




我是啤酒就辣条。
但行好事,莫问前程。
官方为我们提供了多种语言操作Elasticsearch的API,可以很方便的在项目中操作。学习利用原生请求操作Elasticsearch,方便维护数据库,还能加快学习使用不同语言的API。
本博客使用kibana发起请求,使用kibana可以查看快捷键。
索引操作
创建索引
创建索引使用PUT
请求,后面跟上索引名称就好了,由于7.x默认type为_doc
,所以后面不必跟上type了。在PUT简单请求同时,可以加上JSON请求体,进行复杂创建。
PUT user{"settings": {"index": {"number_of_shards": 3,"number_of_replicas": 2}},"mappings": {"properties": {"name": { "type": "text" },"age": {"type": "short"},"city":{"type": "keyword"}}}}
创建索引user
,可以通过参数setting
设置分片和副本数,通过number_of_shards
设置一共有3个分片,通过number_of_replicas
给每个分片设置2个副本,默认不指定的话,这两个参数都是1。通过mappings
规定文档各个Filed插入类型。此外,还可以设置aliases
字段,给索引创建别名,这样不仅可以通过别名访问该索引,还可以定义查询条件、指定查询分片等等,详情请参考。
删除索引
删除索引,使用DELETE请求。
DELETE user
查看索引
查看索引,使用GET
请求,可以查看索引设置的参数。
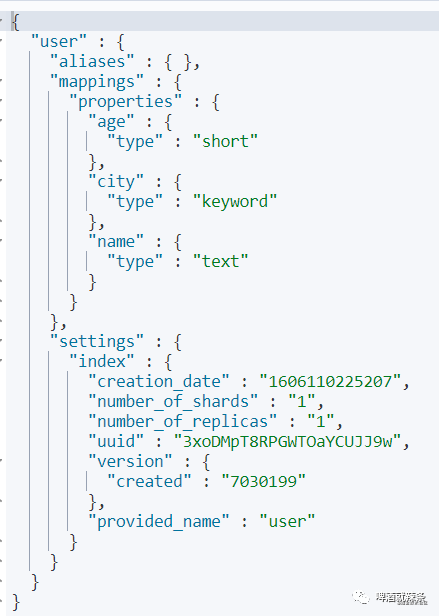
删除之后,我又重新添加索引,没有设置settings,所以分片和副本都是1。
你也可以通过在索引后面加参数来查看某一具体参数,如:
GET user/_settingsGET user/_mappingsGET user/_aliases
修改索引部分设置
可以通过PUT
请求修改部分索引的settings,例如,分片副本数量可以修改,但是分片数量不可以通过这种方式修改。
PUT user/_settings{"number_of_replicas": 3}
可以通过以上请求,修改分片副本。
文档操作
创建好索引,来看下文档的增删改查,这是日常业务用的最多的地方。
插入文档
新增文档使用PUT
、POST
请求。
PUT <target>/_doc/<_id>POST <target>/_doc/PUT <target>/_create/<_id>POST /<target>/_create/<_id>
target
为索引名称,_doc
为默认type。通过前两种请求可看出,id可以自行指定,也可以由ES自动生成。_create
可以保证只有当文档不存在的时候进行插入,而_doc
还可以用于文档更新。
POST /user/_doc/1{"name":"pjjlt","age":26,"city":"sjz"}
更新文档
更新文档可以使用PUT
或者POST
请求关键字,全量更新。
POST /user/_doc/1{"name":"pjjlt","age":3,"city":"sjz"}
还可以通过_update
命令局部更新,所谓局部更新,是讲请求体内不需要加入全部字段,只加入需要修改的字段就好,其他字段不变。全量更新会替换整个文档。
POST /user/_update/1{"doc":{"age": 26}}
此外还可以通过脚本修改,例如将所有存在age
字段的文档,其值改成5岁。
POST /user/_update_by_query{"script": {"source": "ctx._source['age']=5"},"query": {"bool": {"must": [{"exists": {"field": "age"}}]}}}
此外update
和_update_by_query
字段还可以修改Filed
,例如将name修改成name1,这块内容使用较少,如感兴趣,请参考官方文档。
删除文档
删除文档可以使用DELEETE
请求,删除指定id的文档,也可以使用_delete_by_query
,删除指定条件下的文档。
DELETE /user/_doc/1
POST /user/_delete_by_query{"query": {"match": {"name": "pjjlt"}}}
查找文档
查找文档是ES操作最精彩的部分,这里只介绍简单的查询,复杂查询、聚合查询后面会介绍。
根据id查询某文档。
GET /user/_doc/1
查找某索引下的全部文档
GET /user/_search?pretty
pretty
参数在浏览器中才会发挥作用,格式化返回json的。以上这条命令默认返回10条数据,想返回更多数据可以添加size
字段。
GET /user/_search?pretty&size=20
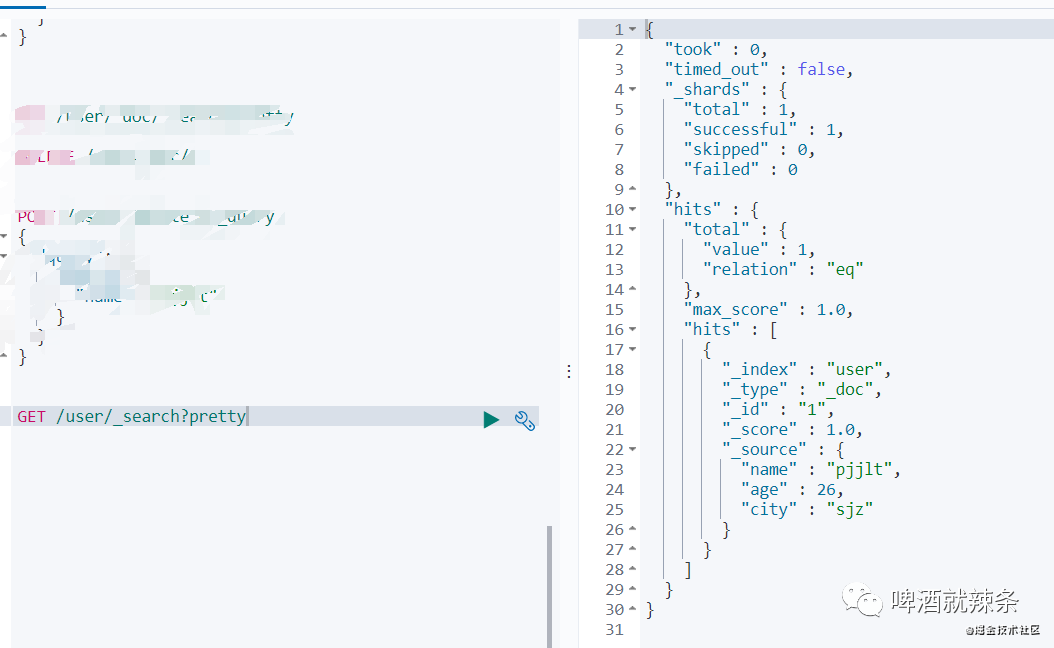
可以看出,数据部分在hits
里面,Spring提供的elasticsearch客户端会有对应的实体类,在项目中很方便的使用。下面看下这几部分的含义。
| 元素 | 含义 |
|---|---|
| took | 运行查询需要多长时间 |
| time_out | 请求是否超时 |
| _shards | 搜索了多少分片,多少成功 多少跳过,多少失败 |
| hits.total | 总共有多少数据 |
| hits._max_score | 查询到的文档中,关联度最大文档分数 |
| hits.hits._source | 查询到的数据 |
| hits.hits.id | 某文档的主键 |
批量操作
批量操作是指,一批命令同时执行(减少IO),这些命令不一定是同种类型。
使用_bulk
命令可以进行文档的批量增删改。
POST _bulk{ "update" : { "_index" : "user", "_id" : "1" } }{ "doc" : {"age" : 18} }{ "create" : { "_index" : "user", "_id" : "2" } }{ "name" : "小明","age":32,"city":"beijing" }{ "create" : { "_index" : "user", "_id" : "3" } }{ "name" : "小红","age":21,"city":"sjz" }{ "create" : { "_index" : "user", "_id" : "4" } }{ "name" : "mark","age":22,"city":"tianjin" }{ "delete" : { "_index" : "user", "_id" : "4" } }
以上命令更新了id为1文档的年龄,新增id为2、3、4的文档,再删除id为4的文档。
上边的命令堆在一起不方便看,下面单独写看,方便读者查看。
批量新增
POST _bulk{ "create" : { "_index" : "user", "_id" : "2" } }{ "name" : "小明","age":32,"city":"beijing" }{ "create" : { "_index" : "user", "_id" : "3" } }{ "name" : "小红","age":21,"city":"sjz" }{ "index" : { "_index" : "user", "_id" : "4" } }{ "name" : "mark","age":22,"city":"tianjin" }
create
命令是只有文档不存在,才会插入,index
会判断如果存在就更新,不存在就插入。
批量更新
POST _bulk{ "update" : { "_index" : "user", "_id" : "1" } }{ "doc" : {"age" : 18} }{ "update" : { "_index" : "user", "_id" : "2" } }{ "doc" : {"age" : 20} }
和新增一样,update
命令下一行需要紧跟这data数据。
批量删除
POST _bulk{ "delete" : { "_index" : "user", "_id" : "3" } }{ "delete" : { "_index" : "user", "_id" : "4" } }
批量查找
批量查找,使用_mget
关键字,批量查找如果不跨越索引,也具有简写形式。
GET /_mget{"docs": [{"_index": "user","_id": "1"},{"_index": "user","_id": "2"}]}# 还可以简写形式POST /user/_mget{"ids": ["1","2","3"]}
DSL查询
Elasticsearch提供了一个完整的基于JSON的查询DSL(领域特定语言)来定义查询。可以将查询DSL看作查询的AST(抽象语法树),它由两种类型的子句组成:Leaf query clauses(叶查询子句)和Compound query clauses(复合查询子句)
以上摘自官网,简单来说,DSL就是将查询条件放到JSON中,进行查询。
Leaf query clauses在特定字段上查找特定的值,例如match
、term
、range
查询等等。
Compound query clauses将叶查询子句和其他符合查询子句结合起来,例如bool
查询等等。
match
match是一个标准查询,当查询一个文本的时候,会先将文本分词。当查询确切值的时候,会搜索给定的值,例如数字、日期、布尔或者被not_analyzed的字符串。
GET /user/_search{"query": {"match": {"name":"小明"}}}
上面的操作会先将“小明”分词为“小”、“明”(当然具体还要看你的分词器),然后再去所有文档中查找与之相匹配的文档,并根据关联度排序返回。
match_phrase
match_phrase会保留空格,match会把空格忽略。
GET /user/_search{"query": {"match_phrase": {"name":"小 明"}}}
注意,分词是空格会给前一个元素,比如上面的字符串分子之后是,“小 ”,“明”。
multi_match
多字段查询,一个查询条件,看所有多个字段是否有与之匹配的字段。后面我们也可以使用
should
更加灵活。
GET /user/_search{"query": {"multi_match": {"query": "哈哈","fields": [ "name","city" ]}}}
match_all
匹配所有,并可设置这些文档的
_score
,默认_score
为1,辣条君认为这里没有计算_score
,所以速度会快很多。
GET /user/_search{"query": {"match_all": { "boost" : 1.2 }}}
boost
参数可以省略,默认是1。
term
term是一种完全匹配,主要用于精确查找,例如数字、ID、邮件地址等。
GET /user/_search{"query": {"term": {"age": 18}}}
terms
terms是term多条件查询,参数可以传递多个,以数组的形式表示。
GET /user/_search{"query": {"terms": {"age":[18,21]}}}
wildcard
通配符,看示例容易理解,通配符可以解决分词匹配不到的问题,例如'haha' 可以通过'*a'匹配。
GET /user/_search{"query": {"wildcard": {"name":"*a"}}}
exists
查看某文档是否有某属性,返回包含这个
Filed
的文档。
GET /user/_search{"query": {"exists": {"field": "name"}}}
fuzzy
返回与查询条件相同或者相似的匹配内容。
GET /user/_search{"query": {"fuzzy": {"name":"mjjlt"}}}
搜索条件是mjjlt
,可以搜出来name为pjjlt
的文档。这个操作是不是在百度的时候经常见到呢?
ids
多id查询,这个id是主键id,即你规定或者自动生成那个。
GET /user/_search{"query": {"ids": {"values":[1,2,3]}}}
prefix
前缀匹配
GET /user/_search{"query": {"prefix": {"name":"pj"}}}
range
范围匹配。参数可以是 gt(大于)、gte(大于等于)、lt(小于)、lte(小于等于)
GET /user/_search{"query": {"range": {"age":{"gt":1,"lt":30}}}}
regexp
正则匹配。value是正则表达式,flags是匹配格式,默认是ALL,开启所有。更多格式请戳
GET /user/_search{"query": {"regexp": {"name":{"value": "p.*t","flags": "ALL"}}}}
bool
bool 可以用来组合其他子查询。其中常包含的子查询包含:must、filter、should、must_not
must
must
内部的条件必须包含,内部条件是and
的关系。如查看所有name中包含“小”并且age是32的用户文档。
GET /user/_search{"query": {"bool" : {"must": [{"term" : { "name" : "小" }},{"term" : { "age" : 32 }}]}}}
filter
filter
是文档通过一些条件过滤下,这是四个关键词中唯一和关联度无关的,不会计算_score,经常使用的过滤器会产生缓存。
GET /user/_search{"query": {"bool" : {"filter": {"term" : { "name" : "小" }}}}}
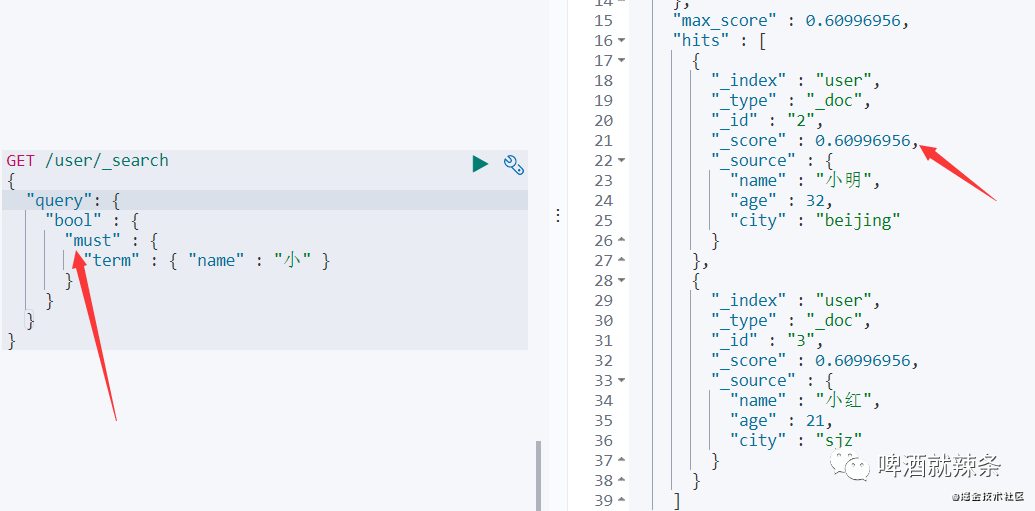
对比两张图可以看出,filter并没有计算_score,搜索速度较快。
must_not
这个和must
相反,文档某字段中一定不能包含某个值,相当于“非”。
should
should
可以看做or
的关系,例如下面查询name包含"小"或者年龄是18岁的用户。
GET /user/_search{"query": {"bool" : {"should": [{"term" : { "name" : "小" }},{"term" : { "age" : 18 }}]}}}
聚合查询
Elasticsearch除全文检索功能外提供的针对Elasticsearch数据做统计分析的功能。可以查询某组数据的最大最小值,分组查询某些数据。
Metric(指标): 指标分析类型,如计算最大值、最小值、平均值等等 (对桶内的文档进行聚合分析的操作)
Bucket(桶): 分桶类型,类似SQL中的GROUP BY语法 (满足特定条件的文档的集合)
Pipeline(管道): 管道分析类型,基于上一级的聚合分析结果进行在分析
Metric(指标)数据
常用数学操作
这里常用的数学操作有
min
(最小)、max
(最大)、sum
(和)、avg
(平均数)。注意这些操作只能输出一个分析结果。使用方式大同小异。
GET /user/_search{"aggs" : {"avg_user_age" :{"avg" : { "field" : "age" }}}}
以上示例查询所有用户的平均年龄,返回所有文档和聚合查询结果。aggs
是聚合查询关键词,avg_user_age
是查询名称,用户可以自行定义。
cardinality
计算某字段去重后的数量
GET /user/_search{"aggs" : {"avg_user" :{"cardinality" : { "field" : "age" }}}}
可以计算,所有文档中年龄不相同的文档个数。
percentiles
对指定字段的值按从小到大累计每个值对应的文档数的占比,返回指定占比比例对应的值。
默认统计百分比为**[ 1, 5, 25, 50, 75, 95, 99 ]**
GET /user/_search{"aggs" : {"avg_user" :{"percentiles": { "field" : "age" }}}}# 返回值(省略文档部分,只分析结果部分)"aggregations" : {"avg_user" : {"values" : {"1.0" : 12.0,"5.0" : 12.0,"25.0" : 20.25,"50.0" : 29.0,"75.0" : 57.75,"95.0" : 123.0,"99.0" : 123.0}}}
可以看出,前1%的用户小于12岁,5%的用户小于12岁,25%的用户小于20.25岁,50%的用户小于29岁。。。
percentile_ranks
percentiles是通过百分比求出文档某字段,percentile_ranks是给定文档中的某字段求百分比。
GET /user/_search{"aggs" : {"avg_user" :{"percentile_ranks":{"field" : "age","values" : [18, 30]}}}}# 返回值(省略文档部分,只分析结果部分)"aggregations" : {"avg_user" : {"values" : {"18.0" : 18.51851851851852,"30.0" : 54.44444444444445}}}
可以看出,小于等于18岁的用户有18.52%,小于等于30岁的用户有54.4%。
top_hits
top_hits可以得到某条件下top n的文档。
GET /user/_search{"aggs": {"avg_user" : {"top_hits": {"sort": [{"age": {"order": "asc"}}],"size": 1}}},"size": 0}
取年龄最小的那一个。
Bucket(桶)
类似于分组的概念。
terms
根据给定的filed分组,返回每组多少文档。
GET /user/_search{"aggs" : {"avg_user" :{"terms": {"field": "city"}}}}
以上根据城市分组,看每个城市有多少用户。
ranges
根据区间分组
GET /user/_search{"aggs": {"price_ranges": {"range": {"field": "age","ranges": [{ "to": 20 },{ "from": 20, "to": 30 },{ "from": 30 }]}}}}
可以查看每个年龄层的用户数量。
还有些很有趣的指令,例如[IP range]可以根据ip段区间分组,以后用到再说吧,希望文本可以不段更新的说...
