




ElasticSearch IK中文分词器
5.1 什么是分词器?为什么要分词器?
在上面的学习例子中我们使用的是Es默认的分词器,在中文的分词上并不友好,会将语句每个字进行分词作为索引,所以在使用Term关键字查询的时候多个汉字无法命中文档。这个时候就需要一个合理的分词规则,将一个完整的语句划分为多个比较复合表达逻辑的独立的词条。
分词器包含三个部分:
character filter:分词之前的预处理,过滤掉HTML标签、特殊符号转换(例如,将&符号转换成and、将|符号转换成or)等。
tokenizer:分词
token filter:标准化
5.2 ElasticSeach内置分词器
standard分词器:(默认的)它将词汇单元转换成小写形式,并去掉停用词(a、an、the等没有实际意义的词)和标点符号,支持中文采用的方法为单字切分(例如,‘你好’切分为‘你’和‘好’)。
simple分词器:首先通过非字母字符来分割文本信息,然后将词汇单元同一为小写形式。该分析器会去掉数字类型的字符。
Whitespace分词器:仅仅是去除空格,对字符没有lowcase(大小写转换)化,不支持中文;并且不对生成的词汇单元进行其他的标准化处理。
language分词器:特定语言的分词器,不支持中文。
5.3 IK分词器
5.3.1 IK分词器简介
IK分词器在是一款 基于词典和规则 的中文分词器,提供了两种分词模式:iksmart (智能模式)和ikmax_word (细粒度模式)
输入数据
数据:IK Analyzer是一个结合词典分词和文法分词的中文分词开源工具包。它使用了全新的正向迭代最细粒度切分算法。
智能模式效果:
ik analyzer 是 一个 结合 词典 分词 和 文法 分词 的 中文 分词 开源 工具包 它 使 用了 全新 的 正向 迭代 最 细粒度 切分 算法
细粒度模式:
ik analyzer 是 一个 一 个 结合 词典 分词 和文 文法 分词 的 中文 分词 开源 工具包 工具 包 它 使用 用了 全新 的 正向 迭代 最 细粒度 细粒 粒度 切分 切 分 算法
5.3.2 ElasticSearch集成Ik分词器
Ik分词器下载 https://github.com/medcl/elasticsearch-analysis-ik
安装包中提供了支持ES 7.0X的Ik压缩包,如果使用其他ES版本注意下载对应版本。
(不同版本的集成可能会有所区别)
解压后进行编译打包
mvn clean mvn compile mvn package
拷贝和解压release下的文件: #{project_path}/elasticsearch-analysis-ik/target/releases/elasticsearch-analysis-ik-*.zip 到你的 elasticsearch 插件目录, 如: plugins/ik并解压 重启elasticsearch
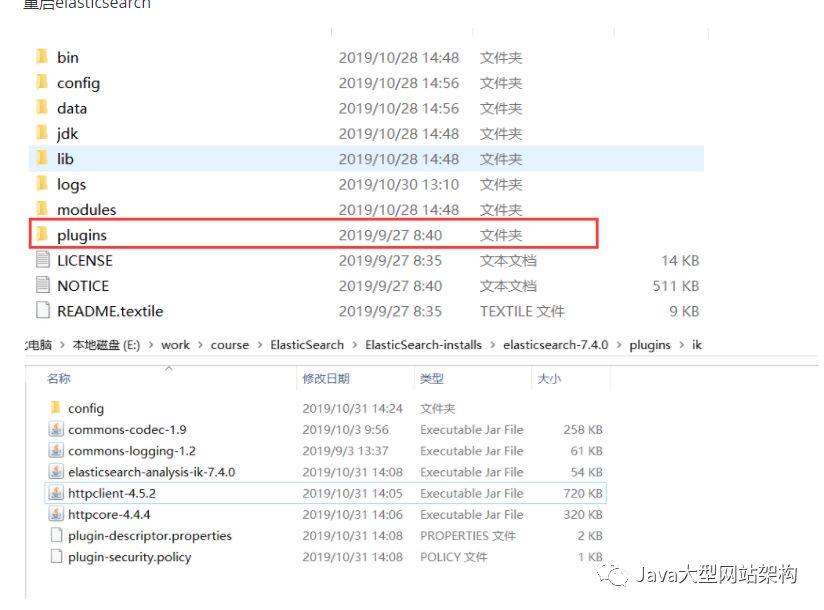
5.3.3 使用ElasticSearch中的 analyze 测试Ik分词效果
请求方式post
请求url http://127.0.0.1:9200/_analyze
请求参数:
{
"analyzer":"ik_smart",
"text":"我们是一群牛逼的程序员"
}
输出效果
{
"tokens": [
{
"token": "我们",
"start_offset": 0,
"end_offset": 2,
"type": "CN_WORD",
"position": 0
},
{
"token": "是",
"start_offset": 2,
"end_offset": 3,
"type": "CN_CHAR",
"position": 1
},
{
"token": "一群",
"start_offset": 3,
"end_offset": 5,
"type": "CN_WORD",
"position": 2
},
{
"token": "牛",
"start_offset": 5,
"end_offset": 6,
"type": "CN_CHAR",
"position": 3
},
{
"token": "逼",
"start_offset": 6,
"end_offset": 7,
"type": "CN_CHAR",
"position": 4
},
{
"token": "的",
"start_offset": 7,
"end_offset": 8,
"type": "CN_CHAR",
"position": 5
},
{
"token": "程序员",
"start_offset": 8,
"end_offset": 11,
"type": "CN_WORD",
"position": 6
}
]
}
5.3.4 Ik分词器停用词和扩展词
在实际使用过程中Ik分词算法的过程中,还有一些场景的分词规则是Ik无法设计的,比如之前的例子中"牛逼"作为一个网络用语没有被解析成一个词条,以及其中的“的”这样的助词往往在建立索引的时候是没有必要的。所以IK支持停用词和扩展词的配置。
需要修改配置文件
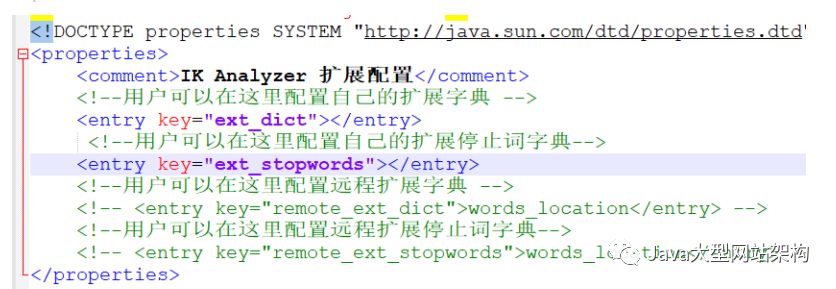
ext_dict填入扩展词文件
ext_stopwords填入停用词文件
文件以dic后缀结尾,需要和IKAnalyzer.cfg在同级目录。
dic文件每个词需要占一行。
