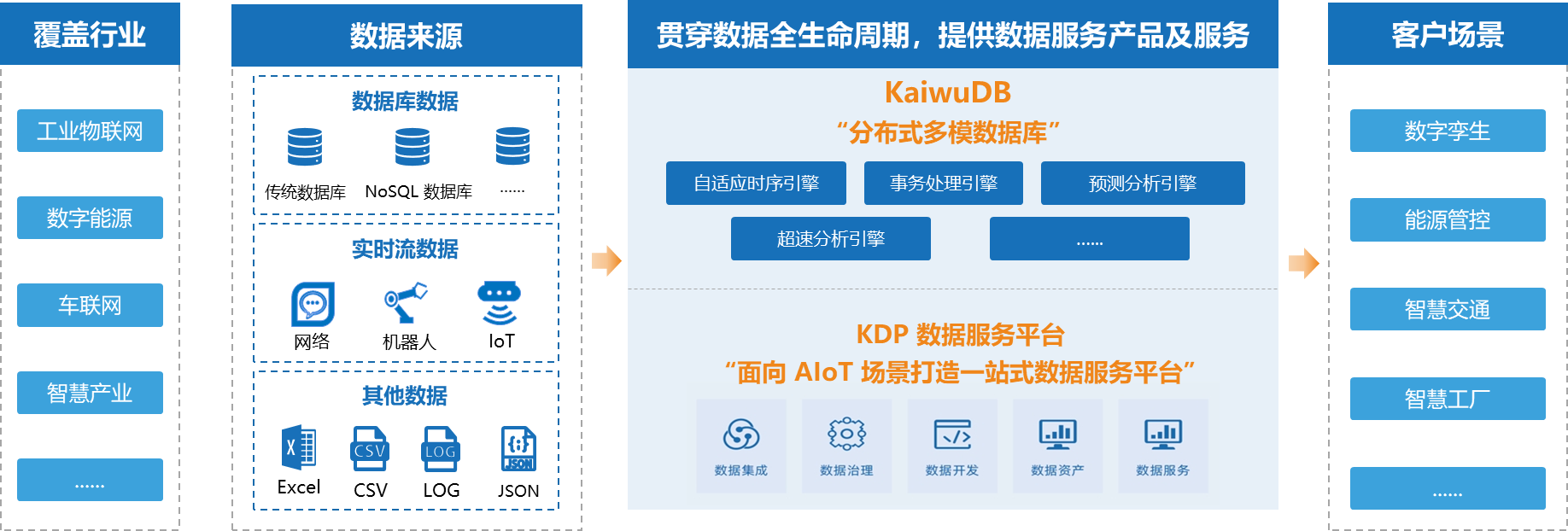

产品特性
- 高性能写入:依托“就地计算”重点技术实现高性能读写,支持百万级,甚至千万级记录秒级写入;支持毫秒级精度数据写入;
- 实时查询与分析:支持数据实时分析,千万笔数据聚合查询毫秒级响应,提供丰富的函数支持能力;
- 多模数据支持:时序型数据、关系型数据采、存、算、管;支持数据跨模分析;
- 低成本:10 -100 倍数据压缩;数据降采样存储;按“时间热度” 进行数据生命周期管理;
- 流式计算:支持多种物联网应用场景下流式计算功能;支持连续查询、数据订阅发布功能;
- 云边端一体化:支持端侧轻量化部署;具备集群部署、数据同步、数据订阅等能力,支撑云边端一体化建设;
- 多重安全性保障:支持身份鉴权、权限管理、数据库审计;支持通信加密、数据加密;兼容主流芯片和操作系统;
- 高可用及灾备:数据库层面的灾备和高可用能力建设;数据库自治等 AIOps 能力;
- 高兼容性:兼容 PostgreSQL 数据类型、SQL 语法和协议;支持 HTTP 协议;提供 Restful API;支持 ODBC/JDBC 接口;提供多种编程语言接口。
KDP(数据服务平台)
产品介绍
KDP 是一款面向 AIoT 场景的数据服务平台——以一体多模的大数据基础平台作为基座,提供 OLTP、OLAP、HTAP、时序、图、全文检索、宽表等多种数据存储和计算服务;此外,还提供上层数据集成、数据开发、数据治理、数据共享、数据可视化、智能 BI 等功能,满足企事业单位数据湖、数据仓库、数据开发、数据治理、数据共享、数据可视化、智能 BI 等多样需求,助力企业激活数据价值,赋能上层应用建设,打造行业知识中心,提供知识构建能力,支撑行业资产构建。
产品优势
- 多样的部署方式:充分考虑行业数据安全与隐私问题,KaiwuDB 提供本地化/云部署的灵活部署方式,满足用户不同场景业务需求;
- 快速响应的时序数据分析:联合 KaiwuDB 优化时序数据处理响应速度,在基础的数据分析能力上支持时序数据分析展示,动态检测场景异常并支持设置报警、数据回溯;
- 便捷的数据分析共享:提供大量数据分析图表模板,通过勾选快、拖拽速完成在线数据视图搭建,并实时预览预览搭建结果,并支持一键分享,帮助分析师、团队快速决策;
- 系统化的权限控制体系:支持登录、页面级别、工作空间、行级、列级权限控制颗粒度,支持不同角色、账号的权限控制,支持所有分享内容的权限管理。
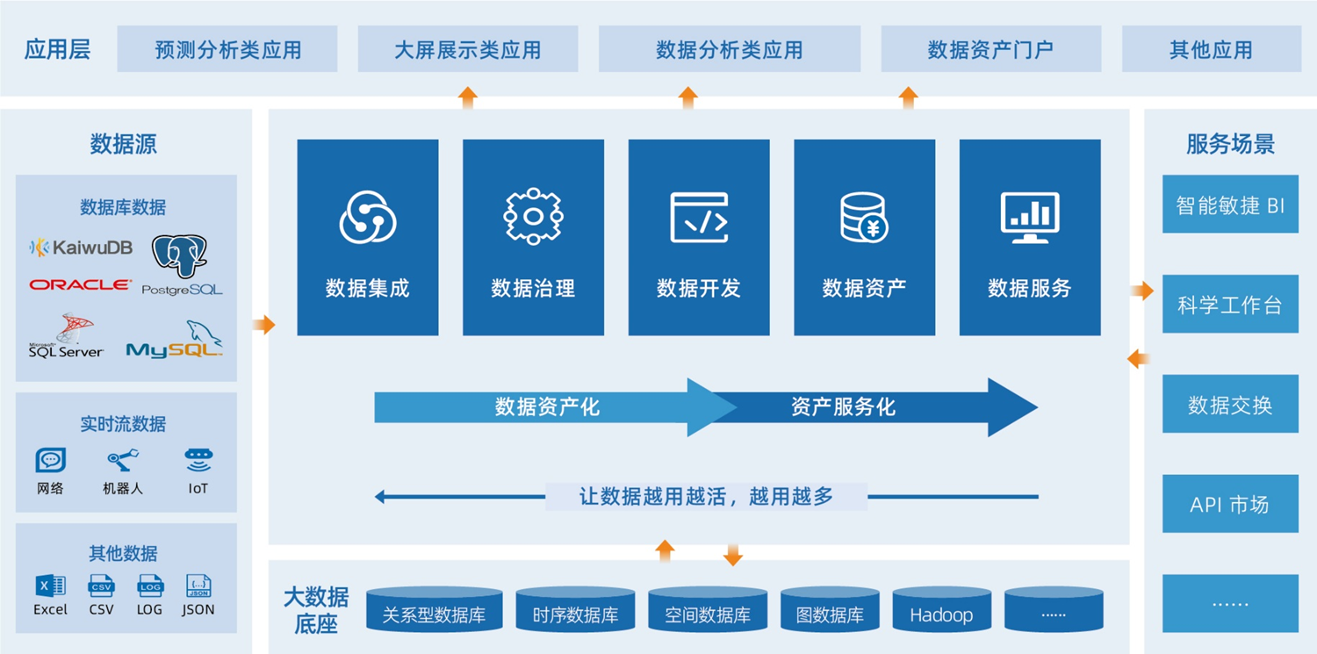
生态工具集
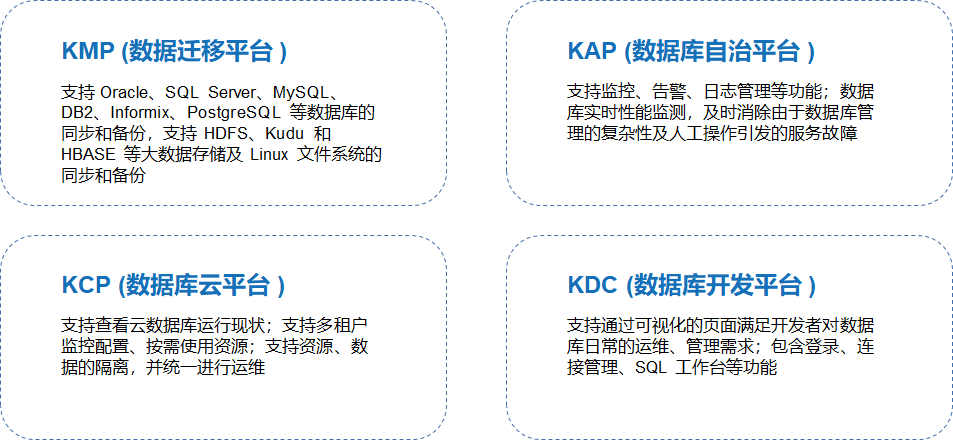
为更好地满足企业在数据全生命周期的不同需求,KaiwuDB 自主研发了 KMP(数据迁移平台)、KAP(数据库自治平台)、KCP(数据库云平台)、KDC(数据库开发平台) 4 大生态工具,搭配完整的生态服务体系,提升企业研发效率,为业务顺利开展保驾护航。
应用场景
一、工业物联网
行业背景
工业物联网场景下,数据是最重要的资源之一,企业需要对各种机器、设备和传感器产生的时序数据进行采集、存储与分析。上述场景对数据库提出了包括高可靠性、实时性、大规模、高并发、高精度、易扩展等在内的各种要求。同时,这些数据也带来了新的挑战,如数据安全、数据质量、数据管理等。
痛点与挑战
- 海量工业数据采集难:针对海量设备数据进行采集,且采集精度需达毫秒级,每秒钟可能产生上百万条数据;需具备足够的数据处理能力;此外还需考虑新增设备等更多场景;
- 工业数据存储成本高:海量数据需进行长达 5-10 年长周期保存,存储成本大、负担重工业数据质量问题:由于工业物联网场景的特殊性,传感器易受环境噪声、温度变化、电磁干扰等因素影响,导致数据存在诸如缺失、异常、重复、乱序等严重问题;
- 工业系统对数据实时分析存在极高要求:工业物联网场景数据需要实时处理和分析,以实现设备调度、预警系统等功能;
- 对高可靠性要求高:工业物联网系统对数据的可靠性和稳定性有着极高的要求;
- 工业数据安全要求高:根据“数字中国”和“数据要素”的建设要求,需重点加强工业领域数据安全建设;
- 工业数据孤岛严重:数据烟囱、数据孤岛相对严重,数据无法充分融合,数据指标不统一,数据存在重复建设;
- 现有工业实时数据库普遍存在的问题:价格昂贵,架构陈旧,可扩展性差。
解决方案
- KaiwuDB 提供了面向海量时序数据的高速、高吞吐写入,并结合就地计算、流计算、预计算、集群部署等技术,支撑超速聚合查询分析,服务各种工业软件、大数据平台、物联网平台以及数据中台建设;
- KDP(数据服务平台)适配各种协议,实现对异构数据源的采集;同时,KDP 对数据进行多维度、深层次的探索分析,广泛应用在生产调度、设备管理、经营分析、预测分析、数据可视化呈现等诸多业务环节,提供多样的数据支撑服务。
方案价值
- KaiwuDB 支持毫秒级数据快速入库,单节点每秒百万级,通过“就地计算”重点技术,能极大提升数据读写性能;支持多种聚合查询,针对千万级数据可实现毫秒级的响应;
- KaiwuDB 具备超过 10 倍的数据压缩能力,完善的数据生命周期管理及降采样查询能力可将存储成本降低 90%,支持多模,可实现一套数据库应对多种数据存储和计算场景,构建统一数据共享存储;云边端一体化建设,降低系统的复杂度和冗余度,降低系统建设和人工成本;
- 可大幅提升了企业精细化生产的能力、风险预警即时性、设备运维管理水平、设备利用率及质量监测效果,通过流式计算及数据分析能力,将脏数据、乱序数据进行清理和调整,提升数据质量,方便后续用于数据建模分析、机器学习、AI 训练等场景;
- 通过数据库运维权限管理、加密通信、数据加密等技术充分保障数据安全;
- 支持高可用架构,实现数据库层面的高可用和灾备;
- 面对工业行业各地数据打通难的问题,KaiwuDB 可提供集群部署方案,提供数据同步、数据订阅模块、标准的 JDBC/ODBC 接入方式和 Restful API 接口,赋予企业数据中台搭建能力,让数据实现“统一汇聚、统一分析、统一治理”,避免数据割裂、数据指标不一致、数据能力重复建设等问题;
- 助力企业可视化呈现数据实时分析结果,协助打造透明化工厂。
二、数字能源
行业背景
数字能源通常泛指基于数字技术和信息化手段,对能源的生产、传输、储存、使用等环节进行升级管理,以提高能源生产和利用效率,降低生产成本,减少环境污染。近几年,国家大力推动互联网、智能化技术与电力系统的融合发展,能源数字化发展离不开数据采集、存储、计算、应用等,同时也对上述流程提出更高的需求与挑战。
痛点与挑战
- 传统数据库性能无法满足数据采集需求:数字能源系统需要采集大量产能设备、传输设备、用能设备的实时数据,如能源产量、负荷、温度、湿度、风速等,数据量大且采集频率高,传统数据库无法满足性能要求;
- 长周期数据存储成本高昂:数字能源系统需要存储海量的时序数据,且存储周期长,急需降低存储成本时序数据;
- 高效分析性能薄弱:数字能源系统需对大量时序数据进行实时计算与聚合分析,要求计算速度快、精度高、结果可靠;传统数据库无法提供对时序数据的高效分析能力,存在建设周期长,成本高,组件多,运维难等问题;
- 数据质量与服务可用性要求高:数字能源系统需要将时序数据应用于各个环节,如能源生产、负荷预测、能源优化调度、需求侧响应、电力市场交易等,对数据质量和服务可用性的要求更高;
- 数据安全可控建设需求迫在眉睫:传统数据库安全能力偏弱,国外工业实时数据库存在闭源、价格昂贵、架构陈旧、可扩展性差等弊端,数据安全无法保证;加之能源行业“数据库替换”趋势不断深化,尤其在微电网管理、虚拟电厂等场景,迫切需要在数据安全和可控层面进行全局部署建设。
解决方案
KaiwuDB 可通过 AIoT 多模数据库的能力建设,将传感器、生产状况、机器运行状态等时序数据与人员信息、设备信息、业务数据等关系类数据统一汇聚,集中处理。
同时,KaiwuDB 可提供强大的跨模计算、交互查询能力支持能源领域“云边端架构”,针对分布式储能等场景提供适配性架构,提出适配低端能源工控机、物联网关的部署方案、云端高配服务器部署方案。
此外可提供云边端数据同步、数据订阅、集群管理等功能结合 KDP 的数据服务能力可实现能源数据全面统管,保证数据质量,提高数据服务可用性可提供云原生数据库产品解决方案,包含能源路由器、能源行业云的产品及服务。
方案价值
- 单节点支持每秒百万级数据入库,千万数据毫秒级复杂聚合查询,提供一站式多模数据存储和计算服务,提高能源数据流转和实时监管能力;
- 基于集群部署方案,搭配数据同步、数据订阅功能模块,赋能企业快速完成数据中台能力搭建,实现数据统一汇聚、统一分析、统一治理,有效避免数据割裂、数据指标不一致、数据能力重复建设的问题;
- 通过数据清洗、乱序数据处理等方式大幅提升数据质量和可用性,充分支撑 BI 分析、AI 训练等数据应用场景;
- 提供强大的时序数据聚合分析和跨模计算能力,可满足能源场景下对能源效率关系等跨模分析需求;支持对接能源大数据平台,提供 Flink、Spark、Hadoop 等大数据组件接口,运用 KaiwuDB 强大的时序数据分析能力,增强能源行业在发电、变电、输电、配电环境的风险预警能力,提升能源利用效率;
- 通过数据压缩、降采样函数、数据生命周期管理降低存储成本;在系统层面简化数据服务架构;依托 KaiwuDB 的多模能力和 KDP 数据服务平台功能,助力能源行业客户精准实施削峰填谷措施,实现降本增效;
- 通过数据库运维权限管理、加密通信、数据加密等技术充分保障数据安全。
三、车联网
行业背景
随着 IoT 技术的快速发展,车联网正在迅速普及和发展,成为了智慧城市的重要组成部分。在车联网中,数据包括:实时性高、数据量大、类型多样、时效性要求高、交互性强、安全保密性要求高等特点,这些数据的持续生成和传输对数据管理提出了崭新要求。
车联网系统需要快速实现海量数据的分析和处理,以获取更多有价值的数据并进行快速决策。因此,需要一个能够处理海量、实时、模块化数据的管理系统,来满足车联网所需的各种数据处理、应用等方面的业务需求。
痛点与挑战
- 自动驾驶中控及调度平台对实时计算与分析需求强烈:车辆行驶过程对数据汇入和处理实时性要求较高,需要对可能发生的风险情况做出预警,以充分保障行车安全,避免突发事件;
- 传统数据库应对大量多模态数据的能力匮乏:车联网场景下需要采集和存储车辆状态、行驶状态、驾驶行为、机械参数、电气参数、行车轨迹、ADAS、道路状况等时序数据以及 GIS 信息等,传统数据库难以应对并处理如此大量的多模态数据;
- 智能网联车数据智能分析诉求日益增加:时序数据库可对采集的时序数据进行分析、建模和预测,用于实现驾驶行为识别、交通拥堵预测、车辆健康管理等多种应用,对数据的质量和数据服务可用性提高了相应的要求;
- BI 可视化分析助力城市交通管理:数据汇聚分析并通过可视化展示工具,直观地呈现车辆状态、道路状况、交通流等信息,提供多样化的车辆数据报告助力城市交通管理。
解决方案
- KaiwuDB 提供灵活多侧的部署方案,可部署在公有云、线下 IDC 以及车机端、后装工控机。根据业务诉求,可提供云-边-端、云-端、集群等架构方案;
- 通过 KDP 支持接入网关的多种协议,实现多源异构数据高并发、实时写入 KaiwuDB。凭借 KDP 的多维分析及预测能力,车联网系统可对车端数据进行综合分析及预测,实现对车与车、车与路、车与人及车内的全方位感知,及时纠正驾驶员行为;同时对车辆机电、性能风险及路况风险等做出预测,为应急和救援系统提供有力支持。
方案价值
- KaiwuDB 支持数据快速汇聚,及通过高速通道入库;通过“就地计算”重点技术,可大幅提升数据读写性能;支持多种聚合查询,针对千万级数据可实现毫秒级的响应。针对车机零部件,车况状态,电池状态,驾驶行为存在的风险可实现提前预警,降低事故发生的概率,提高道路通行流畅度,优化车联网系统的决策效果;
- 支持核心数据加密存储、加密传输、统一权限管控,结合 KDP 的数据安全策略,助力企业在使用数据的同时,保障人员信息、车辆数据等机密、隐私数据安全,避免数据泄露、黑客攻击等安全问题;
- KaiwuDB 可提供智能 API、模型建立工具等,对大数据进行模型建立和训练,激发数据价值,对车联网系统中的车辆状态、驾驶行为、路况状况进行预测 ;
- KaiwuDB 数据压缩超过 10 倍,结合完善的数据生命周期管理及降采样查询能力可将存储成本降低 90%;多模架构可实现一套数据库应对多种数据存储和计算场景,构建统一的数据共享存储;云边端一体化建设,降低系统的复杂度和冗余度,减少系统建设和人工成本;
- KaiwuDB 支持关系型数据与时序数据交互查询,提供流式计算,将实时汇聚的车辆、人、道路等数据展开流水线化分析,持续将分析结果推送到 BI 端;KDP 可提供图表、报表可视化、数据驾驶舱功能,并开放相应数据服务 接口,支持二开,大幅降低车联网场景构建实时大屏实现 BI 可视化的门槛;
- 相对于构建 CDH,KaiwuDB 通过轻量化投入即可达到满足业务场景的大数据分析水平。
四、智慧矿山
行业背景
随着勘探和矿产开发技术的提高以及能源需求量的大幅增加,矿山开发速度持续加快。随之而来的诸多弊端,如矿山资源综合利用率低、管理方式粗放、安全和环境污染等问题日益突出,使得矿业智能化建设迫在眉睫。
近年来,政府机构十分重视采矿行业数字化建设,明确提出加快建设自动化、信息化、智能化的矿山,促进矿山产业向“安全、绿色、高效”转型升级。在转型升级发展的过程中,矿山企业面临生产安全形势严峻、数据采集困难等诸多挑战。通过智慧矿山建设,可实现生产控制少人化无人化、生产管理智能化、安全管理本质化;是全面提升矿山企业综合竞争力和可持续发展能力的关键路径之一。
痛点与挑战
- 生产安全面临严峻形势:由于矿山的生产环境特点,潜在隐患风险不易察觉。相较于发达国家,我国在生产自动化与智能化水平上仍有较大差距。矿山生产涉及设备采集点位多、作业人员多,急需通过数字化建设提升安全能力,保障资源开采和生产管理,降低灾害和事故频率;
- 系统对数据处理性能要求高:矿产开采需对设备和人员进行实时监控与管理。在设备监控、设备告警、生产预警分析、人员实时状态、应急处置等多种应用场景,数据处理的实时性势必要争取大幅提升用以满足需求;
- 数据价值难以有效挖掘:传统矿山信息化系统烟囱式部署,系统融合度较差,无法将数据有效汇聚,并进行深层次数据价值挖掘;
- 数据的高可用及可靠性受到挑战:受矿山地理位置及环境影响,数据采集与汇聚容易受到网络不稳定因素影响,从而产生数据丢失、数据乱序等情况,严重影响人、设备、资源三方面的安全监测、运营管理和开采作业。
解决方案
- 一库多用,支持多模异构数据的存储:KaiwuDB 支持关系型数据、时序数据、地理位置数据等多种数据类型存储。以一套数据库打通在采、选、冶、产、供、销全流程下多个业务系统对数据的计算与分析能力;
- 提供高性能数据处理能力:利用 KaiwuDB 的就地计算专利、智能预计算等重点技术,可实现批量、高速、复杂查询的快速响应,千万级数据查询响应可达毫秒级,实现对采集到的数据进行精准快速响应,保障安全生产与经营;
- 多样化的数据查询能力助力数字化系统建设:KaiwuDB 支持流式计算、数据订阅发布、多种聚合查询、最新值查询等功能,可实现数据清洗、加工及实时性展示;可为矿山数字化系统人员实时状态、设备运行状态、生产经营等业务场景提供支撑;
- 支持数据深层次分析挖掘:KaiwuDB 和 KDP 提供数据实时处理、分析、报表展现、定制数据服务、AI及预测分析模型能力,提供快速精准的实时计算和分析能力,助力设备预测性维护、气体预测性分析、管理经营数据预测性分析等场景需求,提升矿山生产安全水平,保障人员生产安全;
- 助力企业降本增效:依托 KaiwuDB 计算能力和 KDP 实现数据的多样化展示与管理,充分发挥数据实效性,降低安全隐患,降低数字化系统复杂度,节约建设和人员运维成本;
- 支持数据压缩和完整生命周期管理:支持数据降采样存储,支持时序数据 10 倍及以上的压缩,大幅降低数据存储成本;数据生命周期管理功能的数据分级治理,可实现对数据的管理归档,有效节省数据存储空间。
方案价值
- 以就地计算为核心支撑对矿区数据的高速汇聚、快速处理、实时分析,深层次挖掘数据价值,助力智慧矿山的数字化、智能化建设;
- 保障一线人员的生命安全、职业健康以及设备的安全运行,实现复杂环境下的数据存储与管理的可靠性、稳定性,提升矿山数字化建设和安全管控水平助力安全生产提质增效;
- 可视化界面数据库管理,无需技术人员即可实现数据库内部管理操作,便捷易上手;可视化数据探索工具可帮助实现数据的多维度探索与数据分析展示,辅助矿区设备调优及综合决策;
- 强大的基础数据能力,可加快建设以数据技术驱动智能决策,建成本质安全、资源集约、绿色高效的智慧矿山。
公司介绍
上海沄熹科技有限公司是浪潮控股的数据库企业,汇聚了全球顶尖的数据库人才,面向工业物联网、数字能源、车联网、智慧产业等各大行业领域,提供稳定安全、高性能、易运维的创新数据软件与服务,一站式满足 AIoT 等场景下数据管理需求及关键行业核心系统的自主可控需求。
公司拥有就地计算、多模数据库架构、分布式计算、超速分析引擎、云边端协同、原生 AI、数据库自治优化、自适应时序引擎 8 项重点技术;产品体系囊括自主研发的分布式多模数据库 KaiwuDB 及数据服务平台 KDP等。
KaiwuDB研发团队遍布上海、北京、济南、天津等地,高精尖人才占比超过 50%。截至目前,产品已通过信息技术产品自主原创性测评,成功突破 8 项重点技术,累积获得 16 项自有产品软著,近 300 项发明专利受理。
当前,公司已在工业物联网、数字能源、数字政务、金融等多行业成功完成落地实践;未来,将能够为包括上述各大行业领域提供数字化赋能,助力企业从数据中挖掘更大的商业价值。
相关资料
KaiwuDB官网:https://kaiwudb.com

欢迎扫码关注 KaiwuDB
