





第一个坑:ES 是准实时的?
当你更新数据至 ES 且返回成功提示,你会发现通过 ES 查询返回的数据仍然不是最新的。这究竟是为什么?
想要解答这个问题,就要先从「数据索引」说起。整个过程涉及 ES 的分片,Lucene Index、Segment、Document 三者之间关系。
ES 的一个分片就是一个 Lucene Index,每一个 Lucene Index 由多个 Segment 构成,即 Lucene Index 的子集就是 Segment。
关于 Lucene Index、Segment、 Document 三者之间的关系,你看完下面这张图就一目了然了。
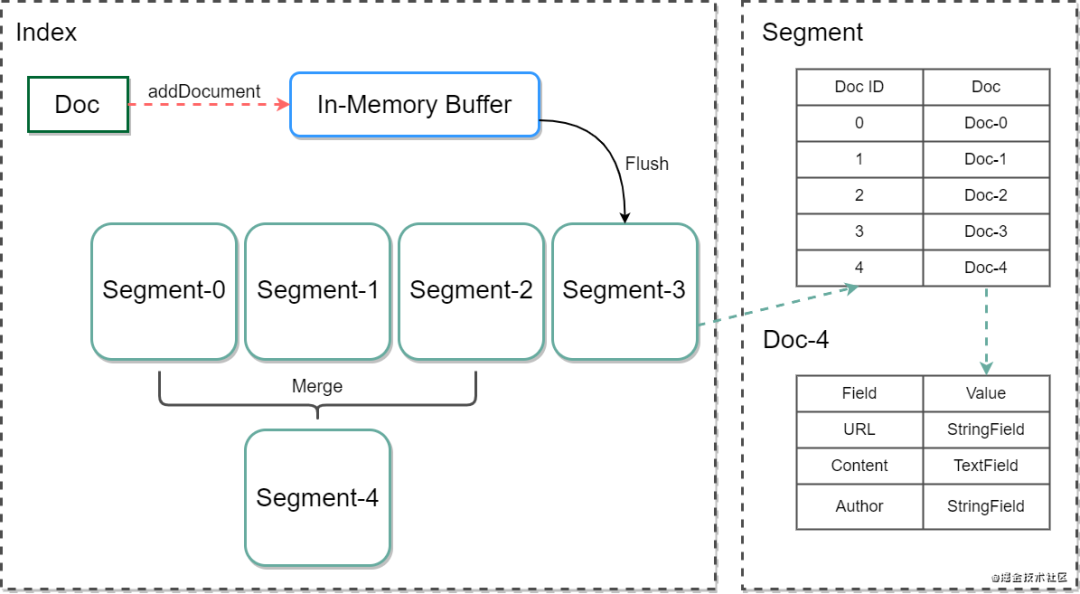
一个 Lucene Index 可以存放多个 Segment,而每个 Segment 又可以存放多个 Document。
而数据索引的过程包含以下步骤。
当新的 Document 被创建,数据首先会存放到新的 Segment 中,同时旧的 Document 会被删除,并在原来的 Segment 上标记一个删除标识。当 Document 被更新,旧版 Document 会被标识为删除,并将新版 Document 存放新的 Segment 中。
Shard 收到写请求时,请求会被写入 Translog 中,然后 Document 被存放 memory buffer 中,最终 Translog 保存所有修改记录。(注意:memory buffer 的数据并不能被搜索到。)
每隔 1 秒(默认设置),refresh 操作被执行一次,且 memory buffer 中的数据会被写入一个 Segment 并存放 filesystem cache 中,这时新的数据就可以被搜索到了。
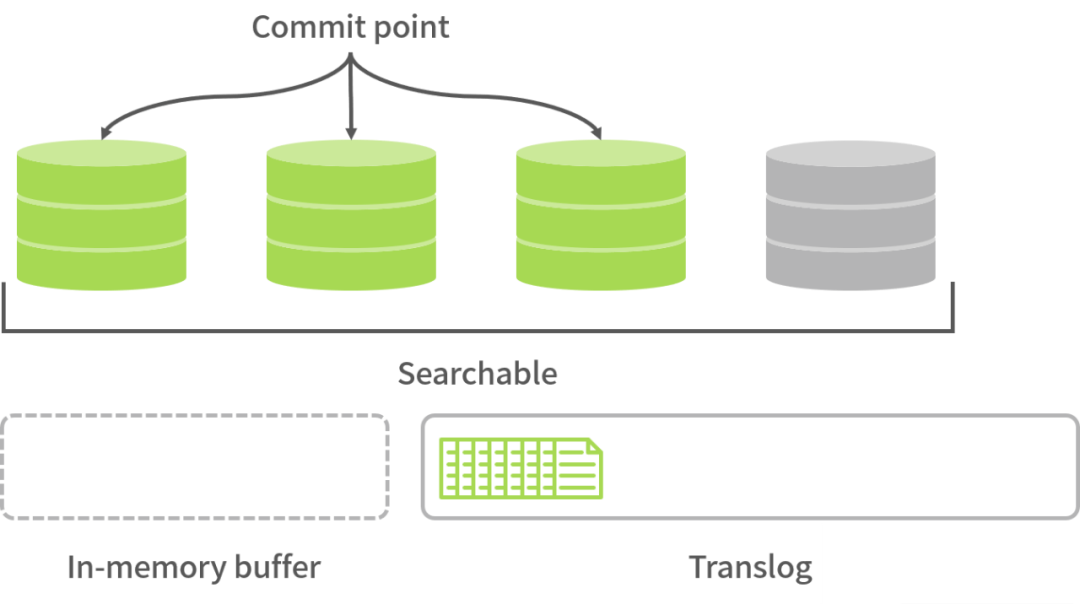
通过以上数据索引过程的说明,我们发现 ES 并不是实时的,而是有 1 秒延时,提示用户查询的数据会有一定延时即可。
第二个坑:ES 宕机恢复后,数据丢失
每隔 1 秒(根据配置),memory buffer 中的数据会被写入 Segment 中,此时这部分数据可被用户搜索到,但没有被持久化。比如上图中灰色的桶,一旦 ES 宕机,数据将会丢失。
如何防止数据丢失呢?
使用 Lucene 中的 commit 操作就能轻松解决这个问题:将多个 Segment 合并保存到磁盘中,再将灰色的桶变成绿色的桶。
不过,使用 commit 操作存在一点不足——耗 IO,从而引发 ES 在 commit 之前宕机的问题。
一旦系统在 translog fsync 之前宕机,数据也会直接丢失,如何保证 ES 数据的完整性便成了亟待解决的问题。
遇到这种情况,我们采用 translog 解决就行,因为 translog 中的数据不会直接保存在磁盘中,只有 fsync 后才保存,这里我分享两种解决方案。
将
Index.translog.durability
设置成request
,如果我们发现系统运行得不错,采用这种方式即可;将
Index.translog.durability
设置成fsync
,每次 ES 宕机启动后,先将主数据和 ES 数据进行对比,再将 ES 缺失的数据找出来。
Translog 何时会 fsync?
当
Index.translog.durability
设置成request
后,每个请求都会 fsync,不过这样影响 ES 性能。这时我们可以把Index.translog.durability
设置成fsync
,那么每隔Index.translog.sync_interval
后,每个请求才会 fsync 一次。
第三个坑:分页越深,查询效率越慢
ES 分页这个坑的出现,与 ES 的读操作请求的处理流程密切关联,为此我们有必要先深度剖析下 ES 的读操作请求的处理流程。
主要分为两个阶段。
Query Phase:协调的节点先把请求分发到所有分片,然后每个分片在本地查询建一个结果集队列,并将命令中的
Document id
以及搜索分数存放队列中,再返回给协调节点,最后协调节点会建一个全局队列,归并收到的所有结果集并进行全局排序。Fetch Phase:协调节点先根据结果集里的
Document id
向所有分片获取完整的Document
,然后所有分片返回完整的Document
给协调节点,最后协调节点将结果返回给客户端。
在整个 ES 的读操作流程中,Elasticsearch 集群实际上需要给协调节点返回 shards number*(from+size)
条数据,然后在单机上进行排序,最后返回给客户端这个 size
大小的数据。
比如有 5
个分片,我们需要查询排序序号从 10000
到 10010
(from=10000,size=10)的结果,每个分片到底返回多少数据给协调节点计算呢?
告诉你不是 10
条,是 10010
条。
也就是说,协调节点需要在内存中计算 10010*5=50050
条记录,所以在系统使用中,如果用户分页越深查询速度会越慢,也就是说并不是分页越多越好。
那如何更好地解决 ES 分页问题呢?
为了控制性能,我们主要使用 ES 中的 max_result_window
配置,这个数据默认为 10000
,当 from+size > max_result_window
,ES 将返回错误。
由此可见,在系统设计时,我们一般需要控制用户翻页不能太深,而这在现实场景中用户也能接受,这也是我之前方案采用的设计方式。
要是用户确实有深度翻页的需求,我们再使用 ES 中 search_after
的功能也能解决,不过就是无法实现跳页了。
我们举一个例子,查询按照订单总金额分页,上一页最后一条 order 的总金额 total_amount
是 10
,那么下一页的查询示例代码如下:
{
"query": {
"bool": {
"must": [
{
"term": {
"user.user_name.keyword": "李大侠"
}
}
],
"must_not": [],
"should": []
}
},
"from": 0,
"size": 2,
"search_after": [
"10"
],
"sort": [
{
"total_amount": "asc"
}
],
"aggs": {}
}
这个 search_after
里的值,就是上次查询结果的排序字段的结果值。
“赞”和“在看”,双连支持!

