




散仙在上篇文章中,介绍了关于ElasticSearch基本的增删改查的基本粒子,本篇呢,我们来学下稍微高级一点的知识:
(1)如何在ElasticSearch中批量提交索引 ?
(2)如何使用高级查询(包括,检索,排序,过滤,分页) ?
(3)如何组合多个查询 ?
(4)如何使用翻页深度查询 ?
(5)如何使用基本的聚合查询 ?
(一)首先,我们思考下,为什么要使用批量添加,这个毫无疑问,因为效率问题,举个在生活中的例子,假如我们有50个人,要去美国旅游,不使用批处理的方式是,给每一个人派一架飞机送到美国,那么这就需要50次飞机的来回往来,假如使用了批处理,现在的情况就是一个飞机坐50个人,只需一次即可把所有人都送到美国,效率可想而知,生活也有很多实际的例子,大家可以自己想想。
在原生的lucene中,以及solr中,这个批处理方式,实质是控制commit的时机,比如多少个提交一次,或者超过ranbuffersize的大小后自动提交,es封装了lucene的api提供bulk的方式来批量添加,原理也是,聚集一定的数量doc,然后发送一次添加请求。
(二)只要我们使用了全文检索,我们的业务就会有各种各样的api操作,包括,任意维度的字段查询,过滤掉某些无效的信息,然后根据某个字段排序,再取topN的结果集返回,使用数据库的小伙伴们,相信大家都不陌生,在es中,这些操作都是支持的,而且还非常高效,它能满足我们大部分的需求
(三)在es中,我们可以查询多个index,以及多个type,这一点是非常灵活地,我们,我们可以一次组装两个毫无关系的查询,发送到es服务端进行检索,然后获取结果。
(四)es中,通过了scorll的方式,支持深度分页查询,在数据库里,我们使用的是一个cursor游标来记录读取的偏移量,同样的在es中也支持,这样的查询方式,它通过一个scrollid记录了上一次查询的状态,能轻而易举的实现深度翻页,本质上是对了Lucene的SearchAfter的封装。
(五)es中,也提供了对聚合函数的支持,比如一些max,min,avg,count,sum等支持,除此之外还支持group,facet等操作,这些功能,在电商中应用非常广泛,基于lucene的solr和es都有很好的支持。
下面截图看下散仙的测试数据值: 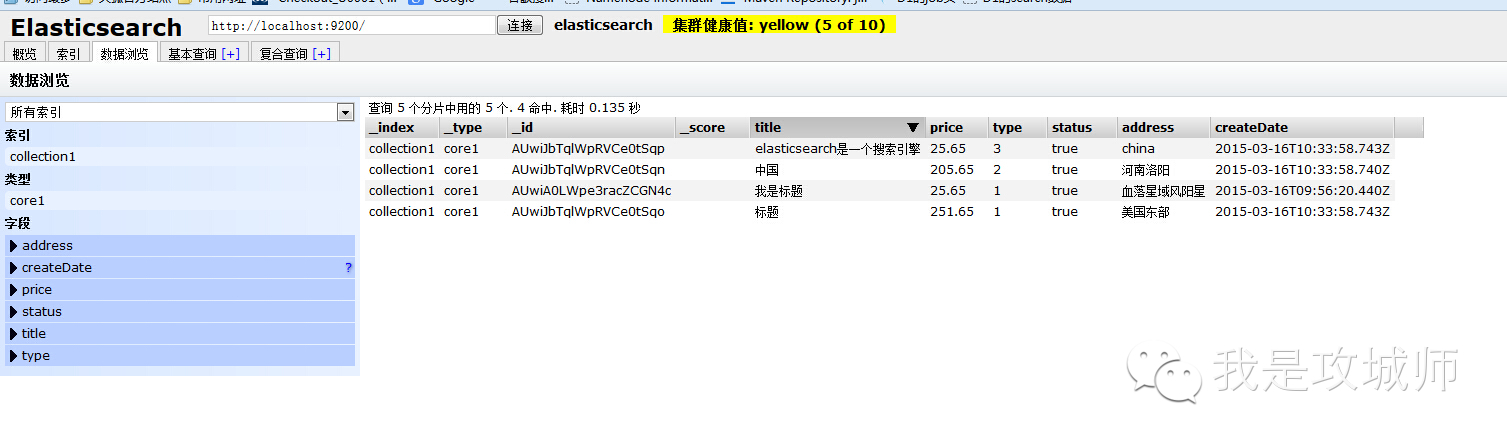
源码demo如下:
Java代码 
package com.dongliang.es;
import java.util.Date;
import java.util.Map;
import java.util.Map.Entry;
import org.apache.lucene.index.Terms;
import org.elasticsearch.action.bulk.BulkRequestBuilder;
import org.elasticsearch.action.bulk.BulkResponse;
import org.elasticsearch.action.search.MultiSearchResponse;
import org.elasticsearch.action.search.SearchRequestBuilder;
import org.elasticsearch.action.search.SearchResponse;
import org.elasticsearch.action.search.SearchType;
import org.elasticsearch.client.Client;
import org.elasticsearch.client.transport.TransportClient;
import org.elasticsearch.common.transport.InetSocketTransportAddress;
import org.elasticsearch.common.unit.TimeValue;
import org.elasticsearch.common.xcontent.XContentBuilder;
import org.elasticsearch.common.xcontent.XContentFactory;
import org.elasticsearch.index.query.FilterBuilders;
import org.elasticsearch.index.query.QueryBuilders;
import org.elasticsearch.index.query.QueryStringQueryBuilder;
import org.elasticsearch.search.SearchHit;
import org.elasticsearch.search.aggregations.AggregationBuilders;
import org.elasticsearch.search.aggregations.bucket.filters.InternalFilters.Bucket;
import org.elasticsearch.search.sort.SortOrder;
/**
* @author 三劫散仙
* 搜索技术交流群:324714439
* 一个关于elasticsearch批量提交
* 和search query的的例子
* **/
public class ElasticSearchDao {
//es的客户端实例
Client client=null;
{
//连接单台机器,注意ip和端口号,不能写错
client=new TransportClient().
addTransportAddress(new InetSocketTransportAddress("192.168.46.16", 9300));
}
public static void main(String[] args)throws Exception {
ElasticSearchDao es=new ElasticSearchDao();
//es.indexdata();//索引数据
//es.queryComplex();
es.querySimple();
//es.scorllQuery();
//es.mutilCombineQuery();
//es.aggregationQuery();
}
/**组合分组查询*/
public void aggregationQuery()throws Exception{
SearchResponse sr = client.prepareSearch()
.setQuery(QueryBuilders.matchAllQuery())
.addAggregation(
AggregationBuilders.terms("1").field("type")
)
// .addAggregation(
// AggregationBuilders.dateHistogram("agg2")
// .field("birth")
// .interval(DateHistogram.Interval.YEAR)
// )
.execute().actionGet();
// Get your facet results
org.elasticsearch.search.aggregations.bucket.terms.Terms a = sr.getAggregations().get("1");
for(org.elasticsearch.search.aggregations.bucket.terms.Terms.Bucket bk:a.getBuckets()){
System.out.println("类型: "+bk.getKey()+" 分组统计数量 "+bk.getDocCount()+" ");
}
System.out.println("聚合数量:"+a.getBuckets().size());
//DateHistogram agg2 = sr.getAggregations().get("agg2");
//结果:
// 类型: 1 分组数量 2
// 类型: 2 分组数量 1
// 类型: 3 分组数量 1
// 聚合数量:3
}
/**多个不一样的请求组装*/
public void mutilCombineQuery(){
//查询请求1
SearchRequestBuilder srb1 =client.prepareSearch().setQuery(QueryBuilders.queryString("eng").field("address")).setSize(1);
//查询请求2//matchQuery
SearchRequestBuilder srb2 = client.prepareSearch().setQuery(QueryBuilders.matchQuery("title", "标题")).setSize(1);
//组装查询
MultiSearchResponse sr = client.prepareMultiSearch().add(srb1).add(srb2).execute().actionGet();
// You will get all individual responses from MultiSearchResponse#getResponses()
long nbHits = 0;
for (MultiSearchResponse.Item item : sr.getResponses()) {
SearchResponse response = item.getResponse();
for(SearchHit hits:response.getHits().getHits()){
String sourceAsString = hits.sourceAsString();//以字符串方式打印
System.out.println(sourceAsString);
}
nbHits += response.getHits().getTotalHits();
}
System.out.println("命中数据量:"+nbHits);
//输出:
// {"title":"我是标题","price":25.65,"type":1,"status":true,"address":"血落星域风阳星","createDate":"2015-03-16T09:56:20.440Z"}
// 命中数据量:2
client.close();
}
/**
* 翻页查询
* */
public void scorllQuery()throws Exception{
QueryStringQueryBuilder queryString = QueryBuilders.queryString("标题").field("title");
//TermQueryBuilder qb=QueryBuilders.termQuery("title", "我是标题");
SearchResponse scrollResp = client.prepareSearch("collection1")
.setSearchType(SearchType.SCAN)
.setScroll(new TimeValue(60000))
.setQuery(queryString)
.setSize(100).execute().actionGet(); //100 hits per shard will be returned for each scroll
while (true) {
for (SearchHit hit : scrollResp.getHits().getHits()) {
//Handle the hit...
String sourceAsString = hit.sourceAsString();//以字符串方式打印
System.out.println(sourceAsString);
}
//通过scrollid来实现深度翻页
scrollResp = client.prepareSearchScroll(scrollResp.getScrollId()).setScroll(new TimeValue(600000)).execute().actionGet();
//Break condition: No hits are returned
if (scrollResp.getHits().getHits().length == 0) {
break;
}
}
//输出
// {"title":"我是标题","price":25.65,"type":1,"status":true,"address":"血落星域风阳星","createDate":"2015-03-16T09:56:20.440Z"}
// {"title":"标题","price":251.65,"type":1,"status":true,"address":"美国东部","createDate":"2015-03-16T10:33:58.743Z"}
client.close();
}
/**简单查询*/
public void querySimple()throws Exception{
SearchResponse sp = client.prepareSearch("collection1").execute().actionGet();
for(SearchHit hits:sp.getHits().getHits()){
String sourceAsString = hits.sourceAsString();//以字符串方式打印
System.out.println(sourceAsString);
}
//结果
// {"title":"我是标题","price":25.65,"type":1,"status":true,"address":"血落星域风阳星","createDate":"2015-03-16T09:56:20.440Z"}
// {"title":"中国","price":205.65,"type":2,"status":true,"address":"河南洛阳","createDate":"2015-03-16T10:33:58.740Z"}
// {"title":"标题","price":251.65,"type":1,"status":true,"address":"美国东部","createDate":"2015-03-16T10:33:58.743Z"}
// {"title":"elasticsearch是一个搜索引擎","price":25.65,"type":3,"status":true,"address":"china","createDate":"2015-03-16T10:33:58.743Z"}
}
/**组合查询**/
public void queryComplex()throws Exception{
SearchResponse sp=client.prepareSearch("collection1")//检索的目录
.setTypes("core1")//检索的索引
.setSearchType(SearchType.DFS_QUERY_THEN_FETCH)//Query type
.setQuery(QueryBuilders.termQuery("type", "1"))//查询--Query
.setPostFilter(FilterBuilders.rangeFilter("price").from(10).to(550.23))//过滤 --Filter
.addSort("price",SortOrder.DESC) //排序 -- sort
.setFrom(0).setSize(20).setExplain(true)//topN方式
.execute().actionGet();//执行
System.out.println("本次查询命中条数: "+sp.getHits().getTotalHits());
for(SearchHit hits:sp.getHits().getHits()){
//String sourceAsString = hits.sourceAsString();//以字符串方式打印
//System.out.println(sourceAsString);
Map<String, Object> sourceAsMap = hits.sourceAsMap();
for(Entry<String, Object> k:sourceAsMap.entrySet()){
System.out.println("name: "+k.getKey()+" value: "+k.getValue());
}
System.out.println("=============================================");
}
//结果
// 本次查询命中条数: 2
// name: title value: 标题
// name: price value: 251.65
// name: address value: 美国东部
// name: status value: true
// name: createDate value: 2015-03-16T10:33:58.743Z
// name: type value: 1
// =============================================
// name: title value: 我是标题
// name: price value: 25.65
// name: address value: 血落星域风阳星
// name: status value: true
// name: createDate value: 2015-03-16T09:56:20.440Z
// name: type value: 1
// =============================================
client.close();
}
/**索引数据*/
public void indexdata()throws Exception{
BulkRequestBuilder bulk=client.prepareBulk();
XContentBuilder doc=XContentFactory.jsonBuilder()
.startObject()
.field("title","中国")
.field("price",205.65)
.field("type",2)
.field("status",true)
.field("address", "河南洛阳")
.field("createDate", new Date()).endObject();
//collection为索引库名,类似一个数据库,索引名为core,类似一个表
// client.prepareIndex("collection1", "core1").setSource(doc).execute().actionGet();
//批处理添加
bulk.add(client.prepareIndex("collection1", "core1").setSource(doc));
doc=XContentFactory.jsonBuilder()
.startObject()
.field("title","标题")
.field("price",251.65)
.field("type",1)
.field("status",true)
.field("address", "美国东部")
.field("createDate", new Date()).endObject();
//collection为索引库名,类似一个数据库,索引名为core,类似一个表
// client.prepareIndex("collection1", "core1").setSource(doc).execute().actionGet();
//批处理添加
bulk.add(client.prepareIndex("collection1", "core1").setSource(doc));
doc=XContentFactory.jsonBuilder()
.startObject()
.field("title","elasticsearch是一个搜索引擎")
.field("price",25.65)
.field("type",3)
.field("status",true)
.field("address", "china")
.field("createDate", new Date()).endObject();
//collection为索引库名,类似一个数据库,索引名为core,类似一个表
//client.prepareIndex("collection1", "core1").setSource(doc).execute().actionGet();
//批处理添加
bulk.add(client.prepareIndex("collection1", "core1").setSource(doc));
//发一次请求,提交所有数据
BulkResponse bulkResponse = bulk.execute().actionGet();
if (!bulkResponse.hasFailures()) {
System.out.println("创建索引success!");
} else {
System.out.println("创建索引异常:"+bulkResponse.buildFailureMessage());
}
client.close();//释放资源
// System.out.println("索引成功!");
}
}
想了解更多有关电商互联网公司的搜索技术和大数据技术的使用,请欢迎扫码关注微信公众号:我是攻城师(woshigcs)
本公众号的内容是有关搜索和大数据技术和互联网等方面内容的分享,也是一个温馨的技术互动交流的小家园,有什么问题随时都可以留言,欢迎大家来访! 
