




目录
数据库介绍
X-DB 1.0(X-Cluster) 是阿里自主研发的,100% 兼容 MySQL 生态的,全球级分布式强一致的关系型数据库系统。
关于
2018年双11 是 X-DB 的第一次大考,本次双 11X-DB 服务于天猫 / 淘宝核心交易系统、核心物流系统、核心 IM 系统,经受了零点业务 32.5 万笔 / 秒峰值的性能考验(对应数据库峰值每秒破亿次的 SQL 调用);同时 X-DB 支撑起了新一代单元化架构,在分布式一致性算法 Paxos 的统一框架下,第一次提供了跨 Region 分布式强一致能力,实现高效的跨 Region 数据同步、跨 Region 容灾,保证金融级的数据质量服务。
X-DB 为了降低用户的迁移和学习成本,选择了兼容成熟的 MySQL 生态,并且做到了真正 100% 兼容 MySQL 生态,为业务,为传统数据库赋能。基于 MySQL 的业务可以无缝从 MySQL 迁移到 X-DB 上来,不需要任何评估和兼容测试,完全零成本迁移。基于 MySQL 的周边工具平台,甚至是 MySQL DBA 都可以非常平滑的转移到 X-DB 上来。阿里内部从今年 6 月初第一个业务应用灰度切流,到目前为止 5 个月的时间里,X-DB 已覆盖了阿里集团及多个关联公司旗下的多个事业群,为海量的线上业务提供服务,整个过程绝大部分业务都是无感知的。
X-DB 拥有真正的跨 Region/ 跨国的数据强一致能力,并已得到实践的检验。双 11 前夕,核心物流系统、核心 IM 系统首次完成了中心 Region 所有数据库不可用的“中心城市容灾演练”,验证业务拥有在整个中心 Region 均不可用情况下,X-DB 和应用仍可以正常提供服务的能力,并保证数据零丢失。
X-DB的核心优势和技术解析
X-DB 是阿里自研的全球级分布式关系型数据库。现在业界各种类型的分布式数据库不断涌现,互联网巨头、传统数据库厂商、数据库创业公司都在不断跟进。那么 X-DB 到底有什么优势能战胜这些竞品,快速获得业务价值呢?
- X-DB生态100%兼容MySQL
新一代分布式关系型数据库是对传统关系型数据库的传承和革新。分布式数据库虽然在高可能、强一致、高性能、低成本、高伸缩等多个方面作出了划时代的变革;但其依旧传承了传统数据库强大的 SQL 接口,系统管理能力。NoSQL 的衰弱和 NewSQL 的兴起,恰恰证明了这一点。一个新的分布式数据库,如果没有传承,自建一个新的生态,将会极大的提高用户的学习和使用成本,整个工具和支持配套也将面临很大的困难。因此,X-DB 作为一个新一代分布式关系型数据库,设计之初就选了业界相对开放和成熟的 MySQL 开源生态作为自己的基础。这样不单可以让 MySQL 生态中的用户零成本的切换到 X-DB 中,快速赋予业务分布式数据库所带来的多种能力;同时可以让 MySQL 生态中的各种周边工具和 DBA 等生态的参与者平滑的切换到分布式时代,赋予其支撑分布式数据库的能力。
事实证明 X-DB 选择的这条路是正确的。在阿里集团及生态下的子公司内部,X-DB 在短短的几个月内、在非常少的人力参与下,迅速的完成了对大量传统 MySQL/AliSQL 集群的换代升级,使得阿里数据库整体进入了分布式时代,整个过程业务几乎零参与。同时 X-DB 对 MySQL 生态下的运维系统 / 工具、知识体系也实现了兼容,整个 MySQL 时代的支撑平台,支撑人员都可以平滑的过度到分布式数据库时代,拥有了支撑下一代数据库的能力,这个是非常难得的。
- 跨 Region/ 全球强同步能力
业界支持分布式强一致的数据库很多,但是其强一致都是有范围的,有些支持 AZ 内强一致,有些支持跨 AZ 强一致,真正能做到跨 Region/ 跨国强一致的却是凤毛麟角。目前业界主流数据库中,只有 Spanner 宣称自己是 Global Distribution,包括 Amazon Aurora 在内的其他主流数据库目前都不支持跨 Region 的强一致。X-DB 是真正做到了跨 Region/ 跨国强一致的分布式数据库,并且在业务上得到了验证。今年音视频服务全站迁移 X-DB,同时 X-DB 支撑了音视频服务国际化等多个国际化项目,实现跨国部署。包括核心交易系统、核心物流系统、核心 IM 系统在内的大量业务集群以跨 Region 强同步模式部署,使得业务拥有了城市级容灾情况下,数据零丢失,服务秒级恢复的能力。核心物流系统、核心 IM 系统在双 11 前夕分别进行了中心 Region 全不可用的容灾演练,X-DB 在 15 秒内自动完成跨 Region 的重新激活,数据零丢失,这在整个行业都是先行者。 - 技术解析:X-Paxos——高性能 Paxos 独立库
Paxos 是一种分布式一致性算法,其最基础也是最重要的功能是保证分布式系统中多个节点的数据(日志)的强一致,它是分布式系统的基石。虽然 Paxos 算法被图灵奖获得者 Leslie Lamport 首次提出到现在已经 19 年了,离第一个工业实现(Chubby)也已经 11 年了,但是近几年,顶级会议 / 业内文章中 Paxos 的优化和讨论还是非常的多,而且到目前为止真正工业级的、高性能的、高可扩展的 Paxos 算法库还是非常的少见。
X-Paoxs 是阿里独立设计 / 研发的,真正工业级的 Paxos 独立库,其在性能上好于业界对手 1、2 个数量级以上,同时其强大的扩展性和完善的生态系统都是竞品所没有的,X-Paxos 为分布式高性能数据库 X-DB 奠定了坚实的基础。
X-Paxos 从基础架构,到网络模型,再到算法本身都有大量的创新:
基于 SEDA 架构的异步并发调度框架
由于 Paxos 的内部状态复杂,实现高效的单实例多线程的 Paxos 变成一个非常大的挑战。大部分竞品例如 Oracle/MySQL 的 Group Replication 等针对单个 Paxos 对象都是单线程实现。
X-Paxos 实现了一整套高效的异步并发调度框架,并基于 SEDA(Staged Event-Driven Architecture)思想,对整个 Paxos 协议进行了并发切分和实现,采用了大量无锁设计;由异步并发调度框架进行调度和执行,充分利用多核资源,实现高性能。
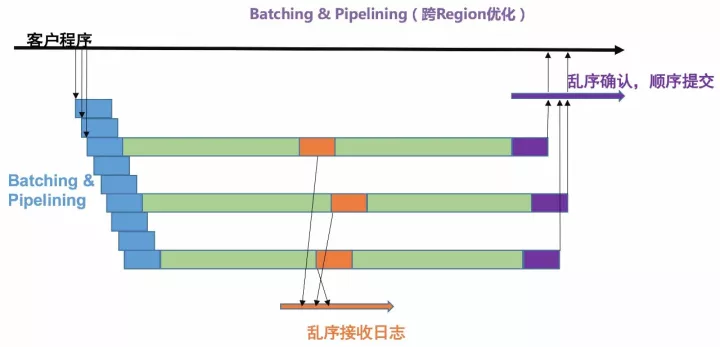
基于 Batching & Pipelining 的网络优化
跨 Region/ 跨国场景下对 X-Paxos 来说最大的挑战就是如何在高延迟网络下保持高吞吐和相对低延迟,X-Paxos 针对高延迟网络做了大量的协议优化尝试和测试,并结合学术界现有的理论成果通过合理的 Batching 和 Pipelining,设计并实现了一整套自适应的针对高延迟高吞吐和低延迟高吞吐网络的通信模式,极大的提升了 X-Paxos 的性能。类似的优化大部分还在理论阶段,在同类竞品中还非常的罕见。
Jepsen/TLA+ 的分布式原理 / 实现验证
《Paxos made live》中有过一个说法,证明一个 Paxos 实现是正确的,比实现这个 Paxos 本身会更难。因此我们在设计和实现 X-Paxos 的时候,投入了大量的精力在 Paxos 的原理证明了实现验证上。我们用 TLA+ 对 X-Paxos 进行建模,验证其理论正确性。我们将 Jepsen 对 X-Paxos/X-DB 进行适配,同时增加了大量的验证 Case 和注入错误,7X24 小时运行,验证其实现正确性。
- 强一致下的高性能
业界习惯性的认为,强一致一定会带来性能的下降,开强 MP 的 Oracle,在 Semi-Sync 的 MySQL,MySQL Group Replication 甚至于跨 Region 部署以后的 Spanner,会面临大幅度的性能下降的问题。今年双 11 X-DB 在核心交易系统、核心物流系统等交易核心链路上 100% 切流,经历了多轮全链路压测和双 11 零点业务 32.5 万笔 / 秒,数据库 SQL 上亿次 / 秒的峰值的性能考验,证明了 X-DB 完全有能力实现强一致和高性能的鱼熊兼得。
X-DB 从 Paxos 协议的实现,到 X-Paxos 和 AliSQL 的日志结合,再到 AliSQL 本身的提交逻辑,锁策略都做了大量的优化。保证 X-DB 无论是在多机房部署还是多 Region 部署下,都能保证性能和单节点模式(非强一致)下无大幅度劣化。特别是在跨 Region 部署时,和其他分布式数据库相比,优势尤为明显。这也是业务能够接受 X-DB 跨 Region 部署的主要原因。
X-DB 是 AliSQL 和 X-Paxos 的紧密结合而产生的。高性能的 X-Paxos 为不单为 X-DB 带来了高可用和强一致的能力,同时为 X-DB 的在强一致下的高可用奠定了坚实的基础。除此以外,我们在 AliSQL 和 X-Paxos 的结合上也做了大量的优化,例如一体化日志设计和异步事务提交。
技术解析:一体化日志设计
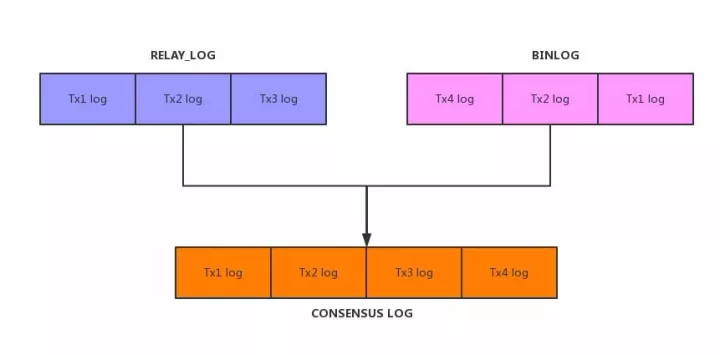
X-DB 的 Consensus 日志采用了单一事务日志的方案(区别于 MySQL 的 binlog 和 relay_log 两份日志),单一事务日志格式 MySQL binlog 的事务日志格式。这份日志被用于集群节点间数据的同步以及下游应用的消费。
一体化日志设计带来的好处是显而易见的,首先是日志量的减少。MySQL 接收到主库的网络消息后会先本地落一份 relay_log 日志,在消费后再产生一份 binlog 日志。虽然 relay_log 会很快被回收,但是日志的写入量是实实在在的两份。反观 X-DB 在统一了日志后,同一个事务在一个实例节点上只需要记录一份日志。其次统一日志能够让日志真正按照产生的先后续做到逻辑和物理上的一致,这对于日志的检索效率来说是大有裨益的。首先是顺序扫描日志的时候可以做到物理 IO 上的顺序性,其次 Paxos 算法的运转对于日志的检索和获取都有较高的要求,如果检索一份日志需要先后扫描两份日志跳转来判断比较,那对于效率来说是非常低下的。
技术解析:异步事务提交
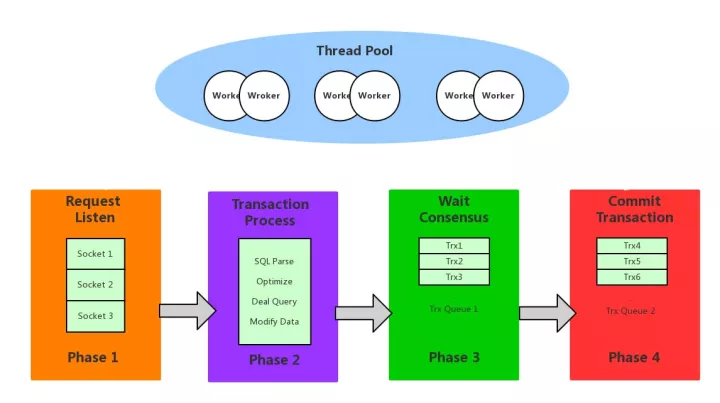
在数据库中,服务端的线程池是非常有效降低线程上下文切换开销,提升系统吞吐的技术。但是在跨城 / 跨国环境下,巨大的网络延迟使得线程池本身会成为一种瓶颈。例如 X-DB 集群的节点分布在网络 RTT 达到几十毫秒级别的两个 Region 中,那么在实际的运行中会发现线程池中绝大部份线程都在等待日志跨 Region 同步回包,而客户端的请求就没有足够的线程去处理了,这其实造成了服务器资源的严重浪费。
重新回到非线程池的状态不是一个明智之举,既要低上下文开销又要有高资源利用率。我们采取的解决方案是将事务处理中可能最为费时的等待事务日志回报做成异步化。 这样就把一个完整的事务流程拆成了:处理请求 ->等待同步 ->事务提交的三个步骤,三个步骤可以分别由线程池的不同线程来完成。每个步骤 X-DB 可以精确控制并发量,例如可以用最少的线程数量来处理事务等待日志同步的工作,用大量的线程来处理事务提交等等。在异步化改造后,只要用户的并发请求量足够多,系统吞吐量上可以有明显的提高。
- 丰富灵活的部署模式
针对电商双 11 这种,不同时期不同需求的业务模型,X-DB 提供了非常丰富并且灵活的部署模式,例如核心交易系统、核心物流系统,在今年双 11 前夕,将部署模式从跨城强同步模式一键切换回同城强同步模式,并动态调整拓扑,在保证机房级强一致的前提下,有效的降低了 RT,提升了吞吐。
集团内外不同的业务对数据库的部署需求各不相同,为了更广泛的支持不同的业务 X-DB 支持的部署模式非常的灵活。业务可以根据自己的容灾和业务需求,在不同的部署范围内(同城多机房 / 国内多 Region/ 跨国等)选择任意数量、任意角色的节点进行部署,节点的部署和角色同样可以在线修改以适应业务的不同时期的不同需求,例如双 11。这样说有点抽象,这里举 2 个实际的案例.
