




书接上回《DolphinDB初体验——从部署到查询实验》,单节点集群部署之后,接下来放在我面前的一个探索就是,多节点集群怎么部署。
DolphinDB多节点架构
从官网文档来看,DolphinDB多节点一共三种结构,多服务器集群、高可用集群、高可用服务。对三种架构,我做一个大概的解析。在dolphindb里几个节点的对应概念如下
-
控制节点(controller):控制节点是 DolphinDB 集群的核心部分,负责收集代理节点和数据节点的心跳,监控每个节点的工作状态,管理分布式文件系统的元数据和事务日志。多服务器集群中只有一个控制节点。
-
代理节点(agent):代理节点负责执行控制节点发出的启动和关闭数据节点或计算节点的命令。在一个集群中,每台物理服务器有且仅有一个代理节点。
-
数据节点(data node):数据节点既可以存储数据,也可以用于数据的查询和计算。每台物理服务器可以配置多个数据节点。
-
计算节点(compute):计算节点承担数据节点查询和计算的相关职能,负责响应客户端的请求并返回结果,与数据节点共同实现存储资源和计算资源有效隔离。每台物理服务器可以配置零到多个计算节点。
多服务器集群
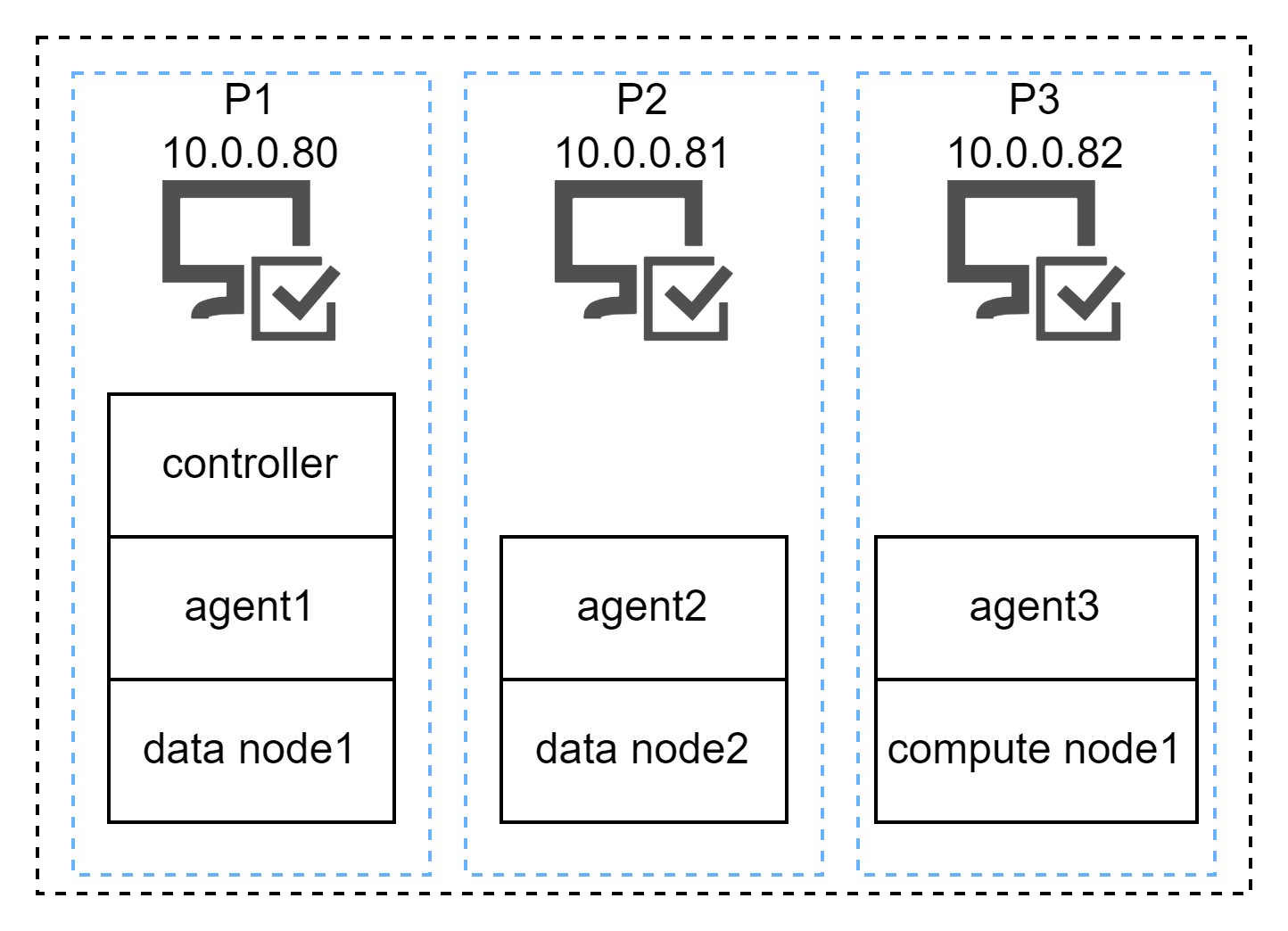
多服务器集群按照官网的架构来看,如果是3节点服务器集群,包含了1个controller,3个agent,2个data node和1个compute node。agent每个服务器必须一个,而controller也是1个,数据节点2个计算节点1个。算是一个比较简洁的方式。
如果是硬件资源有限的情况下,这个架构确实是可以做到既存算分离,又能把资源最大限度利用好。
这个方式不足之处也很明显,存在单点风险。如果controller所在的服务器或者compute node所在的服务器宕机,整个集群就没法正常工作。
高可用集群
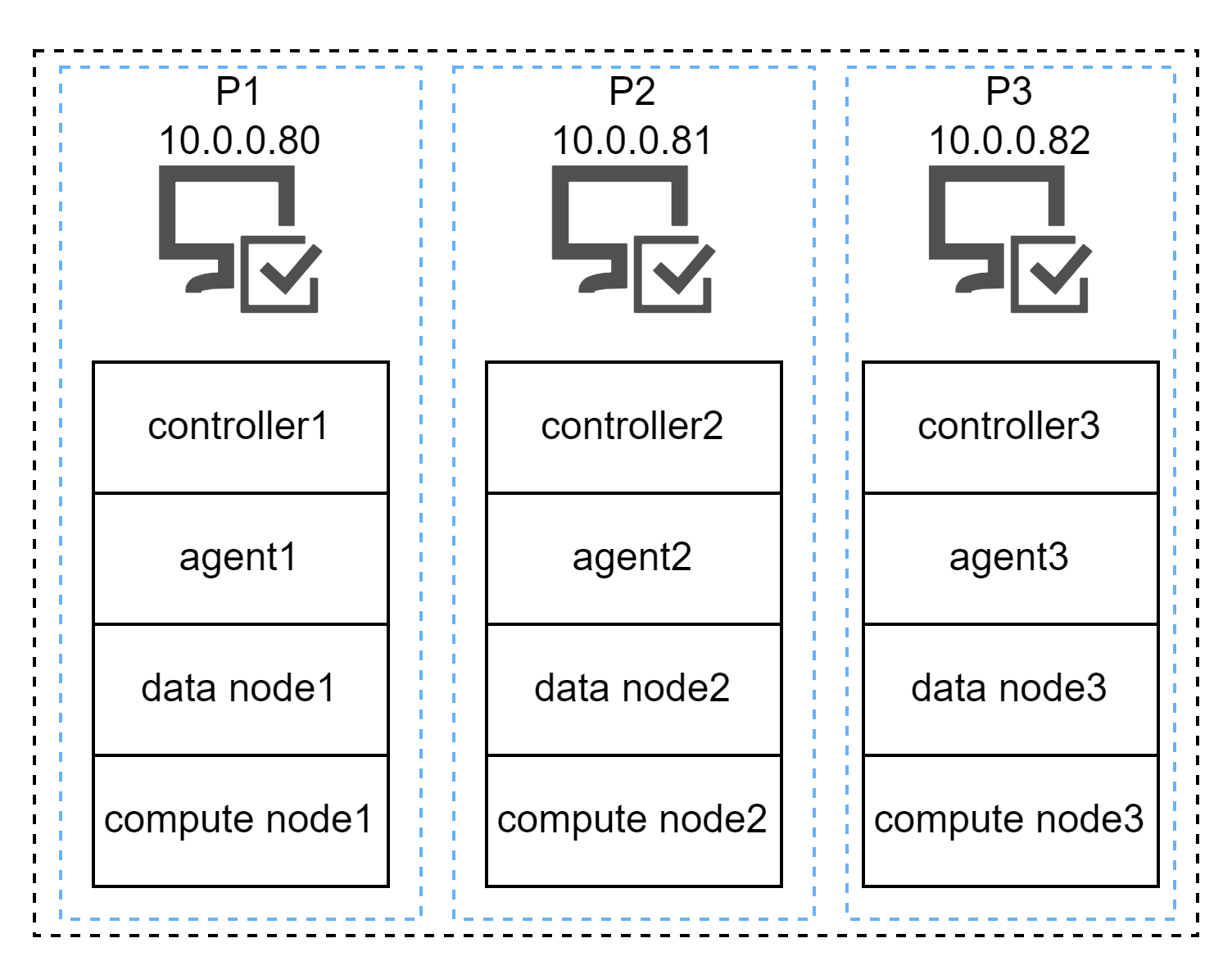
和上一个架构相比,这是一个每个组件都有3份冗余的架构。每一个服务器都包含了1个controller,1个agent,1个data node和1个compute node,或者说,这是一个多节点版的单节点集群(稍微有点绕,用过dolphindb的朋友估计能秒懂)。
这个架构的优势是每个组件都有3节点高可用,之前的单点风险也就消除了。
缺点就是资源存在一定程度的浪费,3个controller,实际生产当中是否需要可能打个问号。
高可用服务
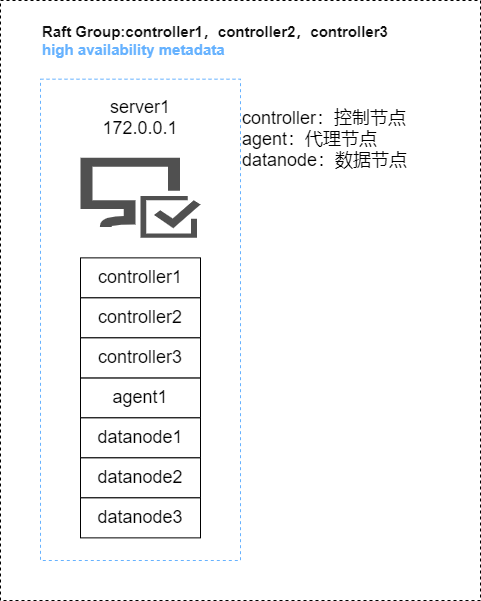
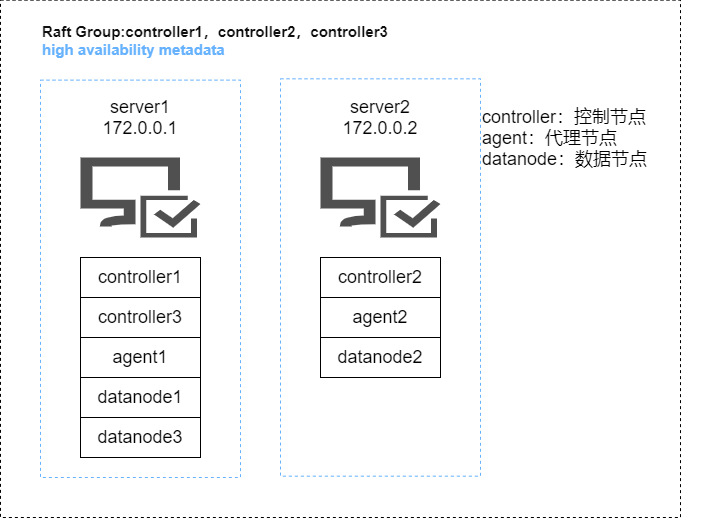
这个架构官网提供了两种,一个是单个服务器版一个双服务器版,除了与服务器数量一一对应的agent,每个服务都部署了3个,取消了compute node,计算的任务全部交给了data node来做。官网给出的词语是伪高可用,也是很贴切的一种描述。除此之外,还有迁移到真正的高可用服务集群的架构图。
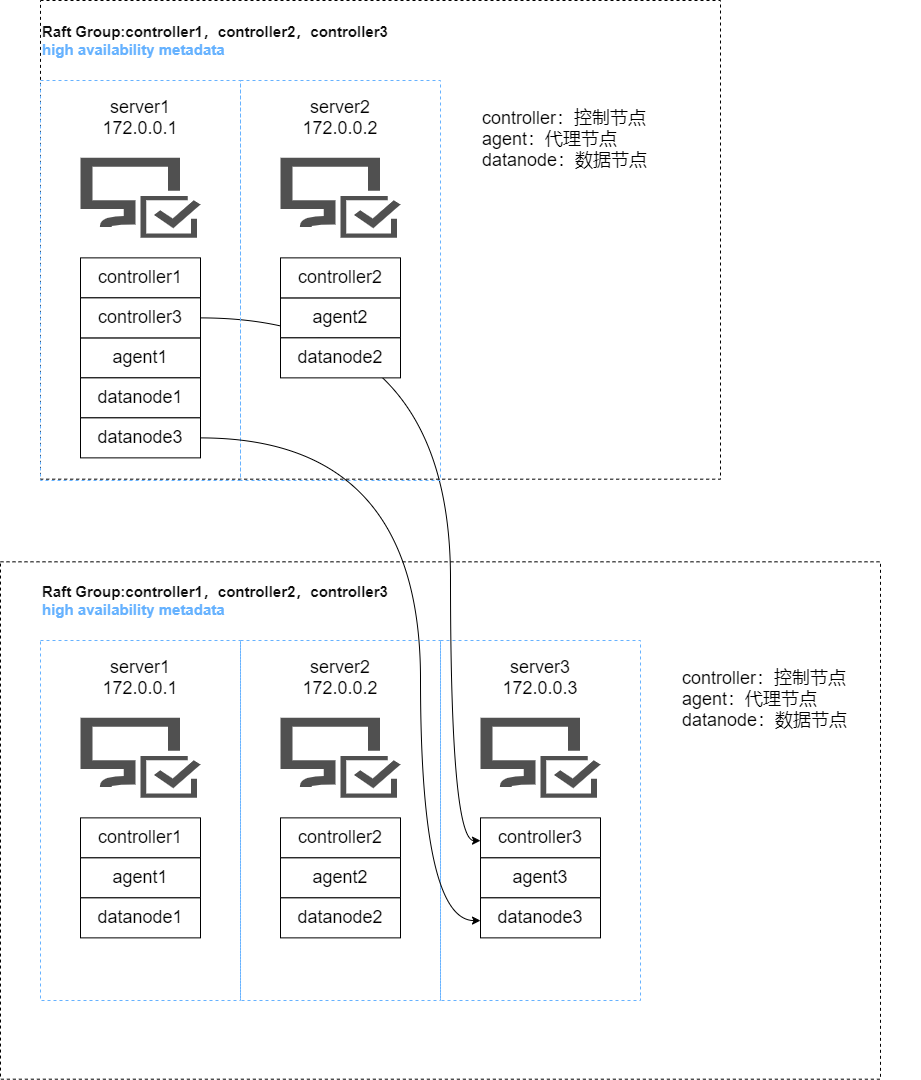
混部DolphinDB集群
那么问题来了,我现在手头有5台服务器,怎么部署既能保证高可用,又能保证系统资源尽量不要太多浪费?于是我咨询了dolphindb的工程师韩工,他给我的建议是:其中3节点按照高可用集群部署,确保每个组件的高可用,另外两台不部署控制节点,做为数据节点或计算节点的扩展。如图所示:
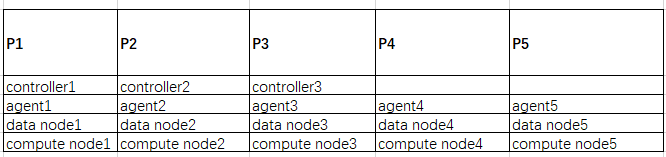
服务器配置:Redhat Linux 8,32c/256GB
1.创建用户
groupadd dolphindb
useradd -g dolphindb dolphindb
passwd dolphindb2.解压安装包并更新授权
su - dolphindbwget https://www.dolphindb.cn/downLinux64-Current.php -O dolphindb.zip
unzip dolphindb.zip -d /home/dolphindb/DolphinDBcp /tmp//dolphindb.lic ~/DolphinDB/server
3.配置高可用集群
接下来配置P1、P2、P3,每一台服务器都是所有组件都配置
cd ~/DolphinDB/server/clusterDemo/config
vim controller.cfg这里修改3个地方,一个是localhost替换成P1/P2/P3各自的IP,第二个是dfsReplicationFactor的参数,修改成controller的实际数量另一个是加入一行新内容,这里的IP也是各自的IP
publicName=xxx.xxx.xxx.xx以我的P1为例,最后的内容是,P2和P3的区别在于IP和controller后面的数字
mode=controller
localSite=192.168.1.1:8900:controller1
dfsReplicationFactor=3
dfsReplicaReliabilityLevel=2
dataSync=1
workerNum=4
localExecutors=3
maxConnections=512
maxMemSize=8
lanCluster=0
maxFileHandles=102400
publicName=192.168.1.1修改cluster.nodes,把整个集群每一个节点配置都放进去,不要遗漏,我的5台服务器配置如下
localSite,mode
192.168.1.1:8900:controller1,controller
192.168.1.2:8900:controller2,controller
192.168.1.3:8900:controller3,controller
192.168.1.1:8901:agent1,agent
192.168.1.1:8902:dnode1,datanode
192.168.1.1:8903:cnode1,computenode
192.168.1.2:8901:agent2,agent
192.168.1.2:8902:dnode2,datanode
192.168.1.2:8903:cnode2,computenode
192.168.1.3:8901:agent3,agent
192.168.1.3:8902:dnode3,datanode
192.168.1.3:8903:cnode3,computenode
192.168.1.4:8901:agent4,agent
192.168.1.4:8902:dnode4,datanode
192.168.1.4:8903:cnode4,computenode
192.168.1.5:8901:agent5,agent
192.168.1.5:8902:dnode5,datanode
192.168.1.5:8903:cnode5,computenode修改cluster.cfg,maxMemSize是服务器最大内存的85%,workerNum是license限制的核心数
maxMemSize=217
maxConnections=512
workerNum=5
localExecutors=3
maxBatchJobWorker=4
OLAPCacheEngineSize=2
TSDBCacheEngineSize=1
newValuePartitionPolicy=add
maxPubConnections=64
subExecutors=4
lanCluster=0
enableChunkGranularityConfig=true
maxFileHandles=102400
subThrottle=1
persistenceWorkerNum=1
datanode1.publicName=192.168.1.1
computenode1.publicName=192.168.1.1
datanode2.publicName=192.168.1.2
computenode2.publicName=192.168.1.2
datanode3.publicName=192.168.1.3
computenode3.publicName=192.168.1.3
datanode4.publicName=192.168.1.4
computenode4.publicName=192.168.1.4
datanode5.publicName=192.168.1.5
computenode5.publicName=192.168.1.5修改完之后,把cluster.nodes和cluster.cfg用scp命令复制到每个节点的同样位置下
最后修改agent.cfg,添加sites参数,把每个节点配置都写上,controllerSite统一成其中一个的配置,localsite是自己agent的配置我的样例如下
mode=agent
localSite=192.168.1.1:8901:agent1
controllerSite=192.168.1.1:8900:controller1
sites=192.168.1.1:8901:agent1:agent,192.168.1.1:8900:controller1:controller,192.168.1.2:8901:agent2:agent,192.168.1.2:8900:controller2:controller,192.168.1.3:8901:agent3:agent,192.168.1.3:8900:controller3:controller,192.168.1.4:8901:agent4:agent,192.168.1.5:8901:agent5:agent
workerNum=4
localExecutors=3
maxMemSize=4
lanCluster=04.配置P和P5
P1/P2/P3的配置全部都完成之后,只修改P4和P5的agent.cfg,两个cluster文件用scp过去的即可
启动DolphinDB集群
全部完成之后,就可以启动了,在P1/P2/P3上执行
cd ~/DolphinDB/server/clusterDemo
sh startController.sh
sh startAgent.sh 在P4和P5执行
cd ~/DolphinDB/server/clusterDemo
sh startAgent.sh 都完成之后,用浏览器登录P1,输入http://192.168.1.1:8900如果所有agent和controller状态都是启动成功,就可以启动cn和dn,点击右上角登录,输入admin/123456,第一次登录之后记得修改admin密码
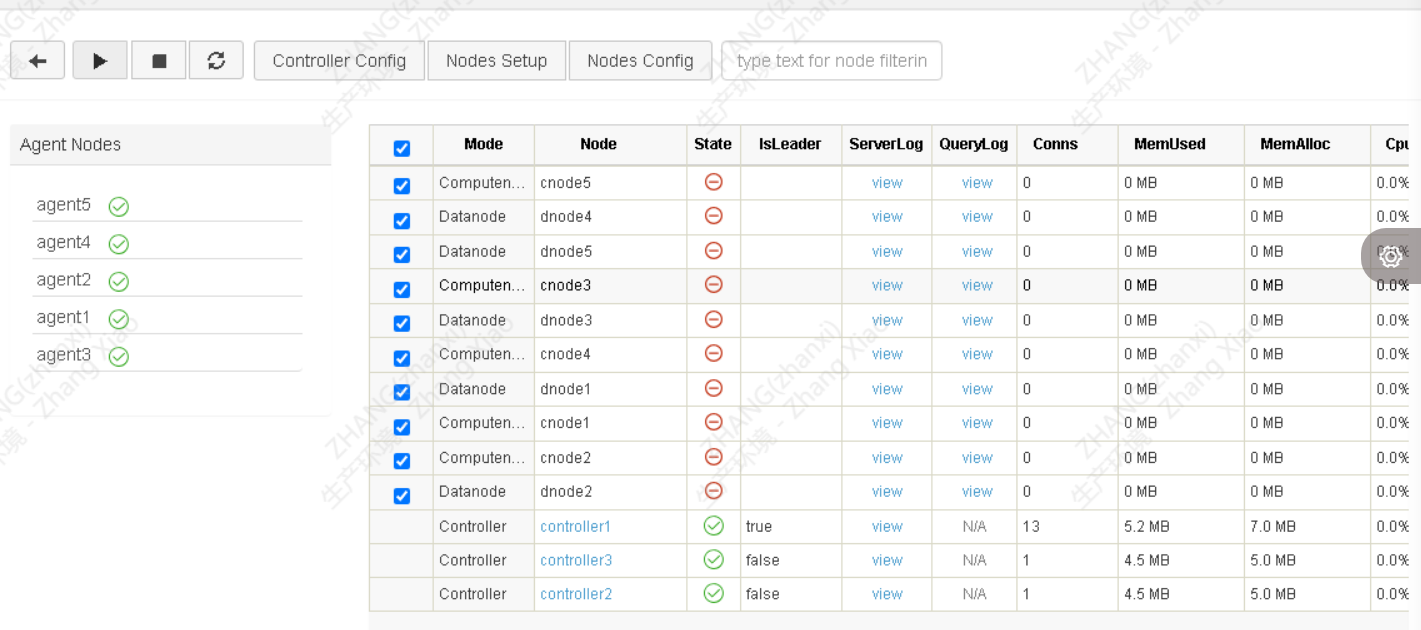
全选上所有的cn和dn,点击启动按钮,等几秒刷新,全部启动成功
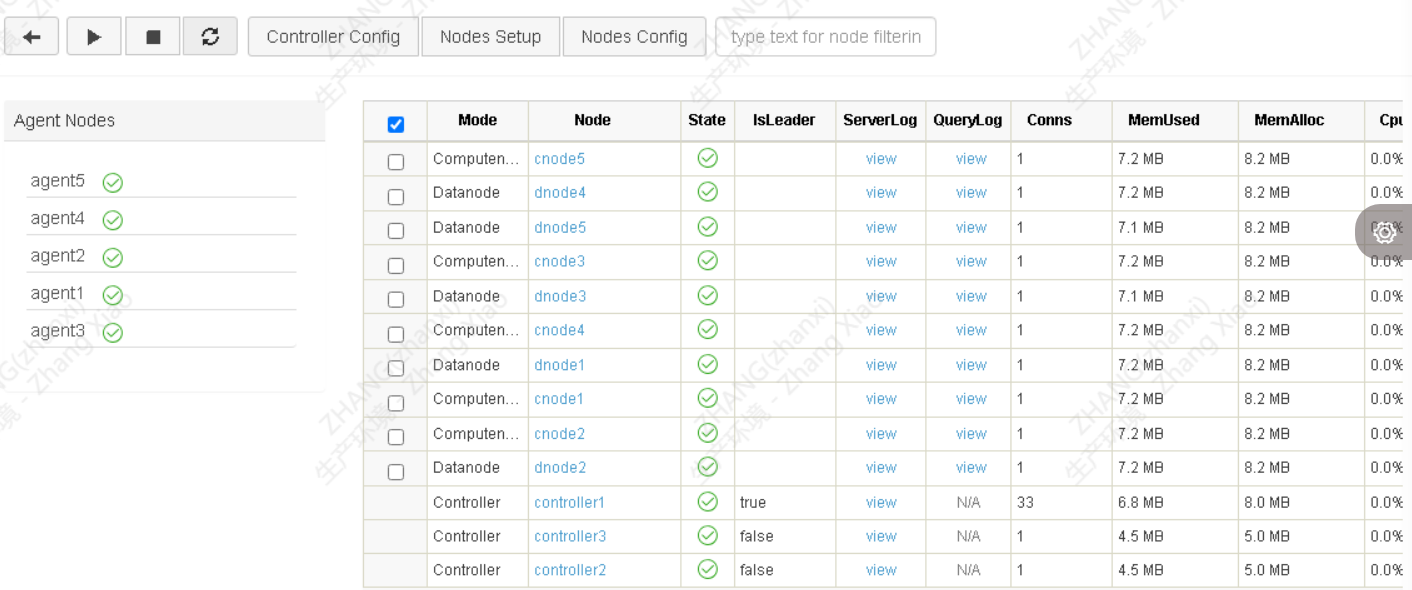
整个过程全部都是我独立参考官方文档完成,还算顺利。当然也有几个坑,跟大家说一下:
1.官网默认端口是8800开头,实际配置文件是8900开头,以哪个为准取决于自己,我选择的8900开头
2.在agent.cfg里的sites默认不在配置文件里,需要手动添加这个配置项
3.如果哪个环节启动出了问题,去排查DolphinDB/server/clusterDemo/log目录下的对应文件,比如agent就是agent.log
