ElasticSearch基本操作
基本操作在学习过程中可以使用单测工具进行,在安装包中提供了postman、jmeter安装包。
大家可以根据自己的喜好选择。
因为在学习使用http请求操作Es,必须对RESTful 风格有所了解,所以在学习基本操作前,对RESTful 知识进行补充:
RESTful 在两方面做了相应规范:
1、服务数据交互格式使用json、xml。
2、采用HTTP协议规定的GET、POST、PUT、DELETE动作处理资源的增删改查操作
| Method | CRUD |
|---|---|
| POST | create(update、delete) |
| GET | query |
| PUT | update (create) |
| Delete | delete |
4.1 ElasticSearch语法
mapping字段详解
| 名称 | 作用描述 |
|---|---|
| type | 字段数据类型,可选值参考" type可选类型" |
| analyzer | 指定分词器,一般使用最大分词:ikmaxword |
| index | 该字段是否会被索引和可查询 默认true |
| store | 默认情况false,其实并不是真没有存储,_source字段里会保存一份原始文档 |
| normalizer | 字段标准化规则;如把所有字符转为小写 |
| boost | 字段权重;用于查询时评分,关键字段的权重就会高一些,默认都是1;另外查询时可临时指定权重 |
| coerce | 清理脏数据:1,字符串会被强制转换为整数 2,浮点数被强制转换为整数 |
| copy_to | 自定_all字段;指定某几个字段拼接成自定义 |
| doc_values | true 加快排序、聚合操作,但需要额外存储空间;默认true,对于确定不需要排序和聚合的字段可false |
| dynamic | 默认true, #新字段动态添加 true:无限制 false:数据可写入但该字段不保留 'strict':无法写入抛异常 |
| enabled | 默认true, 是否会被索引,但都会存储;可以针对一整个_doc |
| fielddata | 默认false,针对text字段加快排序和聚合.此项官网建议不开启,非常消耗内存 |
| eagerglobalordinals | 默认true,是否开启全局预加载,加快查询;此参数只支持text和keyword,keyword默认可用,而text需要设置fielddata属性 |
| format | 格式化 此参数代表可接受的时间格式 "yyyy-MM-dd HH:mm:ss\ |
| ignore_above | 100 指定字段索引和存储的长度最大值,超过最大值的会被忽略 |
| ignore_malformed | 默认 false,插入文档时是否忽略类型 默认是false 类型不一致无法插入 |
| index_options | docs . docs(索引文档号) \ freqs(文档号 + 词频)\ positions(文档号 + 词频 + 位置,通常用来距离查询) offsets(文档号 + 词频 + 位置 + 偏移量,通常被使用在高亮字段) |
| fields | 可以对一个字段提供多种索引模式,使用text类型做全文检索,也可使用keyword类型做聚合和排序 |
| norms | true 用于标准化文档,以便查询时计算文档的相关性。建议不开启 |
| null_value | 可以让值为null的字段显式的可索引、可搜索 |
| positionincrementgap | 0,词组查询时可以跨词查询 既可变为分词查询 默认100 |
| properties | 嵌套属性,例如该字段是音乐,音乐还有歌词,类型,歌手等属性 |
| search_analyzer | 查询分词器;一般情况和analyzer对应 |
| similarity | 用于指定文档评分模型,参数有三个 BM25 : ES和Lucene默认的评分模型 classic: TF/IDF评分 boolean:布尔模型评分 |
| term_vector | 默认 "no" ,不存储向量信息 yes : term存储 (term存储) withpositions (term + 位置) withoffsets (term + 位置) withpositionsoffsets(term + 位置 + 偏移量) 对快速高亮fast vector highlighter能提升性能,但开启又会加大索引体积,不适合大数据量用 |
type 可选类型
| 类型 | 具体值 |
|---|---|
| 字符串型 | text (会分词建立索引),keyword(直接建立索引) |
| 整数类型 | integer,long,short,byte |
| 浮点类型 | double,float,halffloat,scaledfloat |
| 逻辑类型 | boolean |
| 日期类型 | date |
| 范围类型 | range |
| 二进制类型 | binary |
| 数组类型 | array |
| 对象类型 | nested |
| 地理坐标类型 | geo_point |
| 地理地图 | geo_shape |
| IP类型 | ip |
| 范围类型 | completion |
| 令牌计数类型 | token_count |
| 附件类型 | attachment |
| 抽取类型 | percolator |
4.2 通过HTTP请求创建
4.2.1 仅创建索引
请求方式选择 PUT
请求链接在URL一级目录输入需要创建的索引
比如我们一个shop的索引
http://127.0.0.1:9200/shop
4.2.2 创建索引的同时创建mapping 以及分片复制参数
传入body参数执行
{
"settings" : {
"number_of_shards":5,
"number_of_replicas" : 1,
"refresh_interval":"30s"
},
"mappings":{
"properties":{
"shopid":{
"type":"text",
"store":false,
"index":true
},
"shopname":{
"type":"text",
"store":false,
"index":true
},
"shopdesc":{
"type":"text",
"store":false,
"index":true
}
}
}
}
postman截图
4.2.3 删除索引库
请求方式选择Delete
请求链接如:http://127.0.0.1:9200/shop 删除shop索引
4.2.3 向索引库中添加文档
请求方式选 POST
单条插入:
请求url : http://127.0.0.1:9200/shop/doc/1 (索引/"doc"/文档id)
或者http://127.0.0.1:9200/shop/_doc
文档id为Es中的文档主键id,不指定的情况下Es会给我们生成一个唯一的随机字符串,如 BU7pG24Bm2YrPBUaN0wD
{
"shopid":"1234",
"shopname":"你的小店",
"shopdesc":"你的小店,只为喂饱你的胃"
}
postman截图
批量添加:
请求url:http://127.0.0.1:9200/shop/_bulk
{ "index":{} }
{ "shopid":"1234656","shopname":"fox" ,"shopdesc":"亲承5为自己生下5个孩子 此前12个" }
{ "index":{} }
{ "shopid":"1234657","shopname":"乒联" ,"shopdesc":"国际乒联奥地利公开赛正赛展开" }
{ "index":{"_id":"iikdjsd"} }
{ "shopid":"1234658","shopname":"纷纷两连败" ,"shopdesc":"两连败+二当家伤停再遭困境 考验欧文.." }
{ "index":{"_id":"iik3325"} }
{ "shopid":"1234659","shopname":"纷纷返回" ,"shopdesc":"33+9+4+5误!这是最乔治!黑贝最.." }
index可以指定参数,比如指定id,不指定则默认生成id
postman截图:
4.2.3 删除文档
请求方式选择Delete
请求url : http://127.0.0.1:9200/shop/doc/1 (索引/"doc"/文档id)
4.2.4 查询文档
请求方式选择Get
请求url : http://127.0.0.1:9200/shop/doc/1 (索引/"doc"/文档id)
4.2.5 修改文档
请求方式选择POST
请求url : http://127.0.0.1:9200/shop/doc/1 (索引/"doc"/文档id)
{
"shopname":"fox"
}
4.2.6 根据关键词查询文档
请求方式选择Get
请求url http://127.0.0.1:9200/shop/doc/search (索引/"doc"/"search")
请求参数query、term为固定命令,shopdesc为指定在哪个字段查询什么关键字(支持什么样的关键字查询取决于mapping里指定的分析器,比如单个字为索引、分词索引,之前测试的语句都是标准分词,以单个字为索引,所以查询的时候只支持一个汉字,如果输入多个则查询不到数据)
{
"query":{
"term":{
"shopdesc":"店"
}
}
}
postman截图
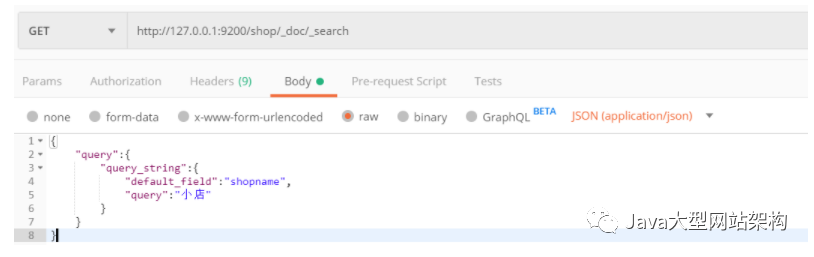
4.2.7 queryString查询
queryString是讲输入参数进行分词然后去索引库中检索。
请求方式选择Get
请求url http://127.0.0.1:9200/shop/doc/search
请求参数
{
"query":{
"query_string":{
"default_field":"shopname",
"query":"小店"
}
}
}
postman截图