




数据库属于基础软件,在信息系统中的重要性不断增强,今天最广泛采用的 RDBMS 技术,也已经经历了50年的发展演进历程。然而在中国国产数据库领域,仍然存在“卡脖子”的难题,那么问题来了,数据库的发展,究竟是难在研发,还是难在生态?
前文回顾 > 国产数据库发展十策(一):开发一个数据库到底需要多少人?
目录
国产数据库的起点
在互联网上,有一张珍贵的照片渊远流传,照片来自1977年在黄山召开第一届数据库学会会议,第二排左七是中国数据库的泰斗萨师煊老师,这一年被认为是中国数据库的起点,这一年中国刚刚恢复高考。同样是1977年,一家名为“Software Development Laboratories (SDL)”的公司在美国硅谷注册成立,后来它的另外一个名字更广为人知 - Oracle。

传闻Oracle的名字来源于Larry Ellison 为 CIA 执行的一个项目,这个传闻是真的,在 CIA 的解密文件上能够看到这个项目:Project ORACLE. (下图有彩蛋,欢迎火眼金睛,留言反馈)

中国的学术界开始研究数据库,美国的工业界已经开始研发关系型数据库,差距就此拉开;而自90年代开始,Oracle、Sybase、DB2、Informix等产品纷纷进入中国,并且占据了垄断地位;在那之后的2000年左右,国产数据库的产品才刚刚推出迈向市场;时至今日,国产数据库才进入快速发展期,一大批创业企业、创新产品不断涌向市场,2011年巨杉成立,2015年PingCAP成立,2020年云和恩墨发布MogDB数据库产品…
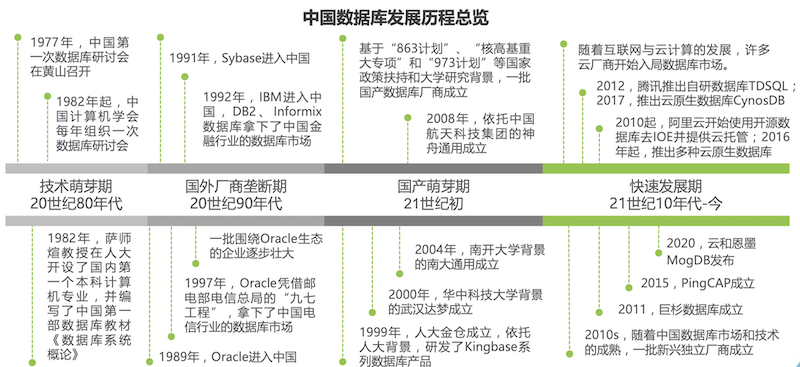
回顾历史,今天我们更加知道,数据库产业要想实现发展超越,产学研用必须要要同步推进,才有可能消除短板、加速生长。
IBM和Oracle的机遇
RDBMS 数据库的历史机遇首先光顾了 IBM,今天几乎已经是众所周知,E.F.Codd 的论文改变了数据库的历史,但是 Oracle 比IBM更敏感的认识到了历史机遇,Larry Ellison 背后还有一位天才的程序员 Bob Miner,他们结识于 AMPEX公司,这个公司的名字在 CIA 的解密文件中随处可见。
照片中右二就是这位天才的程序员,在开始创业后的一年之内,Bob就成功的用编汇语言(Assembly Language)实现了RDBMS,此后,版本2,版本3的更新也几乎都是他一个人完成的代码编写工作。直到1992年Oracle版本7,Bob一直都是技术小组的领军人物。
现在 Oracle的代码中,还能找到 Bob Miner 的痕迹,在 catalog5.sql 文件中,注释中有 Miner 在1984年留下的注释:Rewrite for new dictionary but it still looks much the same to users。
Miner 上面那一行的注释者就是前面我们提到的 Andy,他于1984年加入Oracle,工作至今,成为了Oracle数据库新一代的研发掌门人。
紧接着,有人在1992年,修正了 Bob 的一些 mistakes。

Bob Miner 为Oracle奠基的 Rollback Segment 技术,可以说是一笔不可估量的技术财富,指引 Oracle 数据库发展演进,直至今日。
达梦和金仓的差异化选择
在中国数据库领域,最早期的研发者就包括冯玉才老师,他在1988年研发了数据库系统 CRDS,这也成为了达梦数据库的前身。达梦数据库的版本 2.0 在1996年发布。率先起步的先发优势,让达梦选择了自主研发的道路,成为了今天国产数据库领域为数不多的全自研产品。
达梦公司创立于2000年,从这一年开始,达梦开始作为一家商业化数据库公司,展开了冯老师的创业征程。
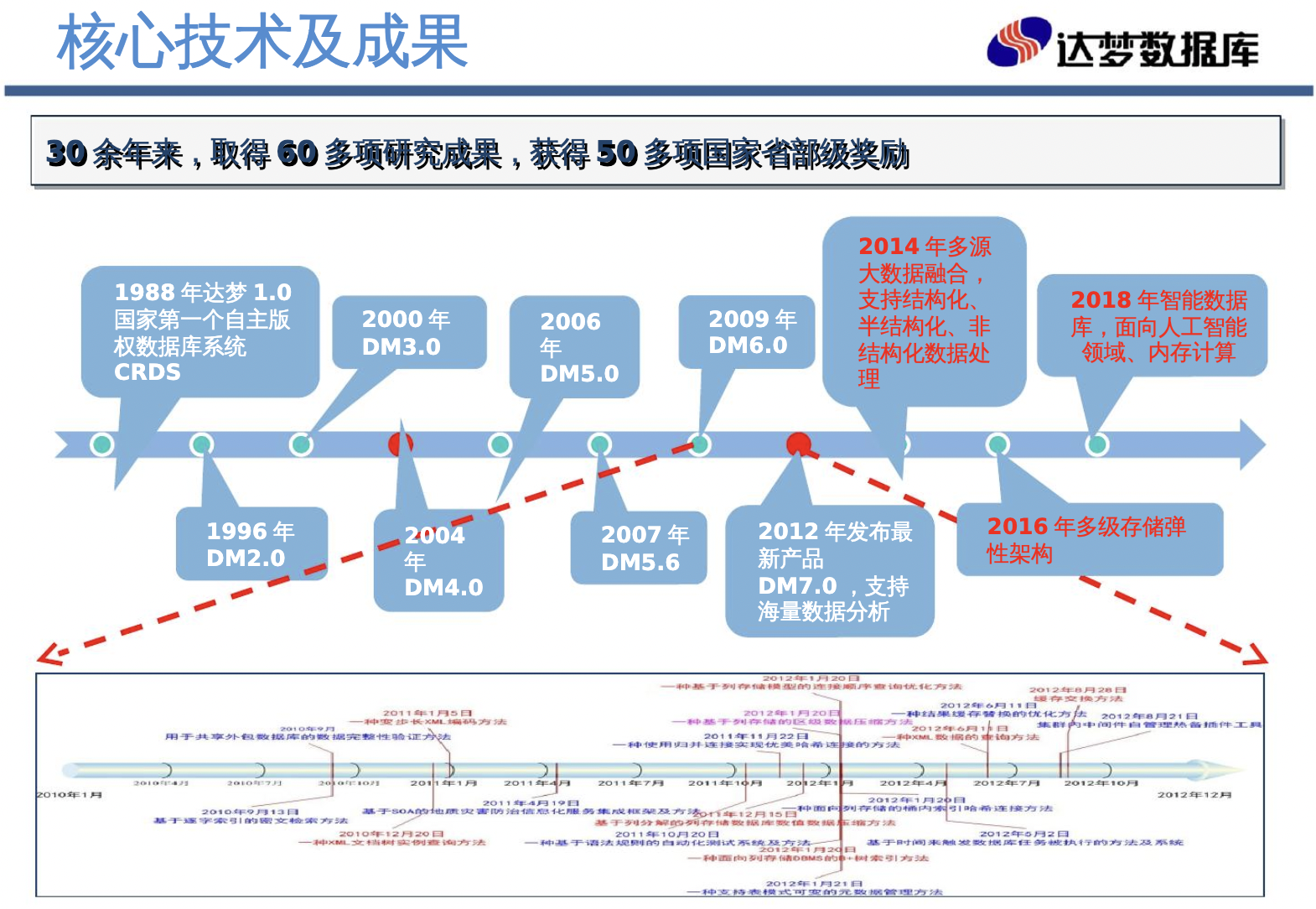
国产数据库的另外一个先驱是来自人民大学的人大金仓,创立于1999年,早于达梦公司。金仓选择的道路是在开源产品 PostgreSQL 上进行自研开发迭代,推出 KingBase 品牌。按照公开信息,Kingbase ES V1.0 在1999年发布。
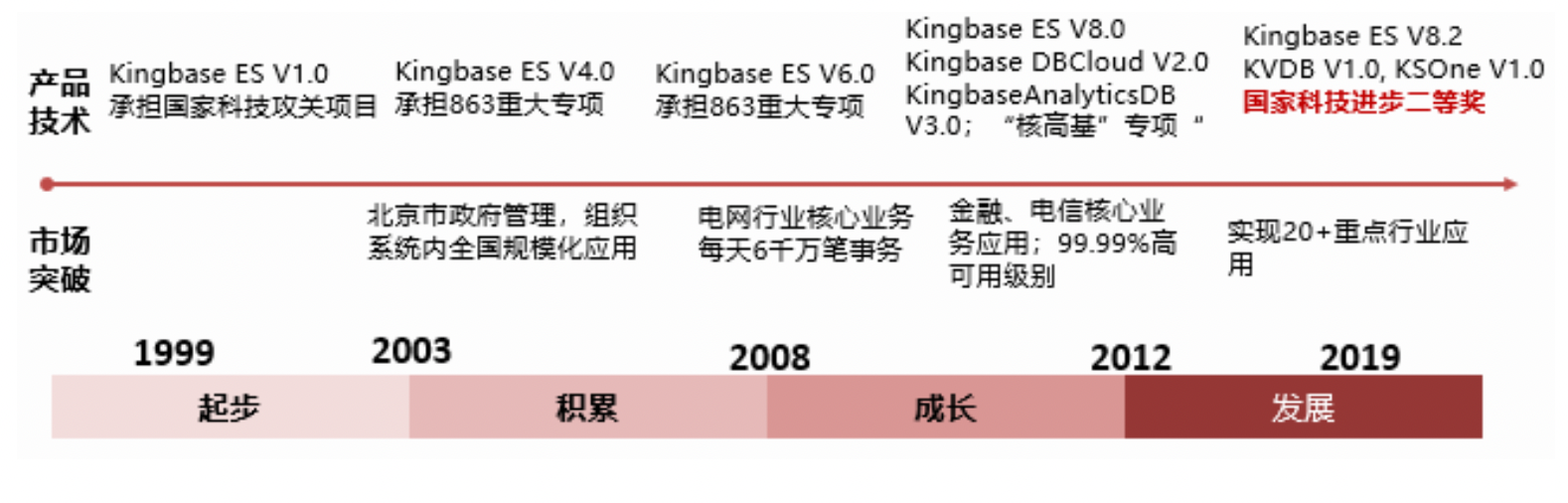
达梦数据库和人大金仓的选择,也是今天众多国产厂商的两条路线:自主研发和开源演进。这两个路线,只要持续投入,在代码上具备自主能力,在知识产权上没有瑕疵,就都能够走得远。
从国产数据库的先驱者来看,在关系型数据库领域,中国的软件研发以及产品化比美国至少晚了20年。但是,正是因为有了这么多前仆后继的奉献者和探索者,中国的数据库演进脉络并未中断。
从Oracle和Sybase看先发者的挑战
在关系型数据库领域,先发者面临着技术路线的选择、探索的挑战,这其中往往就伴随着挫折和失败,所以在RDBMS 50年的技术长河中,很多名噪一时的品牌都渐渐消失的历史的长河中,这其中就包括Informix,Sybase 等产品。
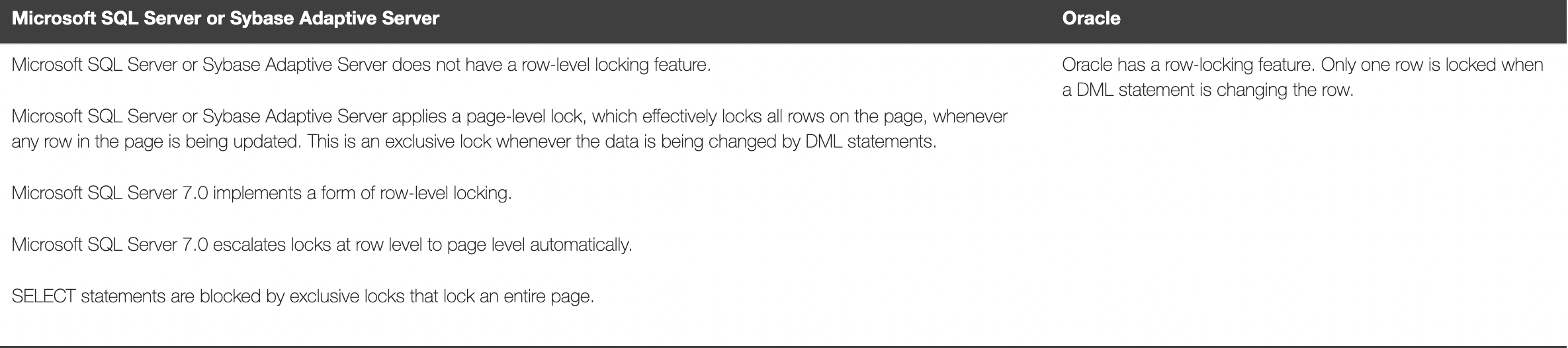
在很多技术方向上,Oracle都是率先的探索者,当 1984年,Oracle 在版本4中实现了一致性读,在Version 6 中实现了行级锁,领先性就被确立下来:

在今天的数据库世界里,你可能很难想象数据库的世界,曾经读可以阻塞写,锁总是加在页之上,直至今日,Oracle的官网上还有这样的对比报告。以下是关于页锁的描述对比:
还有关于一致性读的对比:
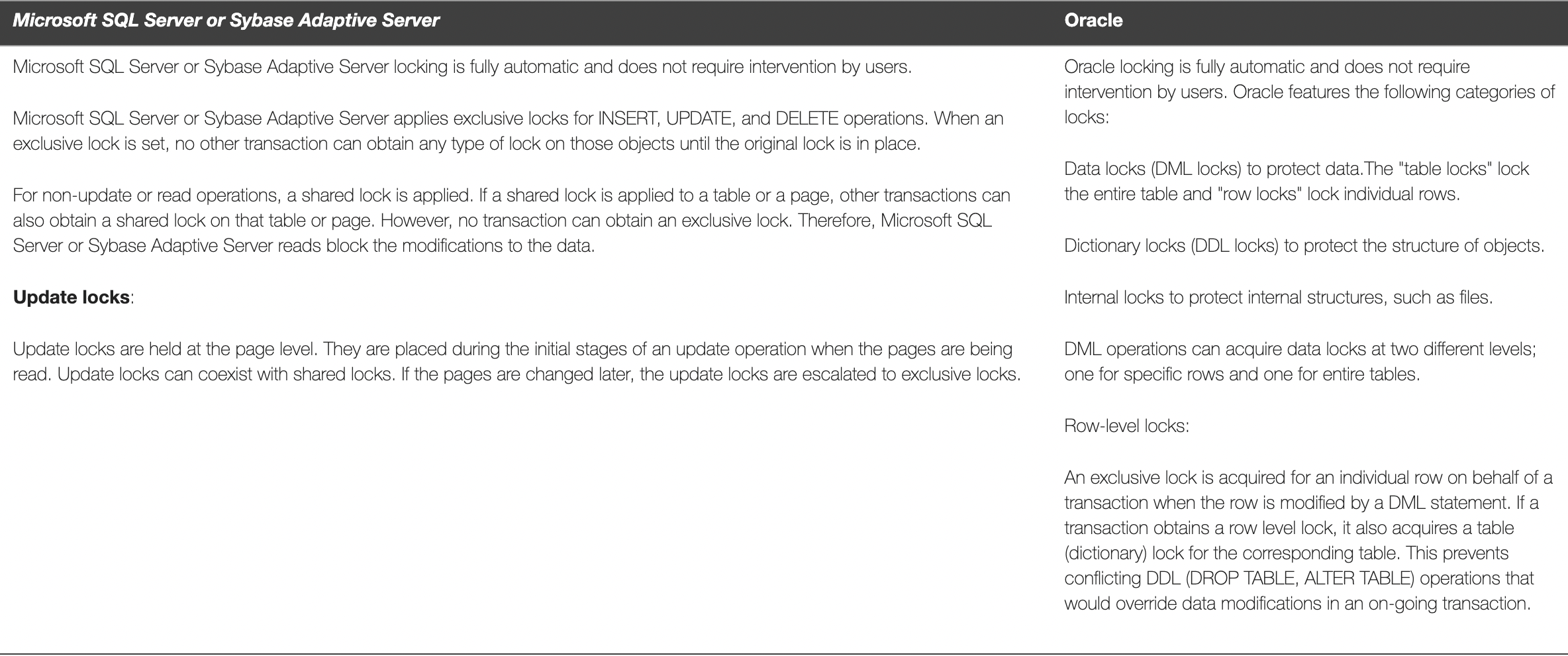
而大约25年前,Sybase 的专家是这样辩驳的:
I cannot think of any application in which a properly designed PLL solution would perform any worse than its RLL counter part (but, as has been pointed out, it may very well take more design effort to achieve these results). And, in fact, I think that for a very large sub-set of these applications, performance can actually improve using PLL.
(在上面的论述中,PLL 指 Page Level Locking,RLL 指 Row Level Locking)。
从openGauss和PolarDB看追赶者的优势
时至今日,RDBMS的理论和实现已经足够成熟,开源数据库也已经做出了完整的呈现,对于追赶者来说,站在前人的肩膀上,已经极大的降低了投入风险。
在最近发布的 openGauss 2.0 版本中,一个重要的特性被推出,这就是:原位更新(Ustore)引擎。原位更新这个词听起来很新鲜,但其实是源自对 PostgreSQL 原有的 Heap 存储引擎的替代。PG 采用追加更新方式存储数据,也就是当修改数据时,不是在原位置修改,而是写入一个新记录,这会导致空间膨胀,也就需要定期回收过期的数据空间。这一直是 PostgreSQL 的一个弱项。
现在 openGauss彻底解决了这个问题,实现了 Undo 机制,也就可以在原位置更新数据。这带来的好处就包括:
- 高性能:对插入、更新、删除等不同负载的业务,性能以及资源使用表现相对均衡,相比Append Update引擎性能提升10%
- 运行平稳:性能运行平稳,8小时性能滚降值从13.8%降低至2.5%
- 高效存储:支持最大限度的原位更新, TPCC负载下平均节约空间15%~20%,UNDO空间统一分配,集中回收,复用效率更高,存储空间使用更加高效、平稳
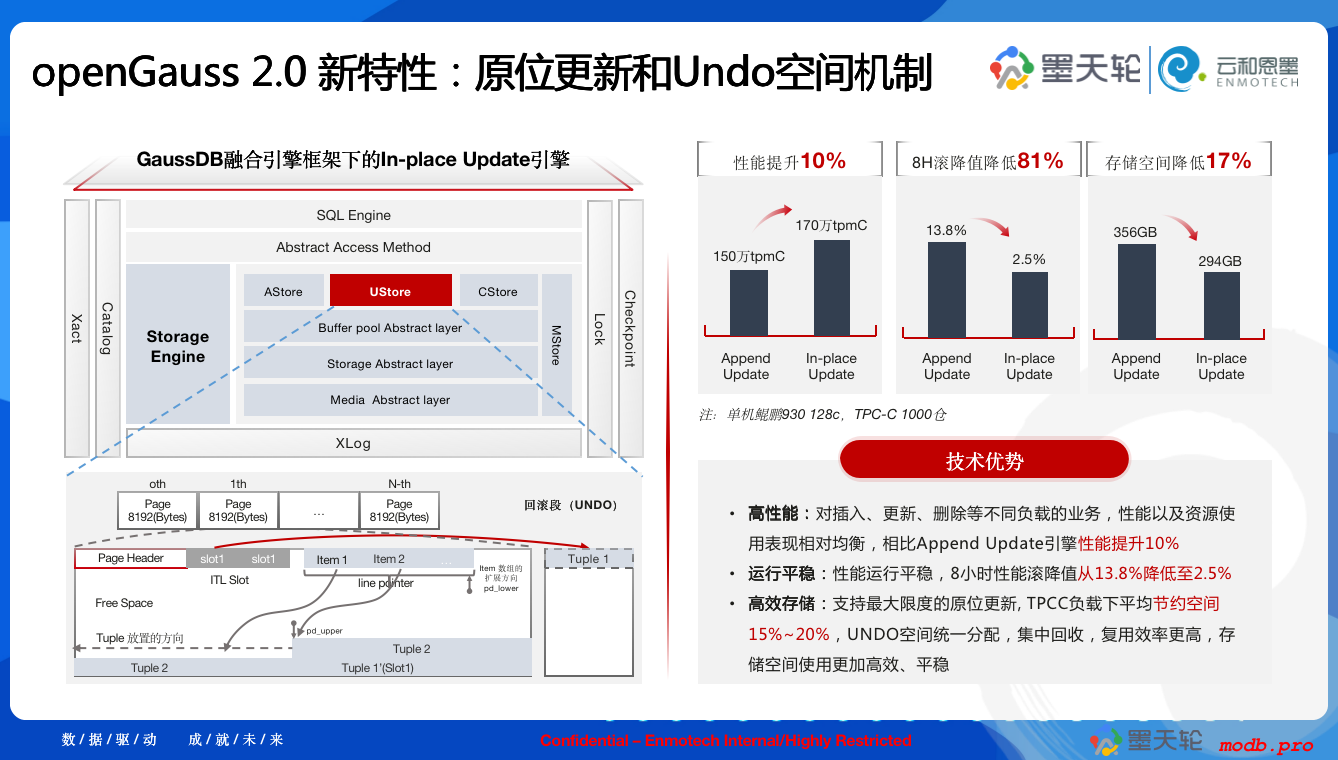
而现在的好处是,以开源的形式,我们可以随时来查看 openGauss 的源码实现,例如以下就是 Ustore 的数据块存储结构:

而在 Oracle 21c 中才出现的区块链表,在 openGauss 2.0 中也已经被实现。关于 Oracle Database 21c vs openGauss 2.0 的特性对比,请参考:Oracle 21c vs openGauss 2.0新特性解析和研讨
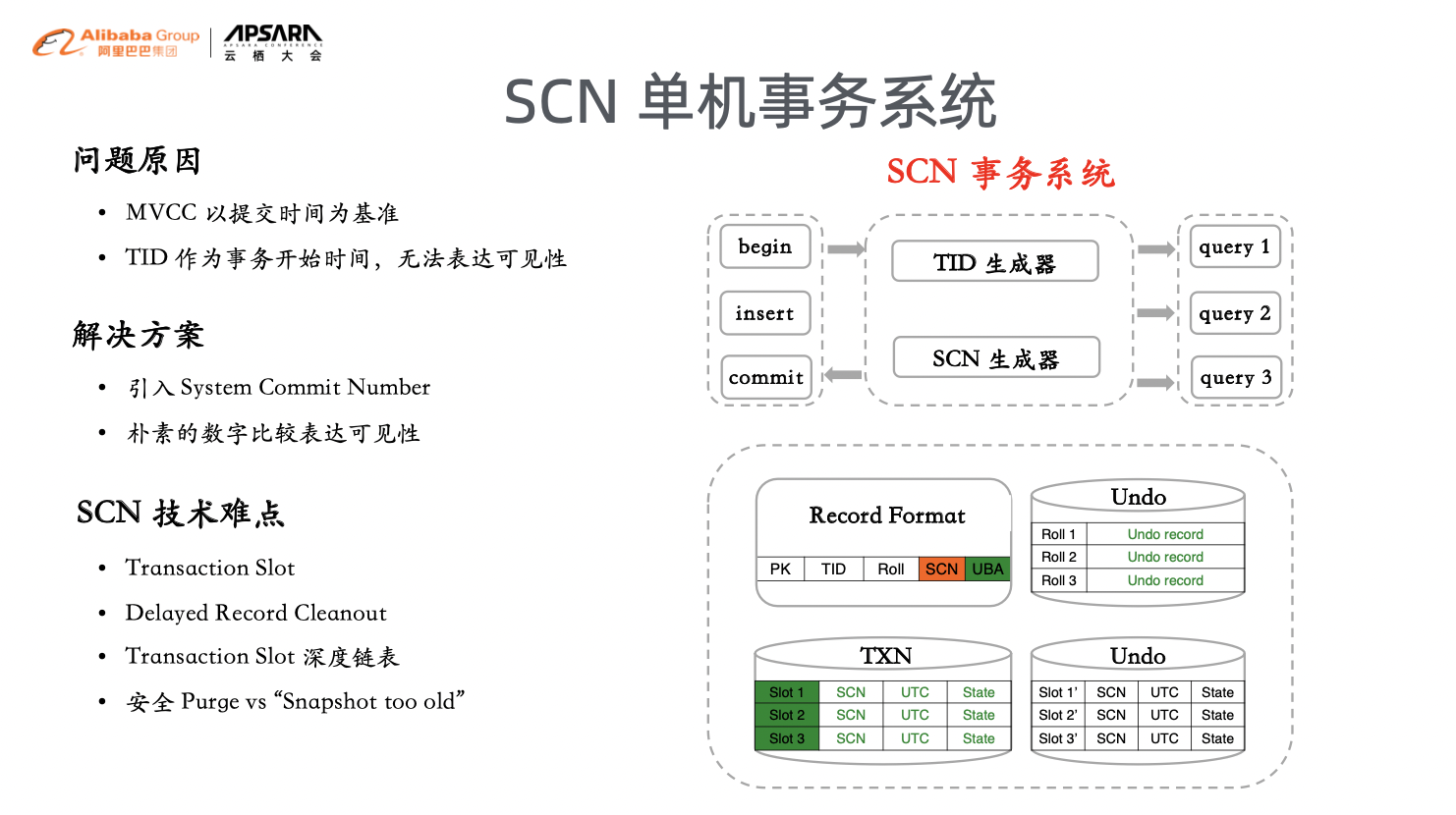
在今年的云栖大会上,PolarDB 开源了 PolarDB-X 分布式数据库,我们注意到阿里云在这个版本中,同样实现了和Oracle类似的一致性读机制,同样通过 SCN 来作为一致性读的基准。那么和Oracle同样的工作机制就都出现了,类似的有,事务槽(Transaction Slot),延迟块清除(Delayed Record Cleanout)等。
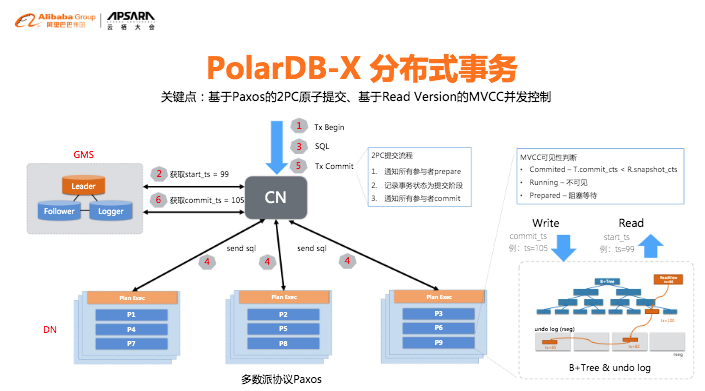
PolarDB-X 的分布式事务,是通过基于 Paxos 的2PC 原子提交实现的,如前所诉,还实现了基于 Read Version 的 MVCC 并发控制。
Paxos 算法是 Leslie Lamport 于 1990 年提出的共识算法,因为一些波折 1998 年才公开发表,后来使其获得2013年的图灵奖。这篇论文以难懂著称,Lamport 被问到忍无可忍,2001 年重新发表了一篇一个公式都没有的论文 ——“Paxos Made Simple”,摘要仅有一句话:
The Paxos algorithm, when presented in plain English, is very simple.
站在前人的肩膀上,无疑让我们走得更快,而我们应当保持同样的开放和分享精神。在国产数据库领域,随着 openGauss、PolarDB、OceanBase 的陆续开源,开源开放也已经成为行业共识。
为什么SQL Server和DB2未形成规模化三方生态?
Oracle 数据库为什么在市场竞争中获胜?在众多因素中,一定有生态这重要一环,生态让产品生根发芽、茁壮成长,最后根深叶茂,影响深远。
在过去十年,云和恩墨在数据库服务领域,服务了超过1000家企业客户,深刻的感受到了Oracle生态圈的覆盖之广、影响之深,同时我们也在思考,为什么商业数据库的第二、第三名(DB2、SQL Server)没有形成类似 Oracle 的强大生态圈?
众所周知,在国内市场,有很多服务类厂商、生态工具厂商围绕Oracle提供产品和解决方案,但是你可能没有见到成规模的 DB2、SQL Server 三方厂商,何解?
我有一个关于技术方向的答案,那就是:开放性。
经常有朋友问我,为什么 Oracle 的DBA生态就这么活跃?我曾经在《Oracle 性能优化与诊断案例》一书中表达过这样一个观点:
“…我听到一句话印象深刻,叫“隐藏的权利感”,我想把这句话应用到数据库,表达一下我的观点。
Oracle数据库,虽然是一个商用数据库不开源,但是它又是非常开放的一个产品,Oracle几乎所有的内部操作,不管是调优的过程还是数据库的各种内部操作,都是可跟踪解析的。比如Oracle数据库的启动和关闭过程,全程是可跟踪的。它的启动关闭会解析成多少个递归操作,我们全都可以跟踪出来。
所以我们做Oracle DBA的工作时,面对任何事情我们都会非常有信心。Oracle开放了各种接口,方法和手段给我们,只要我们去分析研究,就能够把一个问题的Root Cause找出来,接近Root Cause就离解决问题不远了。
一个数据库只有变得更加开放接口,更加开放DeBug功能的,才能让我们在研究这个数据库的时候也可以找到更多的乐趣。我觉得这里面找到的乐趣就是我讲的,是隐藏的权利感。就是我不动声色,但是我知道我在处理接触这个数据库的时候,我有非常强的把控力,我能撼动和解决几乎所有的问题。我觉得这一点对于技术人员是非常重要的。”
Oracle 通过开放性,培养起丰富的人才资源,而除了 Oracle之外,DB2、SQL Server 的技术栈是非常封闭的,至今很多稍微复杂的问题,就只能依赖原厂商的二线支持,而 Oracle数据库,第三方力量几乎可以应对各种异常(除了改代码修Bug)。
当然,我们也可以认为,这个领域只有占据了足够的市场份额,才能够培育起全面的生态市场。
那么我们同样要面临一个严峻的问题:如果说生态只属于第一位的领先者,那么后来者,如何去建设共享的数据库生态,促进国产数据库的成功,就显得更加迫切和重要。
在中信证券的报告:数据库,企业数字化支撑,大数据时代基石,曾经这样描述:
合作伙伴生态是 Oracle 早期占领中国市场的核心要素之一,也是国产数据库厂商未来的战略重点。数据库管理系统是数据管理架构的底层产品,每个客户核心系统架构都不同,意味着需要针对不同客户做大量定制化的开发。集成商、二次开发商、IT咨询公司都是数据库厂商生态伙伴体系中的重要参与者。生态伙伴体系建设能够帮助企业快速实现业务扩张,同时最大程度减少成本的增长,使数据库厂商能将有限的人员和资金投入到数据库技术和产品的开发上。早在 2009 年,Oracle 就推出合作伙伴网络计划(OPN),在当时被认为是十年以来最重大的进展。2013 年 Oracle 大中华区 OPN 成员已达到 2412 家,超过 90%的收入是通过合作伙伴取得的。
东方证券在一份报告中也曾指出:国产基础软硬件,开源、迁移、上云,关键在生态。明确的指出了生态的关键作用。

为什么云数据库成为潮流?
既然生态是数据库成功的关键因素(尤其是对于后来者),我们也就能够理解为什么云数据库成为潮流。
云数据库可以借助云的基础,在云上生长,而无需从头建立生态,从而可以避免生态短板、快速的迈向成功,这也是云原生数据库倍受关注的根本。在 Gartner 发布的2011~2020全球数据库市场格局中,微软在2020年超越了 Oracle 位列第一,而第三名 AWS、第六名 Google、第七名 阿里云、第十名 华为云,无一不是凭借云的优势,在数据库领域争锋:
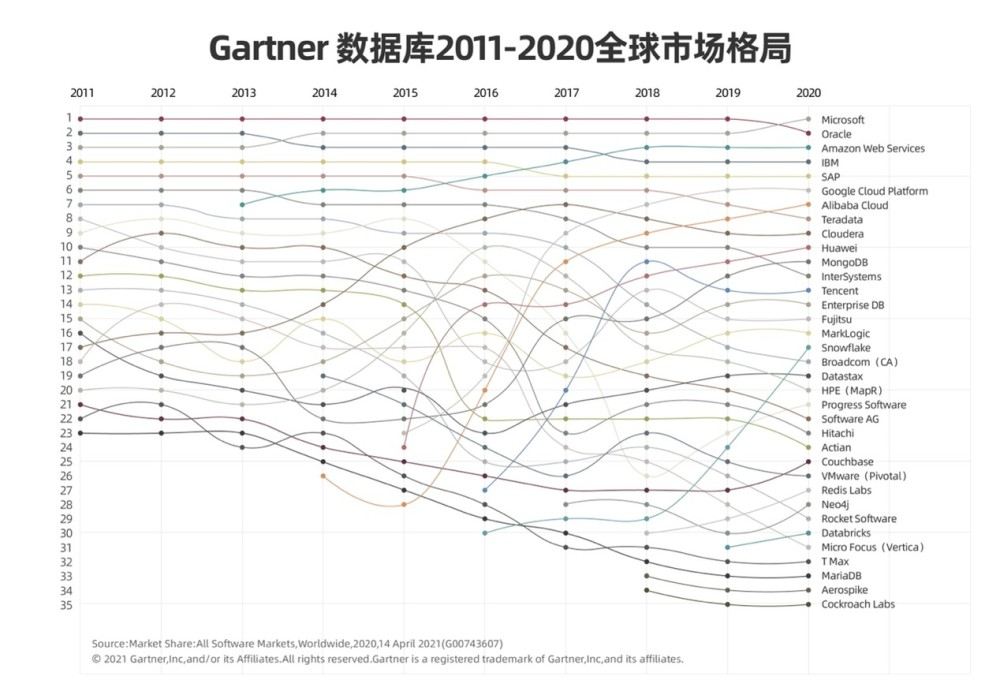
那么是不是云厂商成功了,独立的数据库厂商就不复存在了呢?
我在今年的云栖大会讲过一段话,我认为,"云数据库"让数据库得以永生了。为什么呢?
如果云上的数据库只能由云厂商提供,那么未来独立的数据库厂商都将消亡,但是今天,新的先驱者验证了一条道理,生存之道仍然存在,MongoDB、snowflake 的探索已经初见端倪。在上图中,第11位的 MongoDB、第17位的 Snowflake 都为我们证明了这一点。
在云时代,只有和云共舞、共生,才能在未来的世界生存下来。
策二:数据库生态建设是关键
总结一下,在数据库技术发展的初级探索阶段,技术是关键(一个错误的路线选择可能就让商业上所有的努力灰飞烟灭),而在当下的技术成熟阶段,生态就成为最重要的一环。
中国数据库的发展需要全链条的、全方位的协作,从厂商到企业用户到第三方生态,全流程的都要协同运转起来,我曾经写到,2019年是国产数据库元年。这是因为,在那之前是数据库厂商自己使力气,非常艰难;只有当我们真正意识到这是一个“卡脖子”的问题时,当用户真正做出选择时,国产数据库的春天才真正到来。
我们建议:成立以数据库为中心的生态联盟,构建统一的生态社区平台,通过统一的标准体系,建设具有广泛适应性的认证兼容机制,培养具备多样化服务能力的从业人员,才能对整个行业带来兼容并包的高效率的促进作用。
插播:数据库生态顶级会议:数据技术嘉年华 即将于2021.12.23~24 举办,欢迎报名参会。https://www.modb.pro/dtc2021
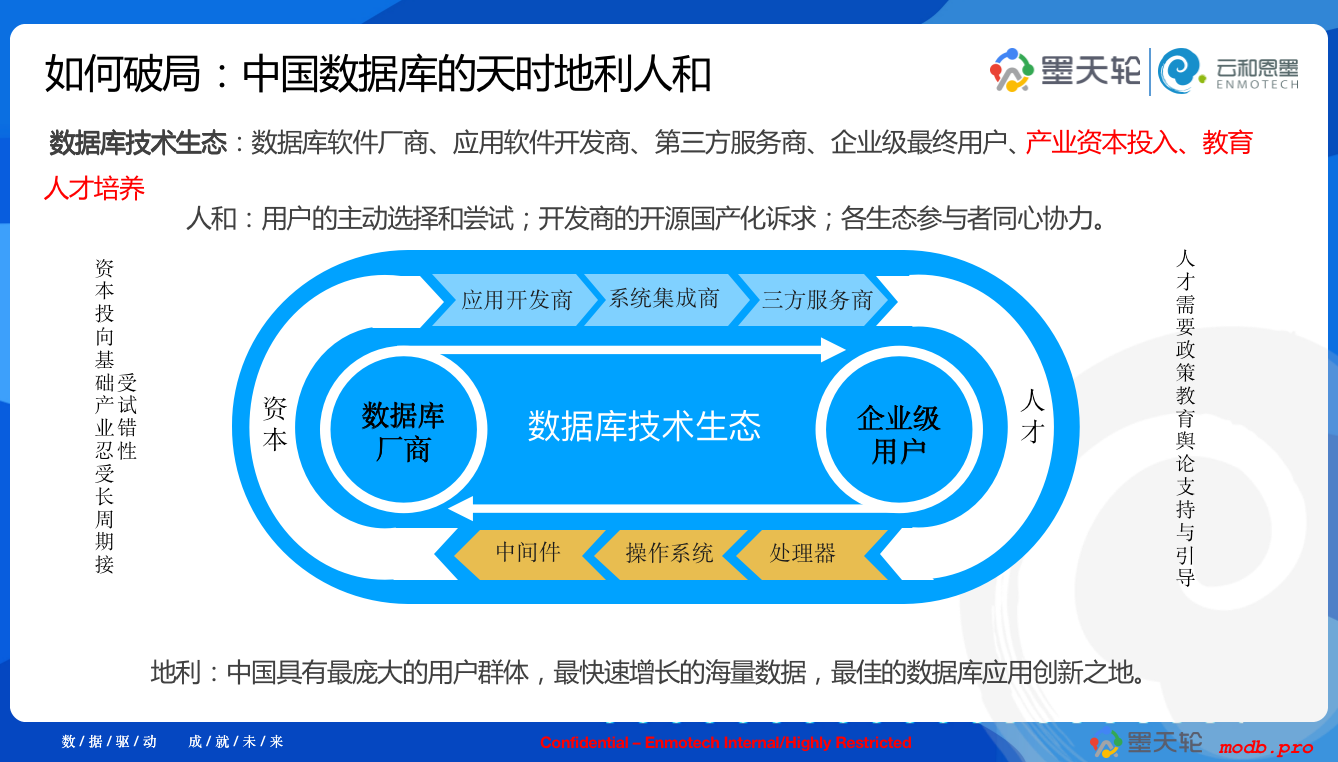
同时,当 160多个国产数据库走向市场时,在行业里更需要能够统一提供服务、生态工具产品的企业,能够作为国产数据库的统一提供商、生态建设者,为用户保驾护航,为厂商助力加油。
2019年参加华为的HC大会时,在一个数据库闭门讨论会,我印象深刻的记得,其中一位与会专家慨然批评国产数据库不好用不能用。我当时的回答是,你如果问国产数据库(仅指我熟悉的OLTP)和Oracle相比好不好用,肯定不好用。我在20年前接触Oracle数据库的时候,也遇到非常多的问题,时至今日,在墨天轮上提问的很多人也会说Oracle很多地方不好用,但是由于 Oracle 建设了非常良好的生态体系、培养了大量的专业工程师,使得用户在遇到问题时,找得到支持,解决得了问题,从而保障了用户的业务运转。
所以国产数据库的发展一定需要不同角色的广泛参与,要有厂商基于国产数据库开发应用软件,要有第三方为国产数据库提供服务,要有机构为国产数据库培养输送人才,要有投资方容忍国产数据库试错成长,唯有如此,国产数据库才能少摔跤,跑得快!
时至今日,国产数据库的发展,一定要全军为上,任何单方面的努力都是单薄无力的,我坚信这正是中国数据库最好的发轫之机。
