




前面总结整理过关于有无直方图的多种情况下优化器如何估算选择性与基数,Oracle11g直方图种类、收集策略与估算公式整理.docx - 墨天轮文档 (modb.pro),里面缺少一种情况,谓词越界后的范围查询,最近遇到一个优化案例,谓词过滤条件是一个小于某值的范围查询,条件列上有直方图,优化器估算的基数为1,我们猜测可能是因为发生了谓词越界,但是依据前面对于有直方图的情况下优化器基数估算的研究中,我们知道超出界值后,选择性是呈坡度递减的,也就是说优化器对谓词越界有一定的容忍度,那么这个案例中优化器估算基数为1,一个同事对这个优化器返回的基数有点儿好奇,优化器到底如何估算的,勇哥让我做做实验研究一下,可以作为上次总结的一个补充。那我们就分情况看一下当查询范围是小于最小值或大于最大值时优化器如何估算列的选择性与基数的。
测试表:
create table test1114 as select * from dba_objects;
exec dbms_stats.gather_table_stats('SCOTT','TEST1114');
下面针对object_type列做小于最小值查询实验。
首先看一下表与列的信息。
SQL> select object_type,count(*) from test1114 group by object_type order by 1;
OBJECT_TYPE COUNT(*)
------------------- ----------
CLUSTER 10
CONSUMER GROUP 25
CONTEXT 7
DATABASE LINK 1
DESTINATION 2
DIMENSION 5
DIRECTORY 8
EDITION 1
EVALUATION CONTEXT 15
FUNCTION 306
INDEX 5297
INDEX PARTITION 686
INDEXTYPE 9
JAVA CLASS 23165
JAVA DATA 309
JAVA RESOURCE 837
JAVA SOURCE 2
JOB 16
JOB CLASS 14
LIBRARY 186
LOB 1310
LOB PARTITION 1
MATERIALIZED VIEW 3
OPERATOR 55
PACKAGE 1320
PACKAGE BODY 1259
PROCEDURE 162
PROGRAM 19
QUEUE 40
RESOURCE PLAN 10
RULE 1
RULE SET 23
SCHEDULE 3
SCHEDULER GROUP 4
SEQUENCE 230
SYNONYM 28133
TABLE 2980
TABLE PARTITION 409
TABLE SUBPARTITION 32
TRIGGER 627
TYPE 2913
TYPE BODY 240
UNDEFINED 11
VIEW 5174
WINDOW 9
XML SCHEMA 54
46 rows selected.
SQL> select num_rows,num_distinct,num_nulls from user_tab_col_statistics tc,user_tables t where tc.table_name=t.table_name and tc.table_name='TEST1114' AND COLUMN_NAME='OBJECT_TYPE';
NUM_ROWS NUM_DISTINCT NUM_NULLS
---------- ------------ ----------
75923 46 0
1. 无直方图
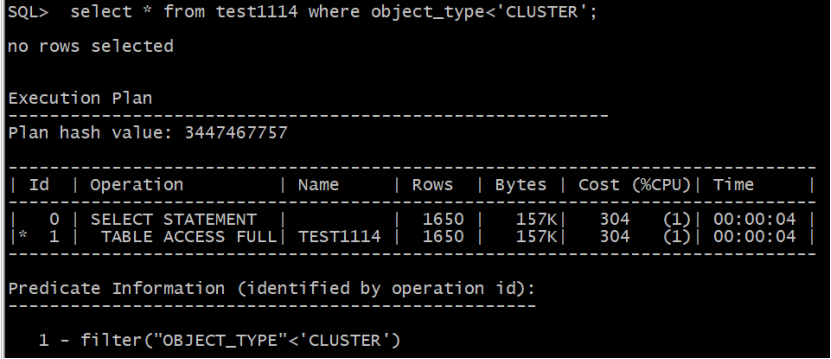
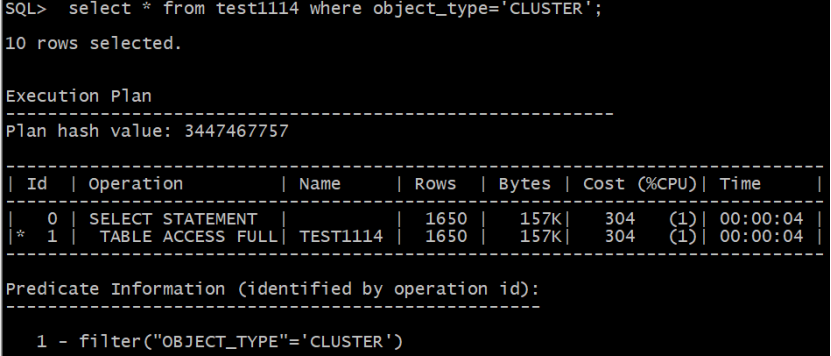
从上面的实验可以看出,谓词条件 object_type='CLUSTER'与object_type<'CLUSTER'优化器估算的基数都是1650, 也就是说超出界值的范围估算与等于这个过滤值的估算结果相同。
此1650的得来是由公式 card=num_rows* (1/num_distinct)*(num_rows-num_nulls)/num_rows
=75923*(1/46)*(75923-0)/75923
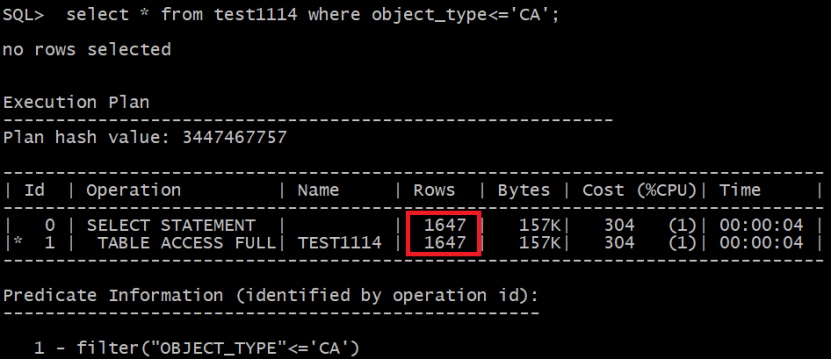
当小于一个小于最小值的值时,rows在衰减,推测即使没有直方图,越界之后的估算会乘以一个偏移界值的一个偏移矫正比例:1-(val-low_value)/(high_value-low_value),也就是没有直方图优化器对越界也有一个容忍度。
我们待会用数字类型的列做实验验证一下。
2.频率直方图
收集直方图
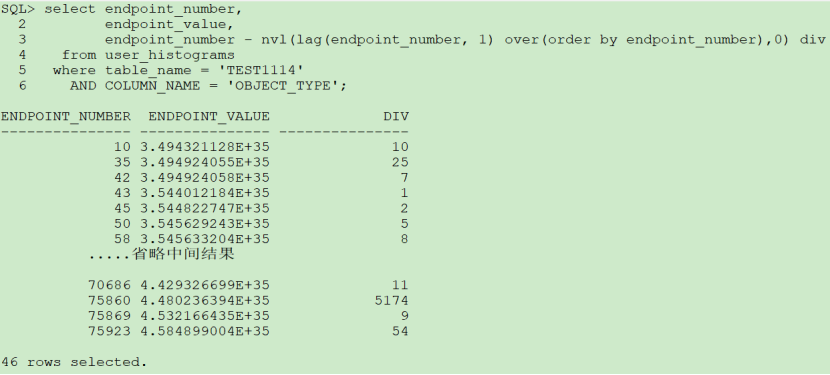
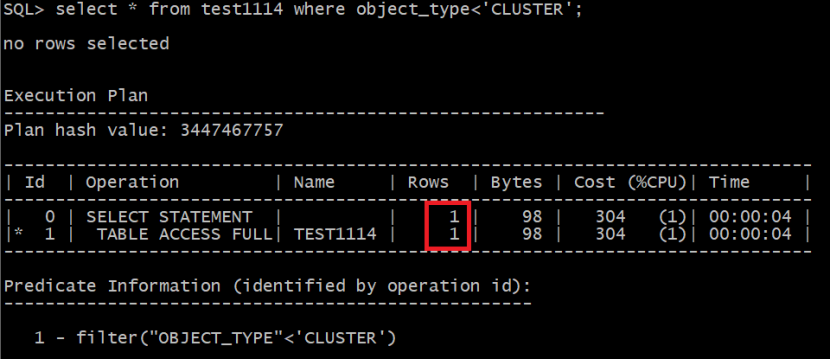
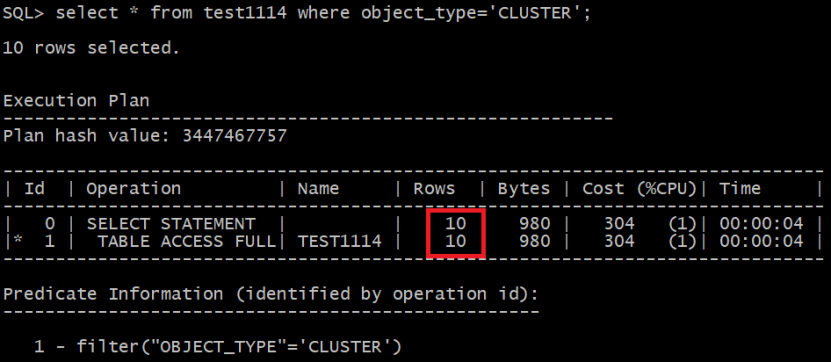
从实验中可以看出,谓词条件 object_type='CLUSTER'与object_type<'CLUSTER'优化器估算的基数是不同的。
object_type<'CLUSTER'是按照非endpoint_value的等值过滤公式来计算的。
公式为:
card=num_rows*sel=num_rows*((num_rows-num_nulls)/num_rows *( min(BucketSize)/2/Last(endpoint_number))*(1-(low_value-val)/(high_value-low_value)))
=(75923-0)*(1/2/75923)*1=0.5
object_type='CLUSTER'是按照endpoint_value值来计算,直接根据直方图中信息计算相应桶中装的数据。此值为第一个桶。
从计算非endpoint_value的公式可以看出,对于频率直方图,如果min(BucketSize)值越小,则非endpoint_value的估算的基数就会很小。
3.等高直方图
重新收集直方图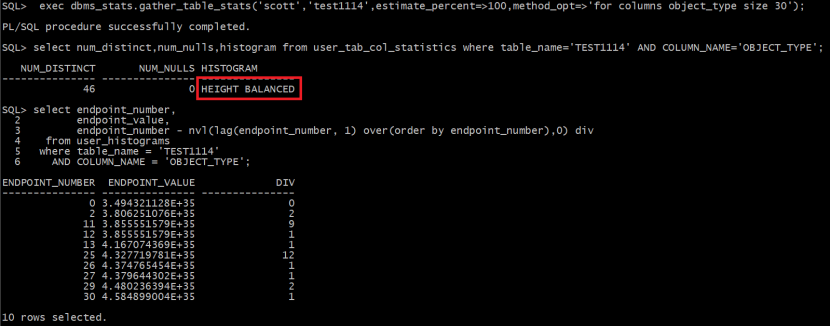
从直方图信息来看,共收集了30个桶,其中popular value值有4个,共占2+9+12+2=25个桶
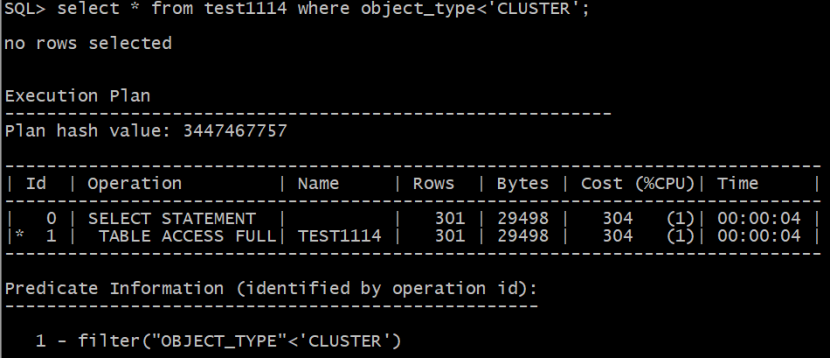
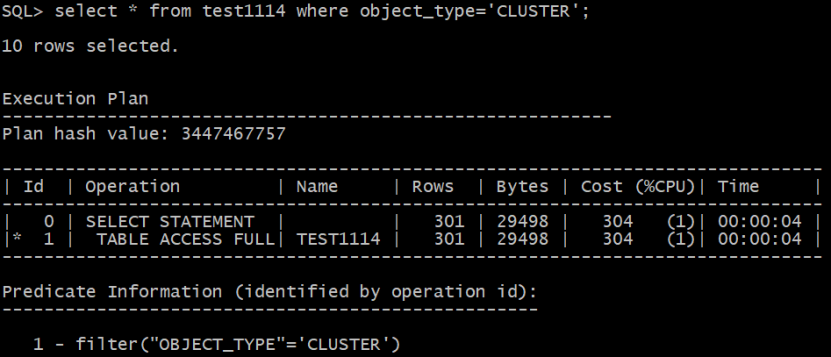
从实验中可以看出,谓词条件 object_type='CLUSTER'与object_type<'CLUSTER'优化器估算的基数是相同的,优化器估算的基数都是301。
其计算公式如下:
Card=((Buckets_total - Buckets_all_popular_value)/Buckets_total/(num_distinct - popular_values.count))*(num_rows-num_nulls)*(1-(val-high_value)/(high_value-low_value))
=((30-25)/30/(46-4))*(75923-0)*1=301
从公式中可以看出,对于等高直方图,如果唯一值越多,poplular_value越少,极端情况下没有popular值,其公式就可以近似等价于无直方图的情况。因此对于唯一值特别多,近似等于非空行数,收集统计信息是没有意义的。
工作中发现很多对于date类型或timestamp类型的列,其存储的值精确到秒或微秒,唯一值个数近似等于非空行数,这样的列上oracle默认也收集了直方图,其实收集直方图的没有意义。超出统计信息的界值后的范围查询返回基数估算近似为1,这种情况下对于越界范围查询几乎没有容忍度,如果大表统计信息收集不及时,很容易导致谓词越界,选错执行计划的情况发生。
下面验证一下无直方图时,越界后查询估算是否是乘以偏移矫正率。
准备数据:
truncate table test1114;
insert into test1114 select * from dba_objects;
update test1114 set object_id=trunc(dbms_random.value(1,1000)) wherer object_id>2000;
commit;(不做处理的话,估算的值都是1,公式无法得到验证)
exec dbms_stats.gather_table_stats('scott','test1114',method_opt=>'for columns object_id size 1');
查询统计信息
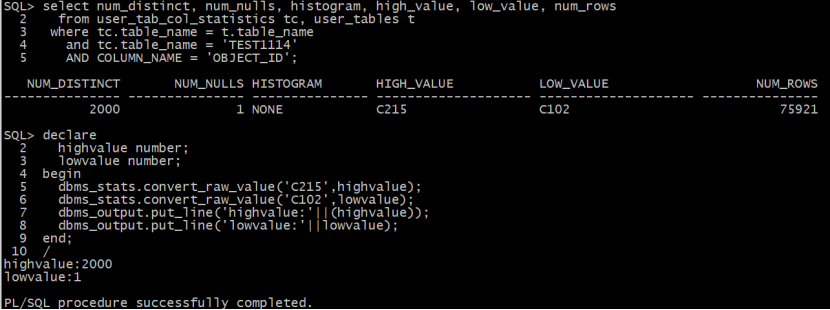
Object_id列最小值为1,最大值为2000。
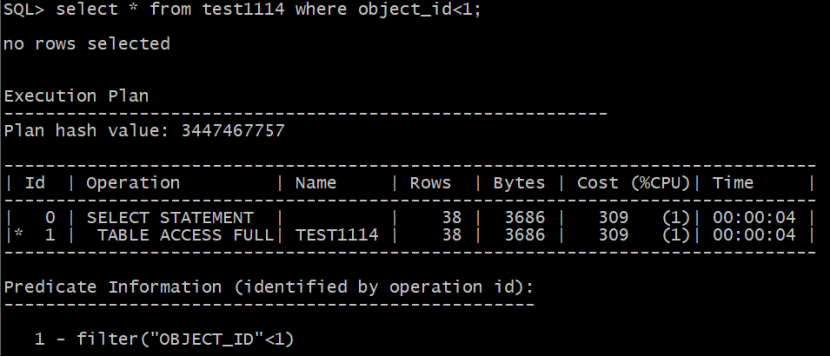
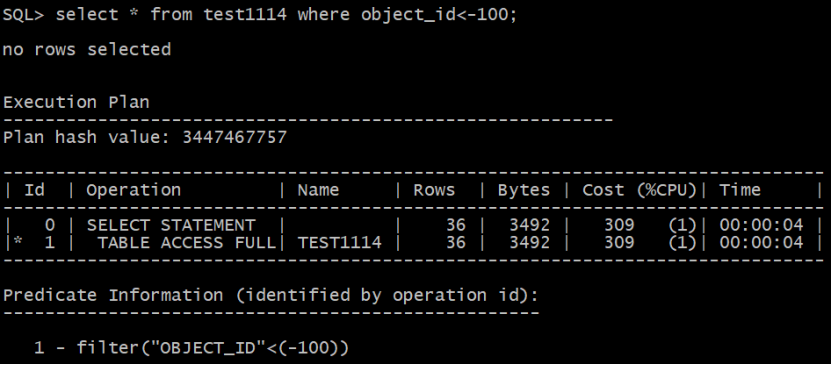
1为最小值,object_id<1 估算时偏移矫正率为1,object_id<-100时,偏移矫正率为1-(low_value-val)/(high_value-low_value)=1-(1-(-100))/(2000-1)
Object_id<1的估算:
num_rows*(1/num_distinct*(num_rows-num_nulls)/num_rows)
=75921*(1/2000)*((75921-1)/75921)*1
Object_id<-100的估算:
num_rows*(1/num_distinct*(num_rows-num_nulls)/num_rows)*(1-(low_value-val)/(high_value-low_value))
=75921*(1/2000)*((75921-1)/75921)*(1-(1-(-100))/(2000-1))
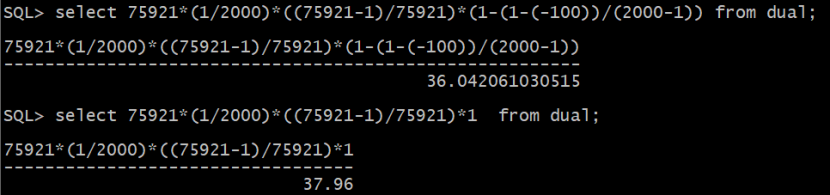
根据公式计算出的基数与执行计划总优化器返回的基数是吻合的,可以验证公式是正确的。
总结:
1.谓词过滤条件是范围查询的,且查询范围越界后的估算:
即col1 < val 而val<min(col1)或者Col1>val 而val>max(col1)
越界范围估算的与等值估算公式相同。而越界的等值估算与处于high_value与low_value值之间的等值估算相比,无论是否是否有直方图,都是正常范围内的估算再乘以偏移矫正率。即对越界都有一定的容忍度。
2.唯一值特别多,接近于非空数据行时,收集等高直方图没有意义,越界后基数估算值就会接近1.
3.收集频率直方图时,最小桶的size对非endpoint_value的估算影响很大,最小桶size很小时,范围内的非endpoint_value值估算与越界后的基数估算都会是接近1。
