





1 ES的重要概念
1.1 ES的特点
1.2 ES和MySQL的区别
1.3 ES数据存储和搜索原理
1.4 倒排索引
1.5 ES核心概念
1.6 ik分词器
1.7 数据类型
1.7.1 简单数据类型
1.7.2 复杂数据类型
2 ESClient对象创建
3 操作索引
3.1 新建索引
3.2 删除索引
3.3 查询索引
3.4 判断索引
3.5 索引操作总结
4 操作文档
4.1 添加/修改文档
4.2 查询文档
4.3 删除文档
4.4 文档操作总结
5 数据批量操作
5.1 Bulk批量操作
5.2 批量导入
6 ES查询
6.1 matchAllQuery-- 查询所有
6.2 词条查询
6.2.1 termQuery
6.2.2 matchQuery
6.3 模糊查询
6.4 范围查询
6.5 queryString查询 -- 多字段查询
6.6 布尔查询-- 多条件查询
6.7 聚合查询
6.8 高亮查询
6.9 重建索引及别名
7 ES集群
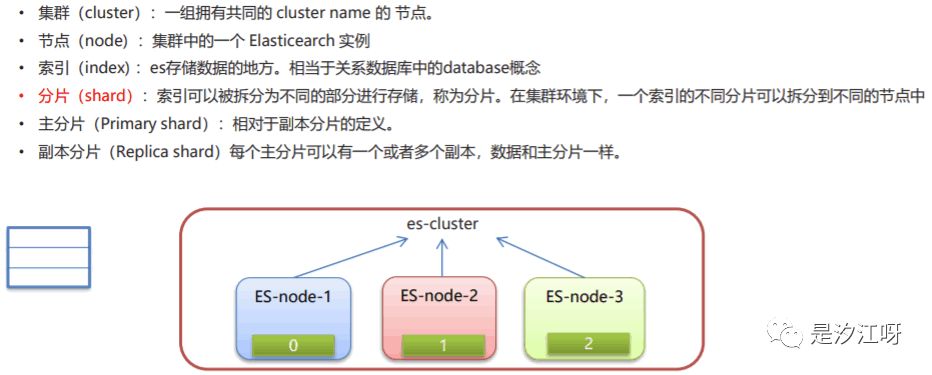
7.1 集群的概念
7.2 集群的特点及分布式架构
7.3 Code访问集群
7.4 分片配置
7.5 路由原理
7.6 脑裂
7.6.1 脑裂出现的原因
7.6.2 脑裂的解决方案
1 ES的重要概念
1.1 ES的特点
1.ElasticSearch是一个基于Lucene的搜索服务器,是一个分布式、高扩展、高实时的搜索与数据分析引擎,基于RESTful web接口2.Elasticsearch是用Java语言开发的,并作为Apache许可条款下的开放源码发布,是一种流行的企业级搜索引擎3.应用场景3.1 搜索:海量数据的查询3.2 日志数据分析3.3 实时数据分析
1.2 ES和MySQL的区别
• MySQL有事务性,而ElasticSearch没有事务性,所以删除的数据是无法恢复的。• ElasticSearch没有物理外键这个特性,,如果数据强一致性要求比较高,还是建议慎用• ElasticSearch和MySql分工不同,MySQL负责存储数据,ElasticSearch负责搜索数据。
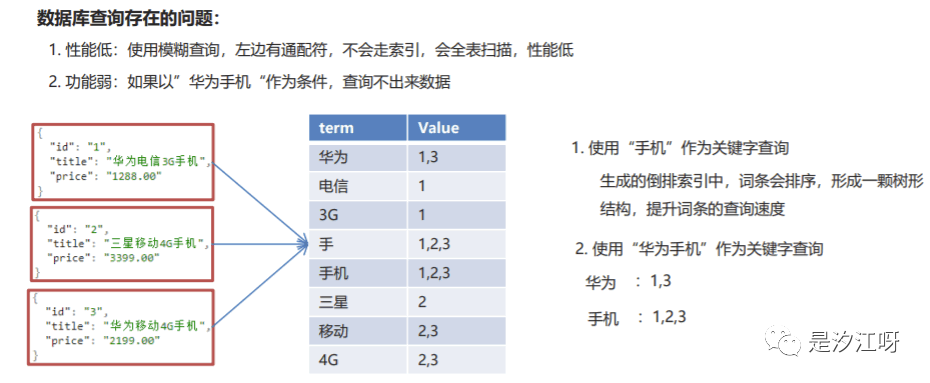
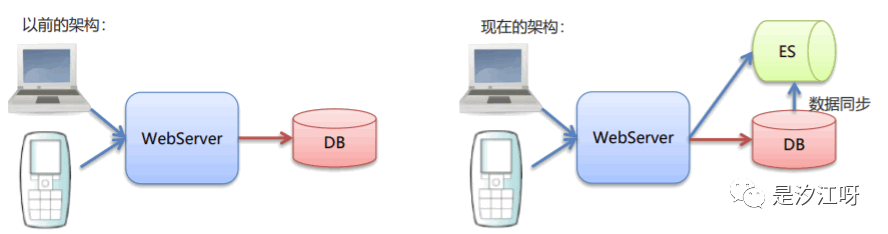
1.3 ES数据存储和搜索原理
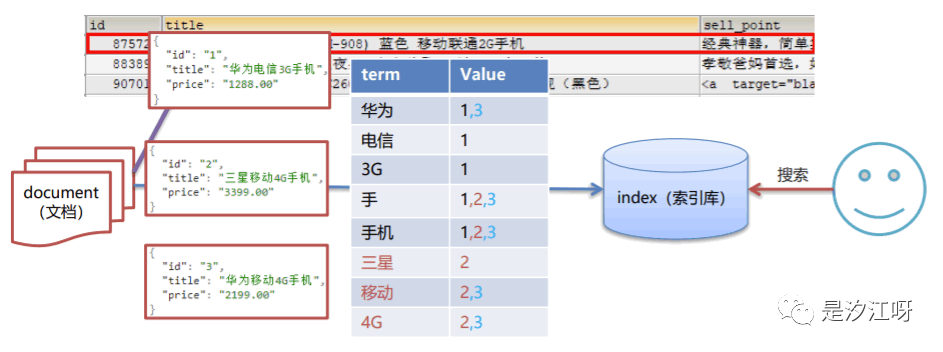
1.4 倒排索引
1.倒排索引就是将各个文档中的内容进行分词,形成词条,然后记录词条和数据的唯一标识(id)的对应关系,形成的产物2.通俗来讲,正向索引就是通过key找value,而倒排索引是通过value找key
1.5 ES核心概念
• 索引(index)ElasticSearch存储数据的地方,可以理解成关系型数据库中的数据库概念。• 映射(mapping)mapping定义了每个字段的类型、字段所使用的分词器等。相当于关系型数据库中的表结构。• 文档(document)Elasticsearch中的最小数据单元,常以json格式显示。一个document相当于关系型数据库中的一行数据。• 倒排索引(反向索引)• 倒排索引就是将文档中的内容进行分词形成词条,然后记录词条和数据的唯一标识(id)的对应关系形成的产物• 通俗来讲,正向索引就是通过key找value,而倒排索引是通过value找key• 类型(type)一种type就像一类表。如用户表、角色表等。在Elasticsearch7.X默认type为_doc- ES 5.x中一个index可以有多种type。- ES 6.x中一个index只能有一种type。- ES 7.x以后,将逐步移除type这个概念,现在的操作已经不再使用,默认_doc
1.6 ik分词器
• 分词器(Analyzer):将一段文本,按照一定逻辑,分析成多个词语的一种工具,ElasticSearch 内置分词器对中文很不友好,处理方式为:一个字一个词• IKAnalyzer是一个开源的,基于java语言开发的轻量级的中文分词工具包,是一个基于Maven构建的项目,具有60万字/秒的高速处理能力,支持用户词典扩展定义
IK提供两种分词模式:智能模式和细粒度模式• 智能:对应es的IK插件的ik_smart• 细粒度:对应es的IK插件的ik_max_word
1.7 数据类型
1.7.1 简单数据类型

1.7.2 复杂数据类型

2 ESClient对象创建
• 在SpringBoot中定义类,将连接信息通过yaml等配置文件的形式自动进行装配@Component@ConfigurationProperties(prefix = "elasticsearch")@Datapublic class elasticsearchGet {private String host;private Integer port;@Beanpublic RestHighLevelClient client(){return new RestHighLevelClient(RestClient.builder(new HttpHost(host,port,"http")));}}• application.yaml# eselasticsearch:host: 192.168.153.131port: 9200
3 操作索引
3.1 新建索引
// 添加索引CreateIndexRequest createRequest = new CreateIndexRequest("river3");// 添加映射String source = "{\n" +" \"properties\" : {\n" +" \"age\" : {\n" +" \"type\" : \"integer\"\n" +" },\n" +" \"name\" : {\n" +" \"type\" : \"keyword\"\n" +" }\n" +" }\n" +" }";createRequest.mapping(source, XContentType.JSON);CreateIndexResponse response = client.indices().create(createRequest, RequestOptions.DEFAULT);// 判断索引是否创建成功System.out.println(response.isAcknowledged());
3.2 删除索引
IndicesClient indices = client.indices();DeleteIndexRequest deleteIndexRequest = new DeleteIndexRequest("river");AcknowledgedResponse response = indices.delete(deleteIndexRequest, RequestOptions.DEFAULT);boolean acknowledged = response.isAcknowledged();System.out.println(acknowledged);
3.3 查询索引
IndicesClient indices = client.indices();GetIndexRequest getIndexRequest = new GetIndexRequest("person");GetIndexResponse response = indices.get(getIndexRequest, RequestOptions.DEFAULT);Map<String, MappingMetaData> map = response.getMappings();for (String str : map.keySet()) {System.out.println(str);System.out.println(map.get(str).sourceAsMap());}
3.4 判断索引
IndicesClient indices = client.indices();GetIndexRequest getIndexRequest = new GetIndexRequest("river3");boolean exists = indices.exists(getIndexRequest, RequestOptions.DEFAULT);System.out.println(exists);
3.5 索引操作总结
• 索引的操作核心方法在于indices,通过该方法获取一个索引客户端对象,然后通过该对象来进行一系列相关操作• 创建 -- create() -- createRequest• 查询 -- get() -- GetIndexRequest• 删除 -- delete() -- DeleteIndexRequest• 判断 -- exists() -- GetIndexRequest
4 操作文档
4.1 添加/修改文档
// id存在则修改,id不存在则添加String json = JSON.toJSONString(new User(4525,"二1黑1"));IndexRequest indexRequest = new IndexRequest("river3").id("3").source(json, XContentType.JSON);IndexResponse response = client.index(indexRequest, RequestOptions.DEFAULT);System.out.println(response.getPrimaryTerm());
4.2 查询文档
GetRequest request = new GetRequest("river3","1");GetResponse response = client.get(request, RequestOptions.DEFAULT);System.out.println(response.getSourceAsString();
4.3 删除文档
DeleteRequest deleteRequest = new DeleteRequest("river3","3");DeleteResponse response = client.delete(deleteRequest, RequestOptions.DEFAULT);System.out.println(response.toString());
4.4 文档操作总结
• 文档的操作直接通过client客户端对象来进行• 添加/修改使用index方法 -- IndexRequest• 查询使用get方法 -- GetRequest• 删除使用delete方法 -- DeleteRequest
5 数据批量操作
5.1 Bulk批量操作
• Bulk批量操作是将文档的增删改查一些列操作,通过一次请求全都做完,从而减少网络的传输次数• 核心在于client中的bulk()方法,通过向BulkRequest中add操作对象实现批量操作BulkRequest bulkRequest = new BulkRequest();/** 1.删除6号记录* 2.添加7号记录* 3.修改2号记录 名称为2号* */// 1.删除6号记录DeleteRequest deleteRequest = new DeleteRequest("person", "6");bulkRequest.add(deleteRequest);// 2.添加7号记录Map<String, String> map = new HashMap<>();map.put("age", "123");map.put("name", "世界");IndexRequest indexRequest = new IndexRequest("person").id("7").source(map);bulkRequest.add(indexRequest);// 3.修改2号记录 名称为2号Map<String, String> map1 = new HashMap<>();map1.put("name", "2号");UpdateRequest updateRequest = new UpdateRequest("person", "2").doc(JSON.toJSONString(map1), XContentType.JSON);bulkRequest.add(updateRequest);BulkResponse bulk = client.bulk(bulkRequest, RequestOptions.DEFAULT);System.out.println(bulk.status());
5.2 批量导入
• 思路:从mysql中查询出数据循环遍历对象将数据添加到批量操作bulk中// 1.从mysql中查询所有数据List<Goods> all = goodsDao.findAll();// 2.bulk导入BulkRequest bulkRequest = new BulkRequest();for (Goods goods : all) {// 将获取到的spec数据转换为一个map集合Map map = JSON.parseObject(goods.getSpecStr(), Map.class);goods.setSpec(map);// 将每个goods对象中的数据添加到批量导入脚本中bulkRequest.add(new IndexRequest("goods").id(goods.getId() + "").source(JSON.toJSONString(goods), XContentType.JSON));}// 进行批量导入BulkResponse responses = client.bulk(bulkRequest, RequestOptions.DEFAULT);// 查看导入状态信息System.out.println(responses.status());
6 ES查询
6.1 matchAllQuery-- 查询所有
matchAll查询:查询所有文档// 指定查询哪个索引SearchRequest searchRequest = new SearchRequest("goods");// 指定查询条件searchRequest.source(new SearchSourceBuilder().query(QueryBuilders.matchAllQuery()).from(0).size(20));// 进行查询获得查询响应信息SearchResponse response = client.search(searchRequest, RequestOptions.DEFAULT);// 获取查询的总记录数System.out.println("总记录数:" + response.getHits().getTotalHits().value);// 将查询出的数据封装到一个list集合中去List<Goods> goods = new ArrayList<>();SearchHit[] hits = response.getHits().getHits();for (SearchHit hit : hits) {Goods good = JSON.parseObject(hit.getSourceAsString(), Goods.class);goods.add(good);}System.out.println(goods);
6.2 词条查询
6.2.1 termQuery
// 指定查询哪个索引SearchRequest searchRequest = new SearchRequest("goods");// 指定查询条件searchRequest.source(new SearchSourceBuilder().query(QueryBuilders.termQuery("title","诺基亚")).from(0).size(20));// 进行查询获得查询响应信息SearchResponse response = client.search(searchRequest, RequestOptions.DEFAULT);// 获取查询的总记录数System.out.println("总记录数:" + response.getHits().getTotalHits().value);// 将查询出的数据封装到一个list集合中去List<Goods> goods = new ArrayList<>();SearchHit[] hits = response.getHits().getHits();for (SearchHit hit : hits) {Goods good = JSON.parseObject(hit.getSourceAsString(), Goods.class);goods.add(good);}System.out.println(goods);
6.2.2 matchQuery
// 指定查询哪个索引SearchRequest searchRequest = new SearchRequest("goods");// 指定查询条件searchRequest.source(new SearchSourceBuilder().query(QueryBuilders.matchQuery("title","华为手机")).from(0).size(20));// 进行查询获得查询响应信息SearchResponse response = client.search(searchRequest, RequestOptions.DEFAULT);// 获取查询的总记录数System.out.println("总记录数:" + response.getHits().getTotalHits().value);// 将查询出的数据封装到一个list集合中去List<Goods> goods = new ArrayList<>();SearchHit[] hits = response.getHits().getHits();for (SearchHit hit : hits) {Goods good = JSON.parseObject(hit.getSourceAsString(), Goods.class);goods.add(good);}System.out.println(goods);
6.3 模糊查询
• WildCard -- 通配符方式• Regexp -- 正则式方式• Prefix -- 前缀匹配方式// 指定查询哪个索引SearchRequest searchRequest = new SearchRequest("goods");// 指定查询条件// 1.通配符//searchRequest.source(new SearchSourceBuilder().query(QueryBuilders.wildcardQuery("title","华*")).from(0).size(20));// 2.正则式//searchRequest.source(new SearchSourceBuilder().query(QueryBuilders.regexpQuery("title","\\w+.*")).from(0).size(20));// 3.前缀searchRequest.source(new SearchSourceBuilder().query(QueryBuilders.prefixQuery("title","new8")).from(0).size(20));// 进行查询获得查询响应信息SearchResponse response = client.search(searchRequest, RequestOptions.DEFAULT);// 获取查询的总记录数System.out.println("总记录数:" + response.getHits().getTotalHits().value);// 将查询出的数据封装到一个list集合中去List<Goods> goods = new ArrayList<>();SearchHit[] hits = response.getHits().getHits();for (SearchHit hit : hits) {Goods good = JSON.parseObject(hit.getSourceAsString(), Goods.class);goods.add(good);}System.out.println(goods);
6.4 范围查询
// 指定查询哪个索引SearchRequest searchRequest = new SearchRequest("goods");// 指定查询条件 -- 根据范围进行查询searchRequest.source(new SearchSourceBuilder().query(QueryBuilders.rangeQuery("price").gte(2000).lte(3000))// 根据价格进行排序 -- 降序排列.sort("price", SortOrder.DESC).from(0).size(20));// 进行查询获得查询响应信息SearchResponse response = client.search(searchRequest, RequestOptions.DEFAULT);// 获取查询的总记录数System.out.println("总记录数:" + response.getHits().getTotalHits().value);
6.5 queryString查询 -- 多字段查询
// 指定查询哪个索引SearchRequest searchRequest = new SearchRequest("goods");// 指定查询条件 -- 根据一个查询内容去多个字段中进行查找searchRequest.source(new SearchSourceBuilder().query(QueryBuilders.queryStringQuery("华为手机").field("title").field("brandName").field("categoryName")).from(0).size(20));// 进行查询获得查询响应信息SearchResponse response = client.search(searchRequest, RequestOptions.DEFAULT);// 获取查询的总记录数System.out.println("总记录数:" + response.getHits().getTotalHits().value);
6.6 布尔查询 -- 多条件查询
* must -- 必须包含,计算得分* must_not -- 必须不包含* should -- 可以包含也可以不包含* filter -- 必须包含,不计算得分
// 指定查询哪个索引SearchRequest searchRequest = new SearchRequest("goods");// 指定查询条件 -- 根据多个查询内容进行查找searchRequest.source(new SearchSourceBuilder().query(QueryBuilders.boolQuery()// 第一个查询条件 -- 不分词进行查询.must(QueryBuilders.matchQuery("title","华为手机"))// 第二个查询条件 -- 根据价格进行查询.filter(QueryBuilders.rangeQuery("price").gte(2000).lte(3000)))// 设置当前查询页数及每页查询条数.from(0).size(20));// 进行查询获得查询响应信息SearchResponse response = client.search(searchRequest, RequestOptions.DEFAULT);// 获取查询的总记录数System.out.println("总记录数:" + response.getHits().getTotalHits().value);
6.7 聚合查询
* 指标聚合 -- 相当于mysql中聚合函数* 桶聚合 -- 相当于mysql中分组
// 指定查询哪个索引SearchRequest searchRequest = new SearchRequest("goods");// 指定查询条件searchRequest.source(new SearchSourceBuilder().query(QueryBuilders.termQuery("title","手机"))// 聚合查询条件 -- 桶聚合.aggregation(AggregationBuilders.terms("goods_brand").field("brandName"))// 聚合查询条件 -- 指标聚合.aggregation(AggregationBuilders.max("max_price").field("price")).from(0).size(20));// 进行查询获得查询响应信息SearchResponse response = client.search(searchRequest, RequestOptions.DEFAULT);// 获取查询的总记录数System.out.println("总记录数:" + response.getHits().getTotalHits().value);// 获取聚合结果Map<String, Aggregation> map = response.getAggregations().asMap();System.out.println(map);// 强转为Terms类型获取桶聚合结果Terms terms = (Terms) map.get("goods_brand");List<? extends Terms.Bucket> buckets = terms.getBuckets();// 获取价格最大值Max maxPrice = response.getAggregations().get("max_price");System.out.println("最高价为:"+maxPrice.value());// 遍历集合获取所有的分类数据List brands = new ArrayList();for (Terms.Bucket bucket : buckets) {brands.add(bucket.getKey());}System.out.println(brands);
6.8 高亮查询
高亮三要素:• 高亮字段• 前缀• 后缀
// 指定查询哪个索引SearchRequest searchRequest = new SearchRequest("goods");// 指定查询条件searchRequest.source(new SearchSourceBuilder().query(QueryBuilders.termQuery("title","手机"))// 指定高亮区域 -- 所有的手机都会被包裹在一个font标签当中.highlighter(new HighlightBuilder().field("title").preTags("<font color=\"red\">").postTags("</font>")).from(0).size(20));// 进行查询获得查询响应信息SearchResponse response = client.search(searchRequest, RequestOptions.DEFAULT);// 获取查询的总记录数System.out.println("总记录数:" + response.getHits().getTotalHits().value);// 获取聚合结果SearchHits hits = response.getHits();List<Goods> goodsList = new ArrayList<>();for (SearchHit hit : hits) {// 获取所有设置高亮的字段Map<String, HighlightField> highlightFields = hit.getHighlightFields();// 获取其中名称为title的高亮字段HighlightField highlightField = highlightFields.get("title");// 获取文本对象Text[] fragments = highlightField.fragments();// 将设置高亮之后的title重新进行替换Goods goods = JSON.parseObject(hit.getSourceAsString(), Goods.class);goods.setTitle(fragments[0].toString());goodsList.add(goods);}System.out.println(goodsList);
6.9 重建索引及别名
* 重建索引 -- ES中无法对字段类型和结构进行修改,只能添加字段无法改变字段,当需要更改时需要重新创建一个索引将原索引中数据进行迁移* 索引别名 -- 为了避免JAVA代码因为重建索引的影响,需要对新建索引创建一个别名* 1.删除原索引* 2.给新建索引设置一个别名,别名名称和原索引保持一致,从而确保JAVA代码不修改即可完成业务功能变更
7 ES集群
7.1 集群的概念
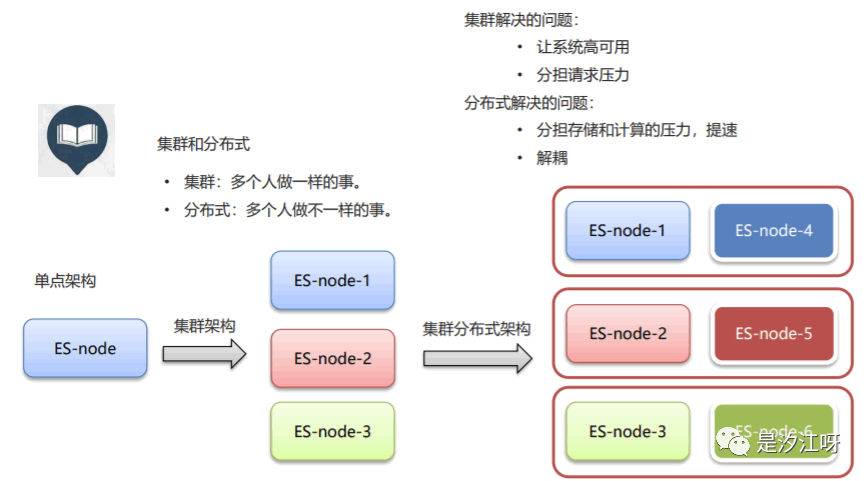
7.2 集群的特点及分布式架构
• ElasticSearch 天然支持分布式• ElasticSearch 的设计隐藏了分布式本身的复杂性
7.3 Code访问集群
• 配置多个HttpHost对象@Beanpublic RestHighLevelClient client(){return new RestHighLevelClient(RestClient.builder(new HttpHost(host1,port1,"http"),new HttpHost(host2,port2,"http"),new HttpHost(host3,port3,"http"),new HttpHost(host4,port4,"http")));}
7.4 分片配置

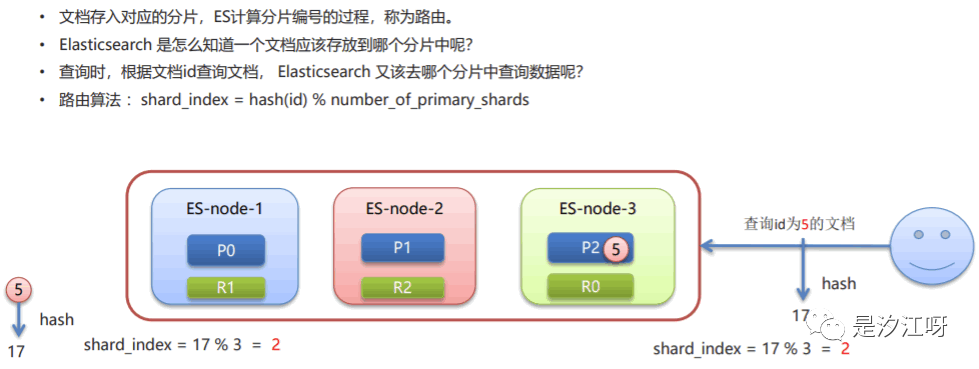
7.5 路由原理
7.6 脑裂
7.6.1 脑裂出现的原因
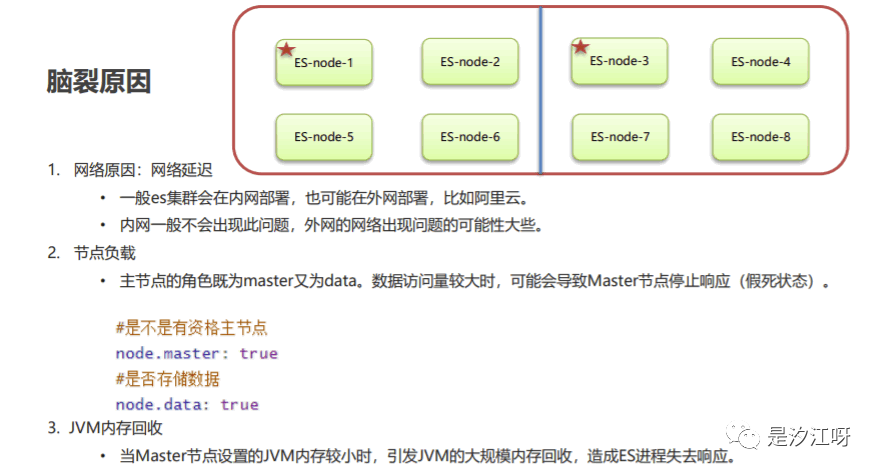
7.6.2 脑裂的解决方案

文章转载自是汐江呀,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
