




书接上文,上面两篇文章介绍了 PG 单机安装及数据库的基础操作和体系结构,菜鸟都可以看懂的 PostgreSQL 单机安装与基础知识学习手册(下),这一篇我们来看后续统计信息和执行计划相关的知识。
1、震惊,PG 脚本安装仅需两分钟
在进行正文之前呢,这里也想在演示一下 PostgreSQL 16.2 脚本化的安装过程,因为这几天看到了好几个“震惊”,“震惊,ACE装国产数据库花了两周”、“震惊!ACE装国产数据库花了2周,吓得我赶紧试了一下自家产品PolarDB”、“震惊!数据库小白装国产数据库只需10分钟!”等等,还有一些其他的“震惊”这里就不提了,所以我也想着震惊一下,看看安装 PostgreSQL 需要几分钟。首先我们准备好 Linux7 iso 镜像和安装包 postgresql-16.2.tar.bz2 以及星哥的一键安装脚本 x_onekey.sh。
注:星哥的一键安装Oracle11g/19C/21C_单机/RAC集群/standalone: https://www.modb.pro/db/156560
链接:https://pan.baidu.com/s/1oeQSCJq_gJaweqgSFAb9RA?pwd=wsr9
提取码:wsr9
我们需要将 tar.bz2 类型的软件包、iso 镜像文件及一键安装脚本 x_onekey.sh 上传到 /soft 下,然后将镜像文件重命名为 yum.iso 即可。
[root@jiekexu3 ~]# mkdir -p /soft
[root@jiekexu3 soft]# mv CentOS-7-x86_64-DVD-1810.iso yum.iso
[root@jiekexu3 ~]# cd /soft
[root@jiekexu3 soft]# ll
total 24232
-rw-r--r-- 1 root root 24711703 Apr 11 00:28 postgresql-16.2.tar.bz2
-rw-r--r-- 1 root root 95088 Apr 11 00:01 x_onekey.sh
-rw-r--r-- 1 root root 4588568576 Apr 11 00:43 yum.iso
[root@jiekexu3 soft]# chmod a+x x_onekey.sh
[root@jiekexu3 soft]# date
Thu Apr 11 00:52:30 CST 2024
sh x_onekey.sh -dt=pg \
-op=install \
-ht=single `#type: single/rac/ha` \
-v=16.2 `# version: 9.6.24/10.23/15.5` \
-i=192.168.75.13 `#Public ip` \
-n=jiekexu3 `# hostname ` \
-pg_debug=yes `# Compiles all programs and libraries with debugging symbols ` \
-cassert=no `# Enables assertion checks in the server, which test for many "cannot happen" conditions. ` \
-tap_tests=no `# Enable tests using the Perl TAP tools ` \
-dtrace=no `# Compiles PostgreSQL with support for the dynamic tracing tool DTrace ` \
-yum=/soft/yum.iso `# yum location: /dev/cdrom or /soft/yum.iso`
pls,confirm with the params(yes/no):yes <--- 输入 yes 确认
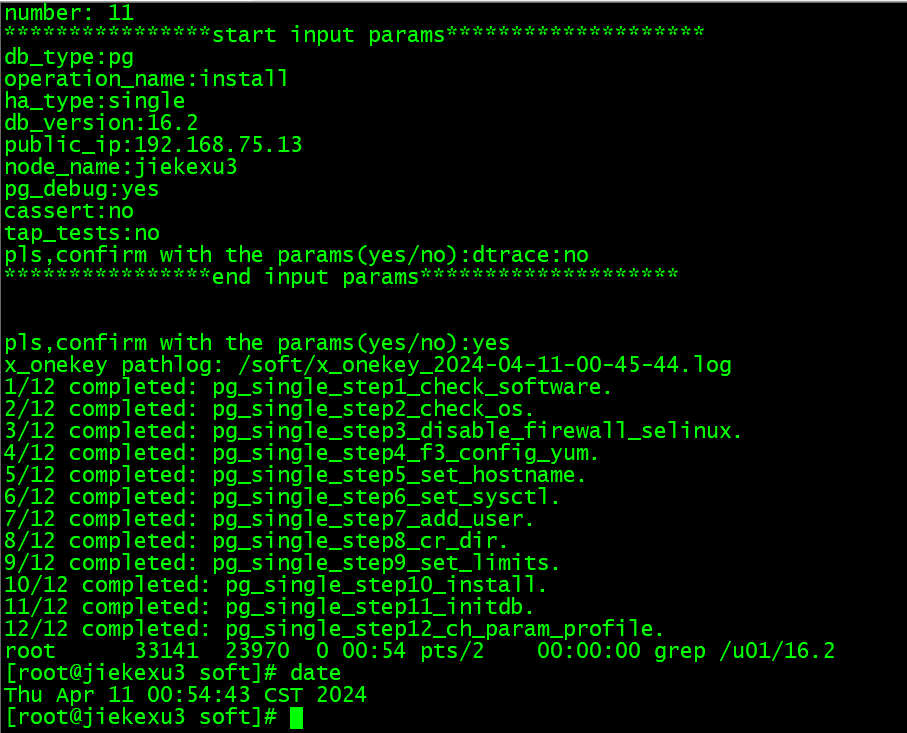
震惊,PG 不到 2 分钟就可以完成安装。
[root@jiekexu3 soft]# su – postgres
[postgres@jiekexu3 ~]$ source pg16.2_profile
[postgres@jiekexu3 ~]$ pg_ctl start -l logfile
waiting for server to start.... done
server started
[postgres@jiekexu3 ~]$ pg_ctl status
pg_ctl: server is running (PID: 33211)
/u01/app/pg/16.2/pgsql/bin/postgres
[postgres@jiekexu3 ~]$ psql
psql (16.2)
Type "help" for help.
postgres=# select version();
version
---------------------------------------------------------------------------------------------------------
PostgreSQL 16.2 on x86_64-pc-linux-gnu, compiled by gcc (GCC) 4.8.5 20150623 (Red Hat 4.8.5-36), 64-bit
(1 row)
postgres=#
使用脚本安装完成后,这里有两个需要注意的点,一个就是 PG 默认安装到了 /u01/app/pg/16.2/pgsql,数据默认也存到了 /u01/app/pg/16.2/data 下,如果你没有挂载 /u01 单独的文件系统,那么则默认安装到了根目录,如果数据增长很快,很容易撑满根目录。另外一点则是前面安装时上传了 iso 镜像文件用来配置 yum 源,这是必选的操作,如果你之前已经配好了网络 yum 源,则会给你备份到 /etc/yum.repos.d/bak 目录下,原来的 yum 源就不可用了,这点需要注意下。
2、统计信息与执行计划
统计信息
统计信息都保存在PostgreSQL的系统表中,这些系统表都以pg_stat或pg_statio开头。数据库级的统计信息可以通过pg_stat_database这个系统视图来查看。
postgres=# \d pg_stat_database
View "pg_catalog.pg_stat_database"
Column | Type | Collation | Nullable | Default
--------------------------+--------------------------+-----------+----------+---------
datid | oid | | |
datname | name | | |
numbackends | integer | | |
xact_commit | bigint | | |
xact_rollback | bigint | | |
blks_read | bigint | | |
blks_hit | bigint | | |
tup_returned | bigint | | |
tup_fetched | bigint | | |
tup_inserted | bigint | | |
tup_updated | bigint | | |
tup_deleted | bigint | | |
conflicts | bigint | | |
temp_files | bigint | | |
temp_bytes | bigint | | |
deadlocks | bigint | | |
checksum_failures | bigint | | |
checksum_last_failure | timestamp with time zone | | |
blk_read_time | double precision | | |
blk_write_time | double precision | | |
session_time | double precision | | |
active_time | double precision | | |
idle_in_transaction_time | double precision | | |
sessions | bigint | | |
sessions_abandoned | bigint | | |
sessions_fatal | bigint | | |
sessions_killed | bigint | | |
stats_reset | timestamp with time zone | | |
postgres=#
参数说明如下:
❑ numbackends:当前有多少个并发连接,理论上控制在cpu核数的1.5倍可以获得更好的性能;
❑ blks_read, blks_hit:读取磁盘块的次数与这些块的缓存命中数;
❑ xact_commit, xact_rollback:提交和回滚的事务数;
❑ deadlocks:从上次执行pg_stat_reset以来的死锁数量。
在 pg_stat_database 系统视图的字段中,除 numbackends 字段和 stats_reset 字段外,其他字段的值是自从 stats_reset 字段记录的时间点执行 pg_stat_reset() 命令以来的统计信息。建议使用者在进行优化和参数调整之后执行 pg_stat_reset() 命令,方便对比优化和调整前后的各项指标。
表级的统计信息最常用的是pg_stat_user(all)_tables视图;
postgres=# \d pg_stat_all_tables
View "pg_catalog.pg_stat_all_tables"
Column | Type | Collation | Nullable | Default
---------------------+--------------------------+-----------+----------+---------
relid | oid | | |
schemaname | name | | |
relname | name | | |
seq_scan | bigint | | |
seq_tup_read | bigint | | |
idx_scan | bigint | | |
idx_tup_fetch | bigint | | |
n_tup_ins | bigint | | |
n_tup_upd | bigint | | |
n_tup_del | bigint | | |
n_tup_hot_upd | bigint | | |
n_live_tup | bigint | | |
n_dead_tup | bigint | | |
n_mod_since_analyze | bigint | | |
n_ins_since_vacuum | bigint | | |
last_vacuum | timestamp with time zone | | |
last_autovacuum | timestamp with time zone | | |
last_analyze | timestamp with time zone | | |
last_autoanalyze | timestamp with time zone | | |
vacuum_count | bigint | | |
autovacuum_count | bigint | | |
analyze_count | bigint | | |
autoanalyze_count | bigint | | |
last_vacuum, last_analyze:最后一次在此表上手动执行vacuum和analyze的时间。
last_autovacuum, last_autoanalyze:最后一次在此表上被autovacuum守护程序执行autovacuum和analyze的时间。
idx_scan, idx_tup_fetch:在此表上进行索引扫描的次数以及以通过索引扫描获取的行数。
seq_scan, seq_tup_read:在此表上顺序扫描的次数以及通过顺序扫描读取的行数。
n_tup_ins, n_tup_upd, n_tup_del:插入、更新和删除的行数。
n_live_tup, n_dead_tup:live tuple与dead tuple的估计数。
执行计划
执行计划,也叫作查询计划,会显示将怎样扫描语句中用到的表。在 PostgreSQL 中使用 EXPLAIN 命令来查看执行计划。在 EXPLAIN 命令后面还可以跟上 ANALYZE 得到真实的查询计划。
explain select * from t;
explain analyze select * from t where id=3;
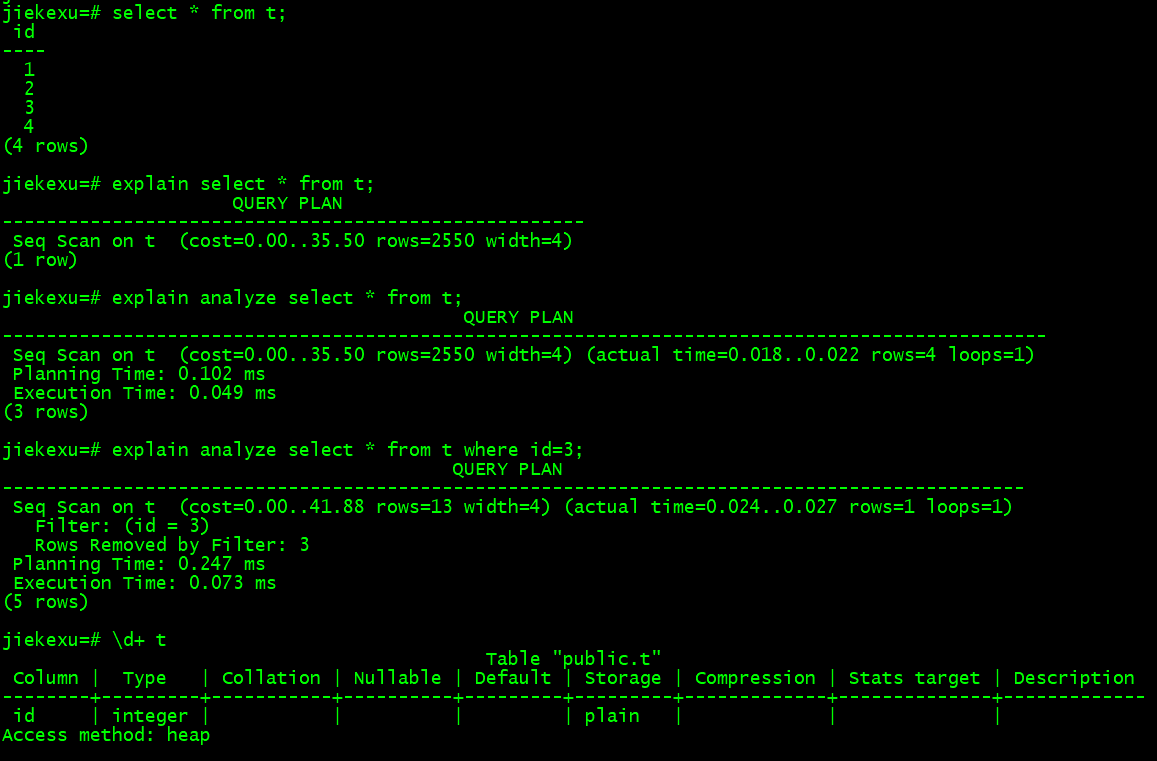
但是需要注意的是:使用 ANALYZE 选项时语句会被执行,所以在分析 INSERT、UPDATE、DELETE、CREATE TABLE AS 或者 EXECUTE 命令的查询计划时,应该使用一个事务来执行,得到真正的查询计划后对该事务进行回滚,就会避免因为使用 ANALYZE 选项而修改了数据。
执行计划阅读原则:从下往上看,从右往左看。
示例:
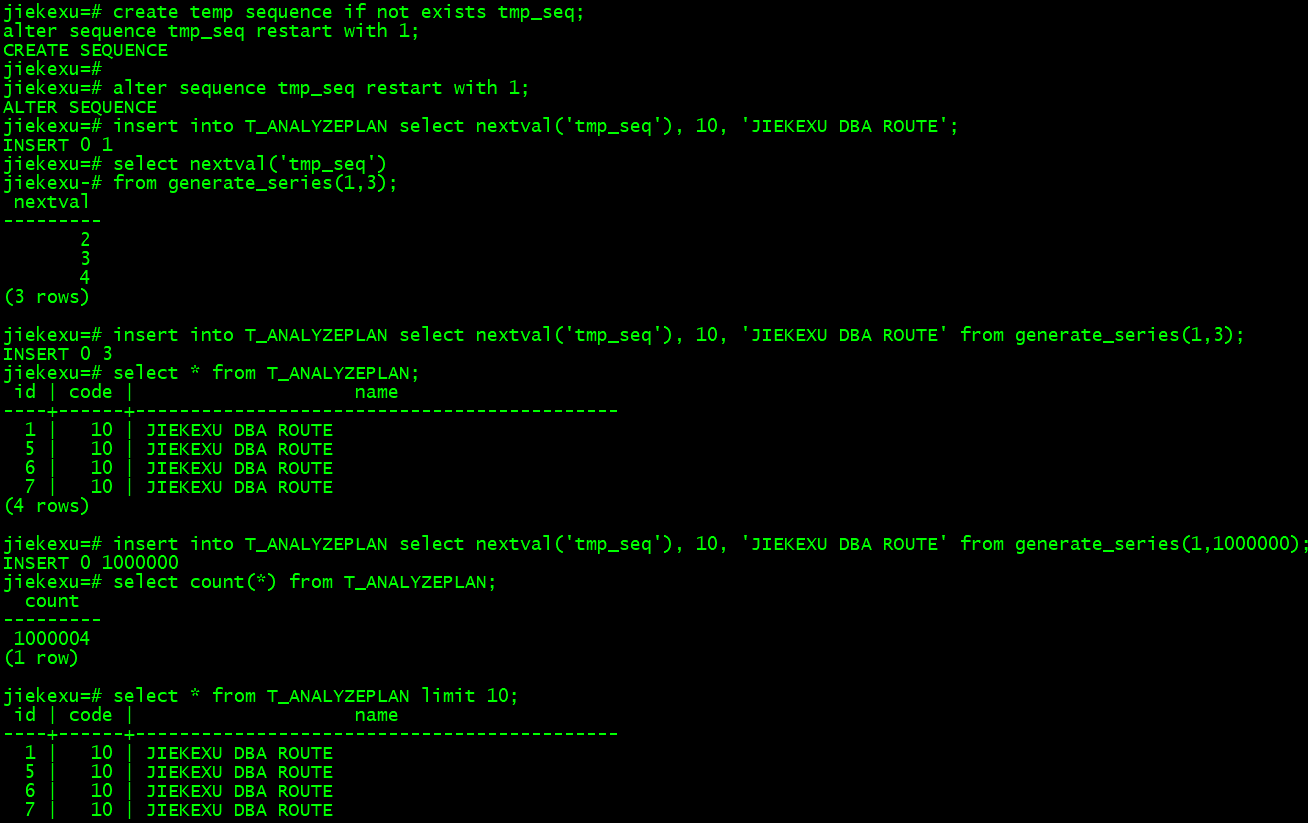
create table T_ANALYZEPLAN (id int, code int, name char(42));
insert into T_ANALYZEPLAN select nextval('tmp_seq'), 10, 'JIEKEXU DBA ROUTE' connect by level <=1000000;
--PostgreSQL 语法实现 rownum 和 connect by level 功能。
create temp sequence if not exists tmp_seq;
alter sequence tmp_seq restart with 1;
--select nextval('tmp_seq') as rownum, * from test limit 10;
insert into T_ANALYZEPLAN select nextval('tmp_seq'), 10, 'JIEKEXU DBA ROUTE' from generate_series(1,1000000);
update T_ANALYZEPLAN set code = 9 where mod(id,3) = 0;
update T_ANALYZEPLAN set code = 1 where mod(id,2) = 0 and id between 1 and 20000;
update T_ANALYZEPLAN set code = 2 where mod(id,2) = 0 and id between 30001 and 40000;
update T_ANALYZEPLAN set code = 3 where mod(id,100) = 0 and id between 300001 and 400000;
update T_ANALYZEPLAN set code = 4 where mod(id,100) = 0 and id between 400001 and 500000;
update T_ANALYZEPLAN set code = 5 where mod(id,100) = 0 and id between 600001 and 700000;
update T_ANALYZEPLAN set code = 6 where mod(id,1000) = 0 and id between 700001 and 800000;
update T_ANALYZEPLAN set code = 7 where mod(id,1000) = 0 and id between 800001 and 900000;
update T_ANALYZEPLAN set code = 8 where mod(id,1000) = 0 and id between 900001 and 1000000;
update T_ANALYZEPLAN set code = 11 where ID = 892000;
Select * from T_ANALYZEPLAN limit 10;
select code, count(*) from T_ANALYZEPLAN group by code order by code;
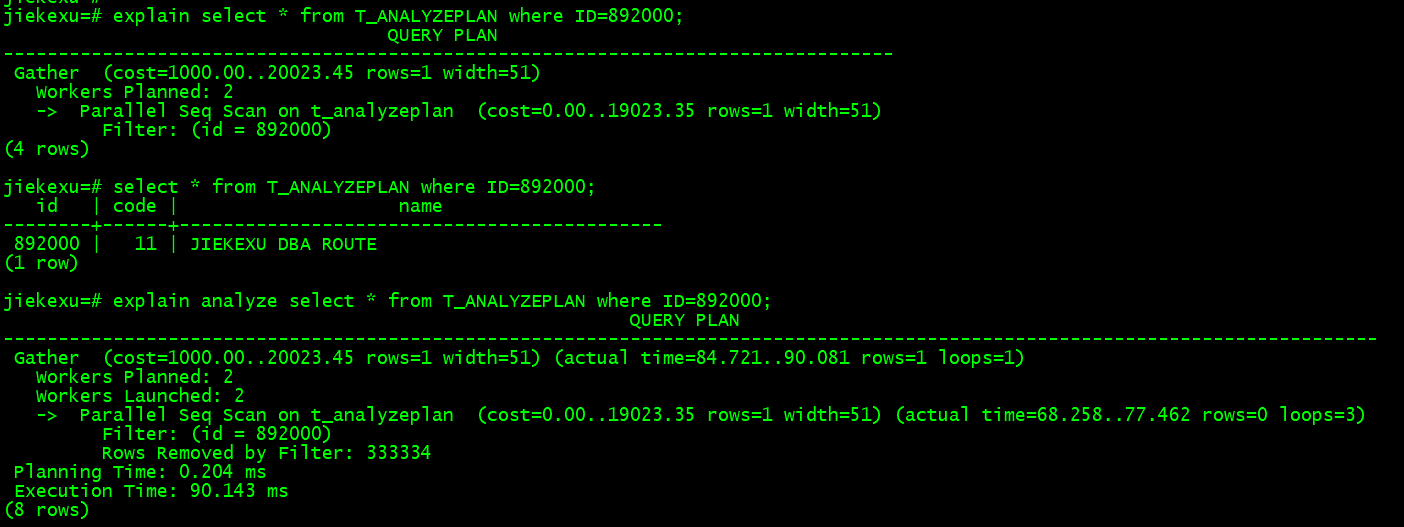
explain select * from T_ANALYZEPLAN where ID=892000;
select * from T_ANALYZEPLAN where ID=892000;
explain analyze select * from T_ANALYZEPLAN where ID=892000;
创建索引
create index idx_t_anal_id on t_analyzeplan(id);
analyze T_ANALYZEPLAN;
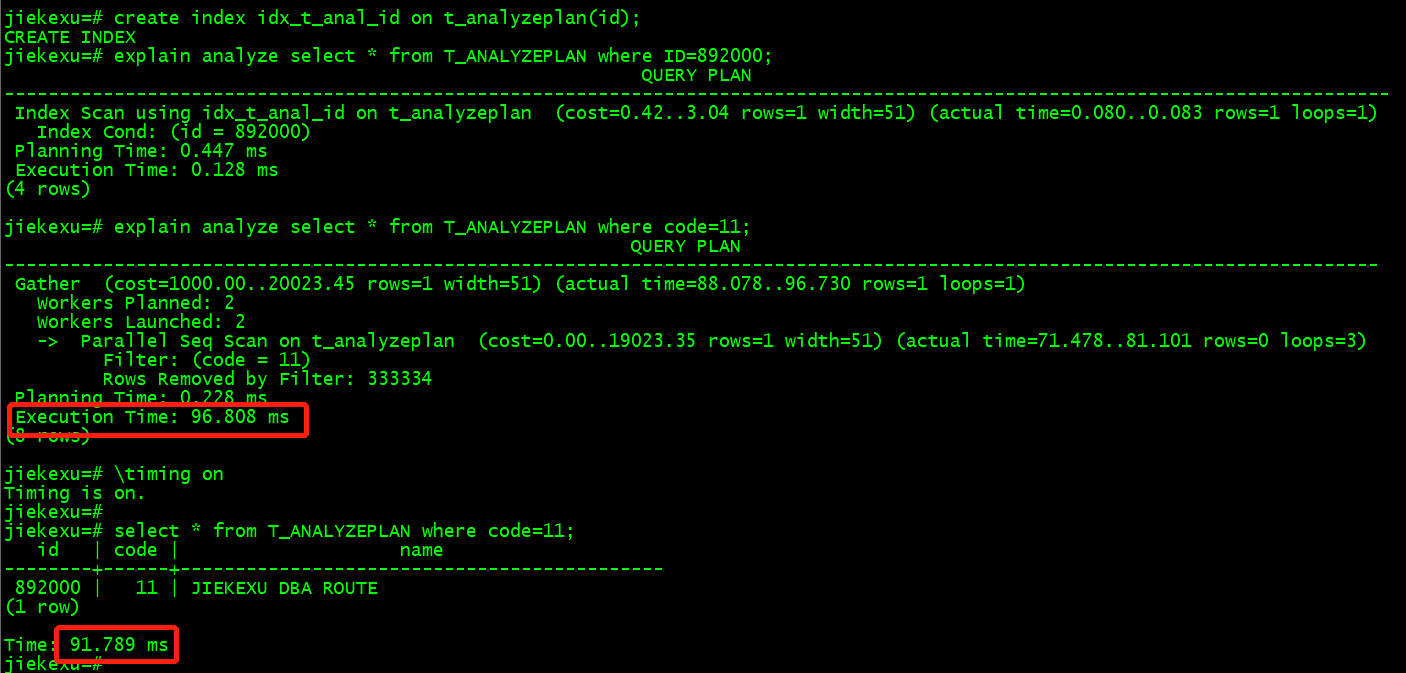
例如上面的例子,从下往上看最后一行的内容是 Execution time: 96.808 ms,是这条语句的实际执行时间是 96.808 ms;往上一行的内容是 Planning time: 0.228,是这条语句的查询计划时间0.228 ms;往上一行,一个箭头在上一行的右侧缩进处,表示t_analyzeplan表并行全表扫描Parallel Seq Scan,往上一行,并发工作进程数为 2,最上层的执行计划节点名称为 Gather。PostgreSQL 在很多场景下会启用并行执行计划,创建多个并行工作子进程,提升查询效率。在每行计划中,都有几项值,(cost=0.00…19023.35) 预估该算子开销有多么“昂贵”。“昂贵”按照磁盘读计算。这里有两个数值:第一个表示算子返回第一条结果集最快需要多少时间;第二个数值(通常更重要)表示整个算子需要多长时间。开销预估中的第二项(rows=1)表示 PostgreSQL 预计该算子会返回多少条记录。最后一项(width=51)表示结果集中一条记录的平均长度(字节数),由于使用了 ANALYZE 选项,后面还会有实际执行的时间统计。
除了ANALYZE选项,还可以使用COSTS、BUFFERS、TIMING、FORMAT这些选项输出比较详细的查询计划。例如:
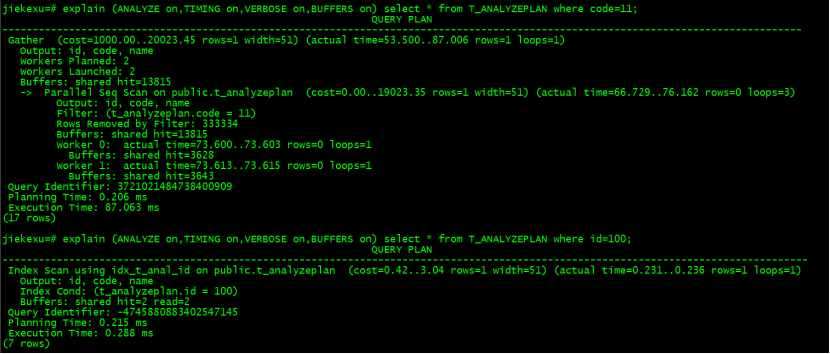
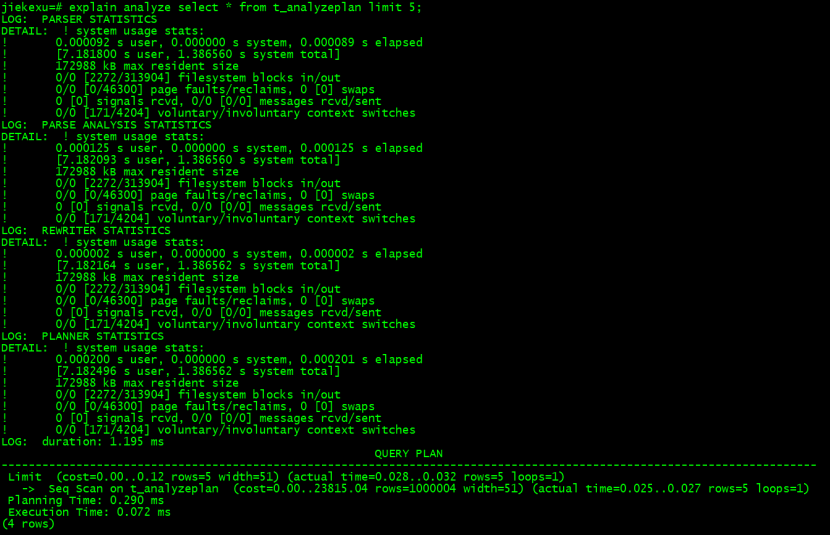
使用 EXPLAIN 的选项(ANALYZE、COSTS、BUFFERS、TIMING、VERBOSE)可以帮助开发人员获取非常详细的查询计划,但是有时候我们会有一些需要高度优化的需求,或者是一些语句的查询计划提供的信息不能完全判断语句的优劣,这时候还可以使用 session 级的log_xxx_stats 来判断问题。PostgreSQL 在 initdb 后,log_statement_stats 参数默认是关闭的,因为打开它会在执行每条命令的时候,执行大量的系统调用来收集资源消耗信息,所以在生产环境中也应该关闭它,一般都在 session 级别使用它。在PostgreSQL.conf 中有 log_parser_stats、log_planner_stats 和 log_statement_stats 这几个选项,默认值都是 off,其中log_parser_stats 和 log_planner_stats 这两个参数为一组,log_statement_stats 为一组,这两组参数不能全部同时设置为 on。查看 parser 和 planner 的系统资源使用的查询计划,如下所示:
Set client_min_messages = log;
Set log_parser_stats=on;
Set log_planner_stats=on;
explain analyze select * from t_analyzeplan limit 5;
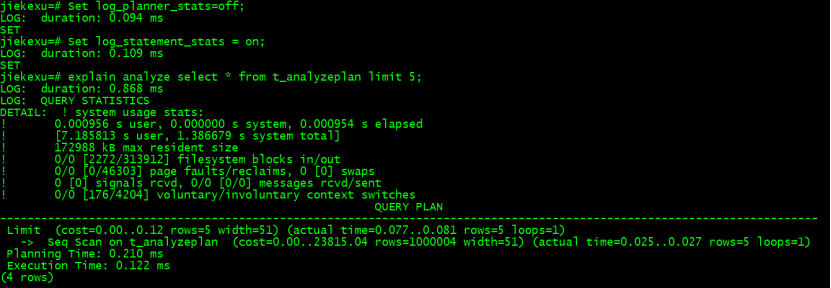
查看查询的系统资源使用,如下所示:
Set client_min_sessages = log;
Set log_parser_stats=off;
Set log_planner_stats=off;
Set log_statement_stats = on;
explain analyze select * from t_analyzeplan limit 5;
3、事务隔离级别
PostgreSQL 默认的事务隔离级别是 Read Committed。查看全局事务隔离级别的代码如下所示:
postgres=# select name,setting from pg_settings where name='default_transaction_isolation';
name | setting
-------------------------------+----------------
default_transaction_isolation | read committed
(1 row)
postgres=# select current_setting('default_transaction_isolation');
current_setting
-----------------
read committed
(1 row)
postgres=# SHOW transaction_isolation;
transaction_isolation
-----------------------
read committed
(1 row)
通过修改 PostgreSQL.conf 文件中的 default_transaction_isolation 参数修改全局事务隔离级别,修改之后 reload 实例使之生效;或者使用系统命令 alter system set default_transaction_isolation to 'REPEATABLE READ'; 来修改默认的事务隔离级别。
全文完,希望可以帮到正在阅读的你,如果觉得有帮助,可以分享给你身边的朋友,同事,你关心谁就分享给谁,一起学习共同进步~~~
❤️ 欢迎关注我的公众号【JiekeXu DBA之路】,一起学习新知识!
————————————————————————————
公众号:JiekeXu DBA之路
墨天轮:https://www.modb.pro/u/4347
CSDN :https://blog.csdn.net/JiekeXu
ITPUB:https://blog.itpub.net/69968215
腾讯云:https://cloud.tencent.com/developer/user/5645107
————————————————————————————

