




目录
1. HashData数据仓库
HashData数据仓库是一个高性能、完全托管的PB级云数据仓库服务,让企业用户能够更轻松地分析海量数据。HashData数据仓库集成MPP数据仓库超高的查询性能、云计算弹性伸缩特性以及大数据平台的综合处理能力,为企业提供云原生的数据仓库服务,并且轻松实现企业内部数据中心部署。
HashData数据仓库提供完整的SQL支持,实现了ANSI SQL 2008标准和2003 OLAP扩展,支持标准的JDBC和ODBC接口,支持自定义函数及库内机器学习。同时具备良好的兼容性和开放性,可无缝集成市场上主流ETL及BI工具。
2. HashData适用场景

3. HashData数据仓库技术架构
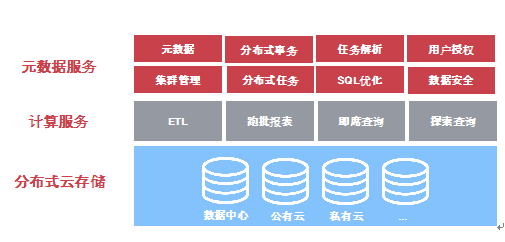
HashData数据仓库将元数据、计算和存储三者分离,高效响应高并发复杂查询,体系架构随业务需求动态伸缩,在提供高性能数据仓库服务的同时实现资源的最优配置。HashData数据仓库实现跨集群、跨数据中心以及跨云中心的数据访问,并保证数据强一致性,用户可灵活合理规划生产数据与实验数据的部署和使用。HashData数据仓库实现结构化、半结构化高价值密度数据的统一管理,为企业提供成熟稳定的大数据平台。
4. HashData数据仓库功能模块
SQL访问层
HashData的访问层负责接受用户的查询请求,解析查询语句,生成执行计划,下推执行计划,协调计算节点,以及汇总查询结果返回给用户。同时,SQL访问层也负责数据访问安全和事物管理。由于支持标准的JDBC和ODBC,用户可以通过标准的SQL客户端、BI和ETL工具以及常用编程语言访问HashData。
MPP执行架构
HashData采用大规模并行处理(MPP)架构、将数据切片分布到各个计算节点后并行处理来解决海量数据分析的难题。每个计算节点都有自己独立的CPU,内存和外部存储,负责数据的存储以及查询计划的执行。计算节点之间是没有任何共享依赖的(shared nothing),并通过基于UDP的高速数据传输协议进行数据交换。查询在每个计算节点上面流水式并行执行,大大提升了查询的效率。
云存储
HashData利用云存储作为数据持久存储层,并与计算资源物理上分离、逻辑上集成。由于自身的高可用性和近乎无限的可扩展性,云存储大大简化了数据仓库系统错误恢复、多维度扩缩容、备份恢复等流程,同时使得不同集群间共享同一份数据、统一的数据存储平台成为可能。
云服务
(1)管理控制台。通过管理控制台,用户可以方便地创建和管理多个数据仓库。
(2)监控审计。HashData对每个数据仓库进行持续监控和使用审计,方便用户实时了解数据仓库的运行和使用情况。
(3)弹性伸缩服务。HashData实现了灵活高效的数据分布策略,使得用户可以根据业务和数据量的变化,快速地动态调整数据仓库集群中计算节点的数量,以及每个计算节点的计算和存储能力。
(4)计费功能。HashData提供了根据使用量进行计费的功能,方便用户控制IT预算。
(5)基础设施管理。HashData是部署在基础设施即服务(IaaS)平台上的一个数据处理服务。通过基础设施管理服务,用户可以管理HashData与IaaS平台其他基础设施的交互,如将整个HashData集群迁移到另外一个私有网络,从而使得HashData融入所在的云生态中。
5. 产品特性
(1)数据仓库服务
“加载数据,分析数据,其它交给我们”。通过使用HashData云端数据仓库,企业用户可以在几分中内启动一个包含几十个甚至上百个节点的数据仓库集群,数据加载后马上可以开始数据分析任务。同时由于是完全托管的云服务,HashData数据仓库承担了所有的集群资源配置、数据备份、监控审计、错误恢复、高可用和升级等纷繁复杂、极易出错的运维工作,让用户专注于业务分析上面。
(2)多维度弹性
基于云平台,计算和存储物理上分离、逻辑上集成的架构使得HashData实现了多维度弹性:横向伸缩和纵向伸缩。企业用户可以根据业务和数据量的变化,动态调整数据仓库集群中计算节点的数量。我们实现了灵活高效的数据分布策略,从而使得在计算节点数量改变时数据能够快速进行重分布。同时,用户也可以在不增删节点的时候(意味着没有数据重分布),调整每个计算节点的计算(CPU和内存)和存储能力。这种多维度弹性使得用户可以使用最合适的资源处理当前业务。
(3) 超高性能
HashData的架构专门为数据仓库应用优化,从而能够提供超高性能。这些优化包括无共享大规模并行处理(MPP)、流水式执行引擎、列式存储和大表分区等技术。配合我们提供的多维度弹性,用户可以取得非常高的性价比。
(4) 兼容开源
作为云原生的数据仓库服务,HashData在PostgreSQL和Greenplum Database的基础上对系统架构和运行实现上面进行了大量深度的优化。但在查询接口(包括使用习惯)以及底层数据文件存储格式和访问协议方面,我们保持与开源系统一致。这一方面意味着用户可以充分利用已有的SQL技能和在BI和ETL工具方面的投入;另一方面意味着使用HashData完全没有应用和数据绑架的风险。
6. 新架构特点
支持多集群
HashData数据仓库支持多集群。通过多集群响应多并发的场景。同时不同的业务部门,可根据不同的业务逻辑启动集群,保证每个集群根据不同的业务特性取得最佳的资源配置,并保证了集群直接IO资源的隔离。多集群可以支持企业生产环境和测试环境统一平台建设,保证数据共享,严格的集群隔离保证了生产数据的安全性。避免企业数据平台烟囱式建设,减少数据孤岛。
-
极其优秀的扩展性
HashData数据仓库有足够弹性的架构,可以实现秒级扩容。可以及时响应业务发展带来的扩容需求。 -
GIS、IOT数据处理
HashData数据仓库更完整的支持GIS数据处理,可实现海量GIS数据分布式加载入库,支持矢量、栅格数据库内进行分布式运算、多维度聚合查询,快速响应结果。
支持IOT日志数据、标签数据直接入库处理。
-
库内机器学习、数据挖据
HashData数据仓库支持完整的OLAP函数、内置MDlib插件,支持在数据仓库内进行数据分析挖掘,并支持直接在库内进行R语言运算。 -
兼容性强
HashData数据仓库100%兼容PostgreSQL以及GreenPlum生态,可无缝对接主流ETL及BI工具,具备强大的上下游生态。 -
跨云平台访问
HashData数据仓库具备跨平台访问能力。您可以选择HashData数据仓库部署在不同的云平台上或者数据中心中,HashData可以提供统一的数据访问,并且保证数据的一致性。
