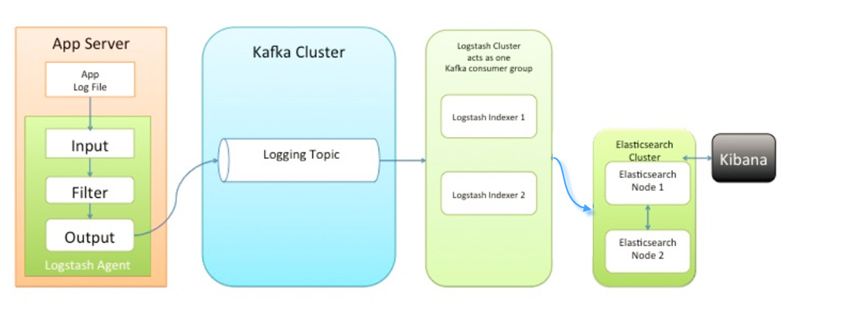
ELK 其实并不是一款软件,而是一整套解决方案, 是三个软件产品的首字母缩写,Elasticsearch,Logstash 和 Kibana。这三款软件都是开源软件,通常是配合使用,而且又先后归于 Elastic.co 公司名下,故被简称为 ELK 协议栈.
是三个软件产品的首字母缩写,Elasticsearch,Logstash 和 Kibana。这三款软件都是开源软件,通常是配合使用,而且又先后归于 Elastic.co 公司名下,故被简称为 ELK 协议栈.
ELK:日志协议栈
E:elasticsearch 全文检索框架 类似于solr L:logstash 日志数据采集框架 类似于flume K:kibana 报表展示框架
今天介绍一下ELK中的 Elasticsearch
简介
Elaticsearch,简称为es, es是一个开源的高扩展的分布式全文检索引擎,它可以近乎实时的存储、检索数据;本身扩展性很好,可以扩展到上百台服务器,处理PB级别的数据。es也使用Java开发并使用Lucene作为其核心来实现所有索引和搜索的功能,但是它的目的是通过简单的RESTful API来隐藏Lucene的复杂性,从而让全文搜索变得简单。
Elasticsearch 是一个实时的分布式搜索和分析引擎,它可以用于全文搜索,结构化搜索以及分析。它是一个建立在全文搜索引擎 Apache Lucene 基础上的搜索引擎,使用 Java 语言编写。
主要特点
– 实时分析
– 分布式实时文件存储,并将每一个字段都编入索引
– 文档导向,所有的对象全部是文档
– 高可用性,易扩展,支持集群(Cluster)、分片和复制(Shards 和 Replicas)。
– 接口友好,支持 JSON
Elasticsearch是面向文档(document oriented)的,这意味着它可以存储整个对象或文档(document)。然而它不仅仅是存储,还会索引(index)每个文档的内容使之可以被搜索。在Elasticsearch中,你可以对文档(而非成行成列的数据)进行索引、搜索、排序、过滤。
Elasticsearch核心概念
index:索引库,类似于mysql当中数据库
type:类型,类似于数据库下面的表
documents:一个document相当于关系型数据库中的一行row。索引表下面的一条条的数据.
fields:相当于是数据表的字段,对文档数据根据不同属性进行的分类标识
mappings:
映射关系,mappings主要是用于定义es当中字段的属性,相当于关系型数据库中的表结构。决定字段的分词,存储,以及索引特性
settings:定义分片数以及副本数。副本数创建之后可以进行更改
分片数一旦创建之后,就不能更改了
node:es节点,节点是集群的一部分
cluster:集群,集群由一个或多个节点组成,es节点组织到一起就是es的集群
shard&replicat:
分片与复制,副本是分片的副本。分片有主分片(primary Shard)和副本分片(replica Shard)之分。一个Index数据在物理上被分布在多个主分片中,每个主分片只存放部分数据。每个主分片可以有多个副本,叫副本分片,是主分片的复制。
Elasticsearch 安装部署
第一步:创建普通用户
ES不能使用root用户来启动,必须使用普通用户来安装启动。这里我们创建一个普通用户以及定义一些常规目录用于存放我们的数据文件以及安装包等
创建一个es专门的用户(必须)
#使用root用户在三台机器执行以下命令
useradd es
mkdir -p /export/servers/es
chown -R es /export/servers/es
passwd es
第二步:为普通用户es添加sudo权限
为了让普通用户有更大的操作权限,我们一般都会给普通用户设置sudo权限,方便普通用户的操作
三台机器使用root用户执行visudo命令然后为es用户添加权限
visudo
es ALL=(ALL) ALL
第三步:下载并上传压缩包,然后解压
tar -zxf elasticsearch-6.7.0.tar.gz -C /export/servers/es/
第四步:修改配置文件
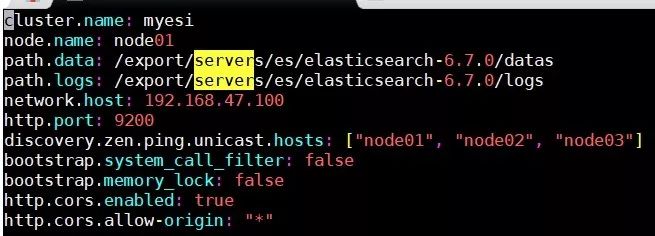
01,修改elasticsearch.yml
node01服务器使用es用户来修改配置文件
cd /export/servers/es/elasticsearch-6.7.0/configmkdir -p /export/servers/es/elasticsearch-6.7.0/logsmkdir -p /export/servers/es/elasticsearch-6.7.0/datasrm -rf elasticsearch.ymlvim elasticsearch.yml
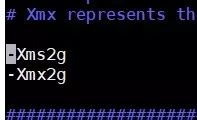
02,修改jvm.option
修改jvm.option配置文件,调整jvm堆内存大小
node01使用es用户执行以下命令调整jvm堆内存大小,每个人根据自己服务器的内存大小来进行调整
第五步:将安装包分发到其他服务器上面
node01使用es用户将安装包分发到其他服务器上面去
cd /export/servers/es/
scp -r elasticsearch-6.7.0/ node02:$PWD
scp -r elasticsearch-6.7.0/ node03:$PWD
第六步:node02与node03修改es配置文件
第七步:修改系统配置,解决启动时候的问题
由于现在使用普通用户来安装es服务,且es服务对服务器的资源要求比较多,包括内存大小,线程数等。所以我们需要给普通用户解开资源的束缚
解决启动问题一:普通用户打开文件的最大数限制
三台机器使用es用户执行以下命令解除打开文件数据的限制
sudo vi /etc/security/limits.conf
添加如下内容: 注意*不要去掉了
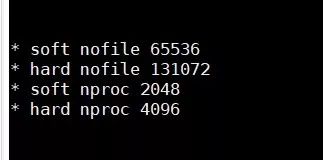
解决启动问题二:普通用户启动线程数限制
sudo vi /etc/security/limits.d/90-nproc.conf
找到如下内容:
* soft nproc 1024#修改为
* soft nproc 4096
解决启动问题三:普通用户调大虚拟内存
三台机器执行以下命令,注意每次启动ES之前都要执行
sudo sysctl -w vm.max_map_count=262144
第八步:启动ES服务
三台机器使用es用户执行以下命令启动es服务
前台启动:
cd /export/servers/es/elasticsearch-6.7.0/bin/
./elasticsearch
后台启动:
nohup /export/servers/es/elasticsearch-6.7.0/bin/elasticsearch 2>&1 &
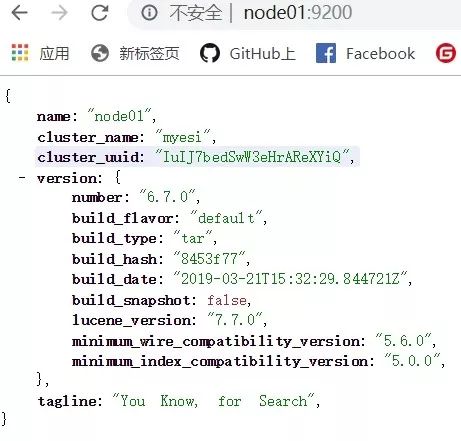
启动成功之后jsp即可看到es的服务进程,并且访问页面
http://node01:9200
能够看到es启动之后的以下一些信息就成功了: