




一.haisql_memcache优点
主要优点:比Redis和memcached更快,比Memcached更多功能,支持事务,支持微线程,支持pipeling,支持UDP,支持数据日志,支持掉电保护的高性能KV数据库,具有高并发性,性能非常快,是常规数据库的10倍以上,同时haisql_memcache兼容memcached指令集,包括返回的内容和错误提示均一致,可作为一个特殊版本的服务器直接与memcached客户端相连接。
测试 KV 数据包大小4.1Kbyte, 4核8线程3.4G主频DDR3内存,读900万次数据,900并发,读性能38万QPS,比memcache快64%;写100万次数据, 100并发,写性能32万TPS,比memcache快30%。
数据结构比较简单,因为是内存数据库,全部数据都在内存中,各类操作简单到了极致,全部都是文本格式,包括日志在内,都一样。
因为是内存数据库不需要读磁盘,这个产品没有使用file_mapping等磁盘读技术,磁盘IO只使用了C++ iofstream。
各种逻辑处理也比较简单,例如:
日常的更新删除插入操作,要写日志,日志内容就是set指令和delete指令。
在正常退出的时候,将全部数据保存(更名数据表为旧,保存数据,保存成功删除旧数据表),如果全部数据表都保存成功,就清空日志。
在启动时,先检查是否存在旧数据表,如果存在,读取旧数据表,再读取日志,否则,直接读取新数据表就可以.
1.1支持数据日志,支持数据的掉电保护
haisql_memcache支持日志功能,当服务器突然断电时造成的损失,意外关闭造成的损失,只要存在数据日志,就可以通过利用它来恢复数据,轻松排除数据库故障.在系统崩溃/故障等情况下,可以保证数据库的一致性,从而提高了数据库的可靠性。
故障一:服务器突然断电造成的损失
服务器如果因为突然断电或者其他一些原因意外关机时,再重新启动服务器后会出现一些数据的损失,这是因为数据库中的数据发生更改后,并不会在第一时间就把数据写入到硬盘中,为了提高数据库的运行效率,往往是先把数据写入到数据高速缓存中,同时把更改情况写入到日志中,等到一定情况数据库系统才会把数据写日到硬盘文件中,此时,如果数据库系统突然发生断电或故障,数据库系统很有可能还没有把缓存中的修改后的数据写入到硬盘中,而日志文件的存在,支持了掉电恢复,即当重新启动时,系统会对每个数据库执行恢复操作,将日志中每个未完成的事务都将回调,以确保数据库数据的完整性.
故障二:解决服务器意外关闭造成的损失
有时候出于数据库高可用性的目的,需要在生产服务器之外的地方再部署一台数据库服务器,当生产服务器出现故障不可用时,则可以马上启用这个备用的服务器,所以就需要保证生产服务器与备用服务器之间数据的同步,而haisql_memcache数据库就是通过日志的复制来实现生产服务器与备用服务器之间的同步的.生产服务器将生产数据库的活动日志发送到一个或多个目标服务器,每个辅助服务器将该日志还原为其本地的辅助数据库,从而实现备用服务器与生产服务器之间数据的一致性.
1.2支持微线程
乌鲁木齐云山云海信息技术有限公司对于多线程的任务调度方向主要的思路是实现stackless 用户态微线程,通过C++函数对象, 使得一些状态可以保存到成员变量中. C++的函数对象, 既可以像普通函数那样调用, 又可以像通常的对象那样携带成员变量. 因此通过将变量置于对象而不是栈上, 并且通过用户态的任务队列,C++就可以实现无栈用户态微线程. 微线程的开销不过就是一个函数对象, 通常大小不过几个字节到几KB字节. 因此无栈用户态微线程无需当心内存开销,也没有CPU线程切换的开销,性能非常好.
微线程的优点:
(1)消耗小, 切换快, 一个进程可以创建成千上万个微线程.
(2)小任务顺序编程很符合人的思维方式, 规避纯异步编程中状态机的复杂性. 使得使用微线程写的程序将更加的直观, 逻辑描述方便, 简化编程.纤程用于化异步为同步, 你可以进行一个异步操作以后就切换纤程,等到异步操作完成以后在切换回来,这样,在逻辑上相关的代码就可以写到一个函数里面,而不用人为的分到多个回调函数中.
(3)每个CPU只绑定一个线程,每个线程处理多个微线程的TCP/IP数据包,形成一个N个CPU:M个连接的方案,这样就完全避免了线程的切换,极大的提高了网络层的并发量.
1.3支持pipeling
pipeling介绍:管道传输(pipelining):用于一次性处理多条haisql_memcache命令.
haisql_memcache的执行流程为客户端发送命令到服务端,客服端阻塞等待服务端程序返回,如果中间由于网络通信问题导致速度比较慢,另外由于客户端和服务端的数据传输需要一定的时间。这个 时间叫做RTT,Round Trip Time 。如果有很多条命令要一次性传输,相对来说就会比较慢,haisql_memcache提供了pipelining命令来处理.pipeling在传统的命令传输方式上,允许客户端发送多条命令可以减少传输过程中消耗的时间.
1.4高并发性
为了保证数据库的一致性和完整性,在逻辑设计的时候往往会设计过多的表间关联,尽可能的降低数据的冗余,如果数据冗余低,数据的完整性容易得到保证,提高了数据吞吐速度,保证了数据的完整性,清楚地表达数据元素之间的关系。而对于多表之间的关联查询(尤其是大数据表)时,其性能将会降低,同时也增加了客户端程序的编程难度,使得程序的变得复杂,因此为了提高系统的响应时间,保证数据库的一致性和完整性,数据库具有高并发处理的性能非常重要.
1.5比memcached快
主要体现在:
1.对版本进行了一些优化,取消了对数据库内存大小的限制,减少了程序的开销,提高了性能。
2.优化了set,get指令,加快了数据包转发的速度,查询性能已经超过了memcached,更新性能也已经超过了memcached,目前KV数据库查询性能比memcache高64%,更新插入性能高30%。
1.6性能非常快
主要体现在:
(1)无随机写的数据结构:
采用了类似LevelDb的 数据分层技术, 一次性顺序写入, 以及 不断合并技术, 实现完全消灭随机写, 只有顺序写+随机读, 对SSD的寿命有很大提高, 也可以实现最大化的写入速度, 实现极高的插入性能。在数据结构的设计上采用了类似innodb 日志offset 作为事务进度的指标,以及commit事务隔离的思路, 并在自己的代码中也采用类似的技术思路, 为今后实现标准SQL所需要的MVCC,以及事务处理,多机主备同步做好准备, 这样可以在不改变数据结构的基础上,先开发NOSQL,后开发标准的SQL数据库, 实现平滑过渡。
(2)高性能hash KV索引
内存中只存放索引, 减少物理内存占用, 今后数据由File Mapping缓冲, 利用SSD的极高随机读性能, 单机实现10亿级别以上数据量的高性能处理。为了验证测试这一部分代码,已经实现了一个与memcached命令集兼容的内存数据库,重点测试和验证高性能hash索引,以及CPU任务调度, 内存管理等方面的综合性能,这部分代码刚开发完主要功能模块,初步测试性能与最快的内存数据库memcached很接近,刚开发出来的C++版本性能是单连接每秒6万TPS, 多连接数十万TPS。其中公司开发的基于模板的Circle_hash_map比目前最快的std::unordered_map库各项综合性能要高70%以上。
(3)高性能Lock_free/Wait_free队列
多线程之间免不了数据交换,典型的就是队列,传统的队列是有锁队列,并发度为1,这个是第一代队列。更先进的就是基于cas指令的lock_free队列,性能要高不少,开源软件有不少,这个是第二代产品。最先进的第三代队列是双端同时并发的无等待wait_free架构,wait_free架构没有完整的开源实现,比以前的产品快很多,性能超高,单生产者单消费者队列每秒3亿,各公司均保密。我厂这部分代码wait_free架构超过5000行代码,实现了多生产者和多消费者模型无等待并发模型。
目前项目组测试了比较前沿的,国内还很少实践的 Lock_free, Wait_free 高性能无锁无等待队列技术, 作为线程间通讯方案。已经开发出的无锁无等待队列比先进的Boost库中最快的无锁无等待队列Boost lock_free spsc queue快30%以上,并且支持更多线程的并发,支持任意对象的调度,测试性能是:单spsc队列的整数数据传输能力是3亿TPS,任务双向调度能力1400万TPS(等效单向调度2800万TPS), 包括生产者push, 消费者pop,消费者处理,回调生产者4个流程的总调度,性能非常突出, 是Boost这样的准标准库任务队列性能的9倍以上,是操作系统任务调度能力的200多倍。
(4)高性能压缩LZ4
目前项目组主要封装和测试了目前压缩和解压缩速度最快的压缩工具包LZ4, 作为存储层的压缩工具, 以便减少IO流量, 增加缓冲的效率, 进而提供更快的IO性能. 测试每秒解压缩性能500MByte. 是传统解压缩的数倍性能。
(5)性能快且线程安全的shared_ptr
多线程下必须使用智能指针,智能指针第一代就是类似std::shared_ptr这种,引入make_shared打了个性能补丁,快了一些。std::shared_ptr不是完全线程安全的。第二代智能指针std::atomic_shared_ptr目测c++20可能会引入,实现了完全线程安全。其实第二代智能指针很多公司早都在用了,一些游戏公司十多年前就都在使用自研的更安全的产品,完全线程安全。我厂也研发实现了第二代智能指针,性能比第一代快一倍,完全线程安全,并进一步实现了第三代智能指针,完成了类似java gc功能,但是比java更快的模型,减少了析构的开销,使得使用智能指针比裸指针更高的性能,并且使用方法上与std::shared_ptr一样,全兼容第一代智能指针。
目前已经开发并测试完成的下一代高性能线程安全的共享指针shared_ptr模型.使用了大量创新的超前技,与现有shared_ptr/ weak_ptr/enable_shared_from_this/make_shared 在写法上完全兼容,可以简单无缝切换std/boost 库的相关对象.新的 shared_ptr 具备单写多读的线程安全特性,大大方便了多线程程序的开发, 只需要保证最多只有一个线程写这个shared_ptr,就可以保证所有读操作的安全性,同时还可以使用引用方式 &shared_ptr来传送数据,减少调用过程的 increase_count 和 decrease_count;使用创建一个新shared_ptr,赋值给旧的 shared_ptr,这整个过程都是无锁的,没有读并发冲突,大大提高了性能,比std库的智能指针(shared_ptr/unique_ptr等)快一倍以上.
(6)自研新型hash_map/set
自研新型hash_map/set,基于环形队列的新型hash_map/ set库,比std::unordered_map更快,且rehash性能抖动小的自主研发的高性能circular_hash_map 库。环形队列大小自动收缩扩展,性能比std::unordered_map快70%.
####(7)高性能CRC校验
目前项目组主要封装和测试了intel CPU 内置的crc32c硬件校验技术(intel SSE4.2指令), 生成64bit校验码的速度是, 测试性能是每秒1.6GByte输入,基本就是读内存的速度,是目前最快的CRC校验生成速度。
(8)stackless微线程
实现微线程/协程架构,微线程分为stackful和stackless两种,目前开源多数都是stackful的。我厂实现stackless的微线程,理论上推测可以有更大的性能潜力,stackless不需要栈的切换,所以理论性能更高,stackless架构目前没有完整的开源架构。我厂是完全自研的,当时是看重了该模型的理论推测性能更高,实现难度也更高,各公司均保密。仅仅是微线程架构,也需要不少的代码量。微线程架构减少了线程切换的开销,性能比传统架构高很多。
(9)高性能spin_lock
多线程下高性能锁/多功能锁类似facebook开源c++库folly里面的高性能多功能锁,基本上每家公司都有类似的实现。课本上那些spin_lock的设计都是玩具级别的,性能也差。各公司在这块都有独自的特色,以前各公司均保密,自从facebook开源后,高性能多功能锁技术就扩散了一部分技术出来,但是还是有一些第二代锁的先进技术不为公众所知,总之第二代技术的锁比第一代std库的锁快功能也多,我厂也实现了类似的库,性能远超std::mutex等常规锁,也有类似folly的读写锁,支持读锁升级为写锁,支持写锁降级为读锁等等功能,兼容std::lock_guard等加锁构件。
二.关于日志的多个写请求的写合并技术介绍
1)不保存日志的情况下,在低端4核CPU下,可以实现32万TPS的更新或者插入性能.
2)保存日志,每秒刷新一次,或者,空闲时刷新日志,log日志单独线程处理,因此,有更快的速度,更多的合并写,提高了日志的写性能。因为是单线程处理,因此合并多个写日志的操作,非常简单.
工作方式 data_log_work_mode=3 就是 log_thread 先尽量往日志文件中写日志,直到队列中没有数据要写后,最后再flush刷新日志文件。这样有可能合并几十到几百个写请求。
主要的思路就是尽可能首先去执行写日志,而把刷新放到次要的任务,最大限度合并写请求,实现最高的性能。
3)工作方式 data_log_work_mode=6,7,8 socket的数据更新操作要等日志刷新到磁盘后,再返回命令执行结果。
内部处理的方式就是:例如:64个并发连接都在更新数据,服务器接收和处理执行完命令后socket_thread不发送数据, 也不接收数据,直到log_thread处理完log日志队列中的任务(CPU线程 直接处理下一个连接或者任务队列中的任务去了),客户端等待收执行结果中.
日志队列有数据后,log_thread被自动唤 醒后,先尽量往日志文件中写日志,同时保存好回调的socket_data,直到队列中没有数据要写后,最后再flush刷新日志文件,所有的日志都被保存到磁盘中了,这样1次磁盘写就合并了最多64个写请求,log_thread再依次按照前面保存的socket_data通知64个并发连接,socket写执行结果数据, 客户端收到执行结果(此时保证数据已经写入日志成功了).
另外其实日志的代码还有更多的优化, 日志自动合并功能, 例如:对于1000个连接在瞬间修改了同一条记录数据(类似淘宝秒杀的环节), 等待返回结果, 只要相关日志还没有保存, 还在处理队列中, 在日志层有自动合并机制, 最终只写入最后的结果,只记录了一条日志记录,然后再统一给1000个连接返回执行成功. 这些功能都是传统数据库不具备的功能点. 总之, 连接数越多, 数据冲突越大,性能越高.
三.数据库模块组件内部性能测试情况
1.TEST_COUNT=10000000次
Key值为std::string的测试情况柱形图如图:
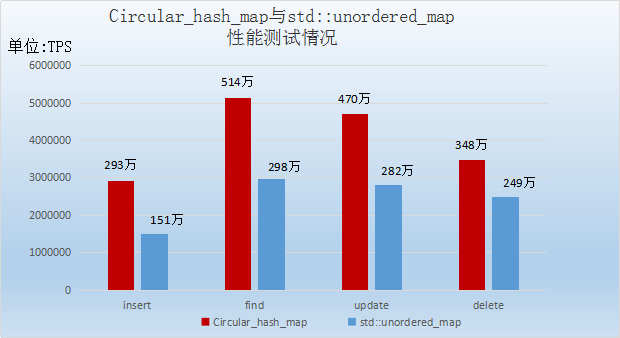
由Circular_hash_map与std::unordered_map性能测试情况柱形图可以看出:
Insert语句Circular_hash_map库比std::unordered_map库性能效率提高了94%;
find语句Circular_hash_map库比std::unordered_map库性能效率提高了72.5%;
update语句Circular_hash_map库比std::unordered_map库性能效率提高了66.7%;
delete语句Circular_hash_map库比std::unordered_map库性能效率提高了约40%;
Circular_hash_map库比std::unordered_map库整体性能效率提高了66%,远远优于std::unordered_map库。
2.Wait_free_spsc_queue c1;
boost::lockfree::spsc_queue<unsigned int, boost::lockfree::capacity<4096> > boost_spsc_queue;
TEST_COUNT=1000000000次
测试情况柱形图如图:
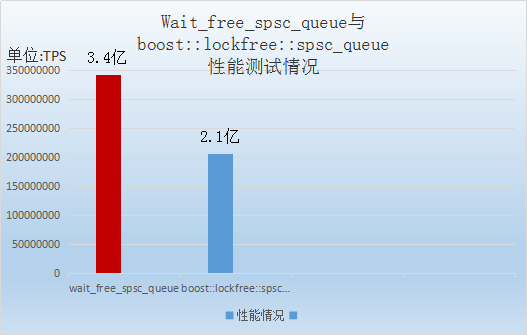
由Wait_free_spsc_queue与boost::lockfree::spsc_queue性能测试情况柱形图可以看出:
Wait_free_spsc_queue的性能比boost::lockfree::spsc_queue的性能提高了62%,性能远远超过了boost::lockfree::spsc_queue。
3.TEST_COUNT=100000000次
测试情况柱形图如图:

由Wait_free_mpsc_ios_queue与sp_ios_push->post性能测试情况柱形图可以看出:
当TEST_COUNT=100000000次时,Wait_free_mpsc_ios_queue比sp_ios_push->post的性能提高了290%。
四、haisql_memcache性能测试
1.与memcached性能对比的测试结果
1.1运行服务器
- 运行 memcached, 需要指定8192M内存, 以便可以测试百万以上的数据量, 指定端口号是1983,命令如下:
memcached -m 8192 -p 1983 - 我们的程序是动态申请内存,因此,不需要指定预先分配的内存量, 直接运行就可以了,启动运行服务器命令如下:
./haisql_memcache_chinese
我们的软件默认运行端口是1971
每次测试后需要清理运行环境, memcached直接ctrl_C退出就可以了.
我们的软件因为退出时默认自动保存内存数据, 因此,需要在退出程序后,执行 rm *.txt;sync;sync 清理掉自动保存的数据, 相当于清空全部数据,这样下次启动时就是空数据表了
1.2测试 读性能
测试软件自动写入1万条记录, 然后测试读取900万次, 我们的软件执行时间是23.631秒, memcache执行时间是38.828秒, 我们的软件比memcache快64%.
我们的软件读性能如下: 读4.1Kbyte的数据包大小, 4核8线程3.4G主频DDR3内存, 读900万次数据, 900并发, 花费时间 23.631秒, 读性能38万QPS。
1.3测试 写性能
测试软件测试写入100万条记录, 我们的软件执行时间是3.136秒, memcache执行时间是4.078秒, 我们的软件比memcache快30%.
我们的软件写性能如下: 写4.1Kbyte的数据包大小, 4核8线程3.4G主频DDR3内存, 写100万次数据, 100并发, 花费时间3.136秒, 写性能32万TPS.
2.与redis性能对比的测试结果
由于redis只支持单核,不支持多核,为了与redis的性能做比较,专门找了一台双核的机器.
Intel(R) Pentium(R) CPU G3258 @ 3.20GHz,本机127.0.0.1测试, 相当于一个CPU用于测试,一个CPU用于服务器, 以便测试对比一下与Redis的单核性能对比.
单核查询性能还是比redis更快, 先插入10000条记录,900连接,每连接10000次查询,总共测试900万次查询,每次查询value包大小4096字节,redis花费93.46秒, 我们的软件花费63.792秒, 测试方法都是官方的测试软件,我们的单核性能比redis的单核性能快 46.5%.
