




一直没有深入研究es,应用组es应用场景很多,便决定自己搭建一套es集群,这里记录下搭建过程,以便后期排错和学习;
1.这里采用三台虚拟机,IP列表
192.168.0.111 hadoop1.hdp.ljs hadoop1192.168.0.112 hadoop2.hdp.ljs hadoop2192.168.0.113 hadoop3.hdp.ljs hadoop3
2.这里我下载版本是7.10.0,可直接从官网下载,下载地址:
curl -O https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-7.10.0-linux-x86_64.tar.gz
3.由于es不能直接用root用户启动,这里新建es用户,并赋予sudo权限,命令如下(三台机器都需要执行)
#添加租户/用户,修改密码:groupadd esuseradd -g es -d home/es esecho "123456a?" | passwd --stdin es#赋予sudo权限cp /etc/sudoers etc/sudoers_bakecho "es ALL=(ALL) NOPASSWD:ALL" >> etc/sudoers
4.es启动最小需要的内存数是262144,如不修改会报错,如下:

修改/etcsysctl.conf文件(三台都需要执行)
vim /etc/sysctl.conf//在最后一行上加上vm.max_map_count=262144
修改 /etc/security/limits.conf,在最后几行添加如下内容(三台都需要执行)
* soft nofile 65536* hard nofile 65536* soft nproc 65536* hard nproc 65536* soft memlock unlimited* hard memlock unlimited
5.解压tar包,将elasticsearch-7.10.0-linux-x86_64.tar.gz上传到hadoop1节点,解压到/opt下,命令如下:
tar -zxvf elasticsearch-7.10.0-linux-x86_64.tar.gz
解压后目录结构如下:

修改elasticsearch.yml文件,内容如下:
# 设置集群名称,集群内所有节点的名称必须一致。cluster.name: es-cluster# 设置节点名称,集群内节点名称必须唯一。node.name: node1# 表示该节点会不会作为主节点,true表示会;false表示不会node.master: true# 当前节点是否用于存储数据,是:true、否:falsenode.data: true# 索引数据存放的位置path.data: /opt/elasticsearch-7.10.0/data# 日志文件存放的位置path.logs: /opt/elasticsearch-7.10.0/logs# 需求锁住物理内存,是:true、否:false#bootstrap.memory_lock: true# 监听地址,用于访问该esnetwork.host: 192.168.0.111# es对外提供的http端口,默认 9200http.port: 9200# TCP的默认监听端口,默认 9300transport.tcp.port: 9300# 设置这个参数来保证集群中的节点可以知道其它N个有master资格的节点。默认为1,对于大的集群来说,可以设置大一点的值(2-4)discovery.zen.minimum_master_nodes: 2# es7.x 之后新增的配置,写入候选主节点的设备地址,在开启服务后可以被选为主节点discovery.seed_hosts: ["192.168.0.111:9300", "192.168.0.112:9300", "192.168.0.113:9300"]discovery.zen.fd.ping_timeout: 1mdiscovery.zen.fd.ping_retries: 5# es7.x 之后新增的配置,初始化一个新的集群时需要此配置来选举mastercluster.initial_master_nodes: ["node1", "node2", "node3"]# 是否支持跨域,是:true,在使用head插件时需要此配置http.cors.enabled: true# “*” 表示支持所有域名http.cors.allow-origin: "*"action.destructive_requires_name: trueaction.auto_create_index: .security,.monitoring*,.watches,.triggered_watches,.watcher-history*xpack.security.enabled: falsexpack.monitoring.enabled: truexpack.graph.enabled: falsexpack.watcher.enabled: falsexpack.ml.enabled: false
6.将/opt/elasticsearch-7.10.0目录,从hadoop1拷贝到hadoop2、hadoop3两个节点上,并修改elasticsearch.yml文件中的两个配置项node.name和network.host,分别修改为nod2、node3和192.168.0.112、192.168.0.113,这里不再细说;
hadoop2节点elasticsearch.yml文件内容:
# 设置集群名称,集群内所有节点的名称必须一致。cluster.name: es-cluster# 设置节点名称,集群内节点名称必须唯一。node.name: node2# 表示该节点会不会作为主节点,true表示会;false表示不会node.master: true# 当前节点是否用于存储数据,是:true、否:falsenode.data: true# 索引数据存放的位置path.data: /opt/elasticsearch-7.10.0/data# 日志文件存放的位置path.logs: /opt/elasticsearch-7.10.0/logs# 需求锁住物理内存,是:true、否:false#bootstrap.memory_lock: true# 监听地址,用于访问该esnetwork.host: 192.168.0.112# es对外提供的http端口,默认 9200http.port: 9200# TCP的默认监听端口,默认 9300transport.tcp.port: 9300# 设置这个参数来保证集群中的节点可以知道其它N个有master资格的节点。默认为1,对于大的集群来说,可以设置大一点的值(2-4)discovery.zen.minimum_master_nodes: 2# es7.x 之后新增的配置,写入候选主节点的设备地址,在开启服务后可以被选为主节点discovery.seed_hosts: ["192.168.0.111:9300", "192.168.0.112:9300", "192.168.0.113:9300"]discovery.zen.fd.ping_timeout: 1mdiscovery.zen.fd.ping_retries: 5# es7.x 之后新增的配置,初始化一个新的集群时需要此配置来选举mastercluster.initial_master_nodes: ["node1", "node2", "node3"]# 是否支持跨域,是:true,在使用head插件时需要此配置http.cors.enabled: true# “*” 表示支持所有域名http.cors.allow-origin: "*"action.destructive_requires_name: trueaction.auto_create_index: .security,.monitoring*,.watches,.triggered_watches,.watcher-history*xpack.security.enabled: falsexpack.monitoring.enabled: truexpack.graph.enabled: falsexpack.watcher.enabled: falsexpack.ml.enabled: false
hadoop3节点elasticsearch.yml文件内容:
# 设置集群名称,集群内所有节点的名称必须一致。cluster.name: es-cluster# 设置节点名称,集群内节点名称必须唯一。node.name: node3# 表示该节点会不会作为主节点,true表示会;false表示不会node.master: true# 当前节点是否用于存储数据,是:true、否:falsenode.data: true# 索引数据存放的位置path.data: /opt/elasticsearch-7.10.0/data# 日志文件存放的位置path.logs: /opt/elasticsearch-7.10.0/logs# 需求锁住物理内存,是:true、否:false#bootstrap.memory_lock: true# 监听地址,用于访问该esnetwork.host: 192.168.0.113# es对外提供的http端口,默认 9200http.port: 9200# TCP的默认监听端口,默认 9300transport.tcp.port: 9300# 设置这个参数来保证集群中的节点可以知道其它N个有master资格的节点。默认为1,对于大的集群来说,可以设置大一点的值(2-4)discovery.zen.minimum_master_nodes: 2# es7.x 之后新增的配置,写入候选主节点的设备地址,在开启服务后可以被选为主节点discovery.seed_hosts: ["192.168.0.111:9300", "192.168.0.112:9300", "192.168.0.113:9300"]discovery.zen.fd.ping_timeout: 1mdiscovery.zen.fd.ping_retries: 5# es7.x 之后新增的配置,初始化一个新的集群时需要此配置来选举mastercluster.initial_master_nodes: ["node1", "node2", "node3"]# 是否支持跨域,是:true,在使用head插件时需要此配置http.cors.enabled: true# “*” 表示支持所有域名http.cors.allow-origin: "*"action.destructive_requires_name: trueaction.auto_create_index: .security,.monitoring*,.watches,.triggered_watches,.watcher-history*xpack.security.enabled: falsexpack.monitoring.enabled: truexpack.graph.enabled: falsexpack.watcher.enabled: falsexpack.ml.enabled: false
7.修改/opt/elasticsearch-7.10.0目录所属用户和组为es,命令如下(三台都需要执行):
chown -R es:es /opt/elasticsearch-7.10.0/

8.启动es,这里为了方便停止,可制定启动的进程号,命令如下三台都需要执行):
./elasticsearch-7.6.1/bin/elasticsearch -d -p pid
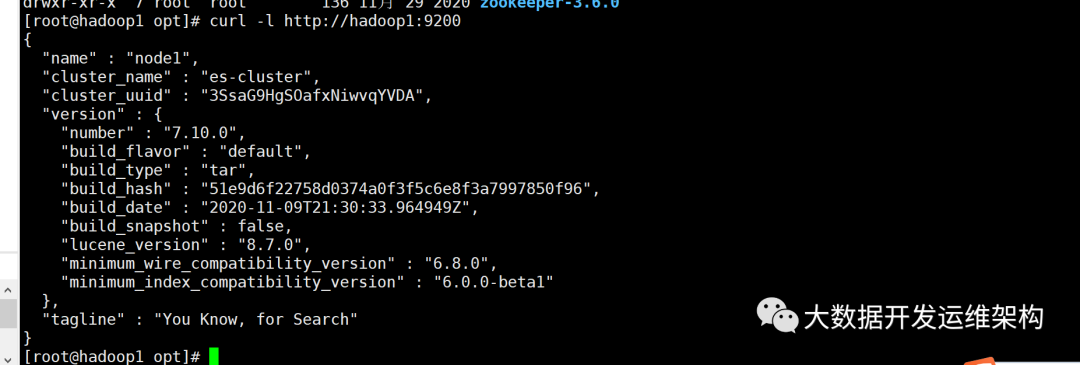
9.验证es集群是否启动成功,可分别在三台机器执行查看命令:
#hadoop1执行curl -l http://hadoop1:9200#hadoop2执行curl -l http://hadoop2:9200#hadoop3执行curl -l http://hadoop3:9200
10.停止es命令:
#pid为之前启动时,控制台打印的进程号pkill -F pid
如果觉得我的文章能帮到您,请关注微信公众号“大数据开发运维架构”,并转发朋友圈,谢谢支持!!!

