




引言
微信读书AI问书探索之旅
当用户搜索命中关键词则呈现相关结果,缺点如下:
● 标签词数量与用户搜索词差距大。
● 无法表达复杂语义,如组合词、多义词、开放式问题。
● 一本书关键词多,难以判断质量,例如一本《三体》数千关键词难以评估相关性。
● 标签与出版社分类一致,难以获得在线阅读新鲜体验感。
召回不同句子判断是否作为观点与知识展示与引导,缺点如下:
● 无法回答复杂问题,观点之间缺乏相关性。
● 用户体验上无创新,类似传统全文搜索增加过滤与重排序。
对搜索词进行生成式答案返回,如搜索《茶馆》,能关联性搜索“老舍”相关作品,缺点如下:
● 用户习惯未培养起来,很难想到问什么问题。
● 搜索词较为单一,缺乏深度与广度。
AI问书能力介绍



最初,微信读书不是采用腾讯云 ES 方案,存在比较大的技术挑战:
● 数据规模大:整体数据超 10 亿级向量规模,存储成本高。早期评估的非 ES 方案,为了满足毫秒级查询,需要缓存全部数据到内存中,则 30 亿 768 维的向量,需要超过 400 台64G机器,运营成本百万级。
● 运维成本高:除了全文检索,同时还需部署向量化服务,在外部进行向量化后,写入到向量数据库,同时向量数据库不存储原始 meta 信息,还需要额外部署正排服务,相当于需要同时运维四套系统。
● 开发成本高:调试召回过程中,需要在外部进行向量化后,从向量数据库召回,然后再用召回 id 访问正排获取meta信息。相当于每一次召回调试需要 3 次操作,跨越 4 个系统。
● 稳定性要求高:在线读书平台超亿级用户,稳定性要求 5 个 9 以上。
● 查询性能要求高:高并发场景下查询延迟需要毫秒级返回,数亿量级数据全链路多路召回需控制在 100ms 以内。
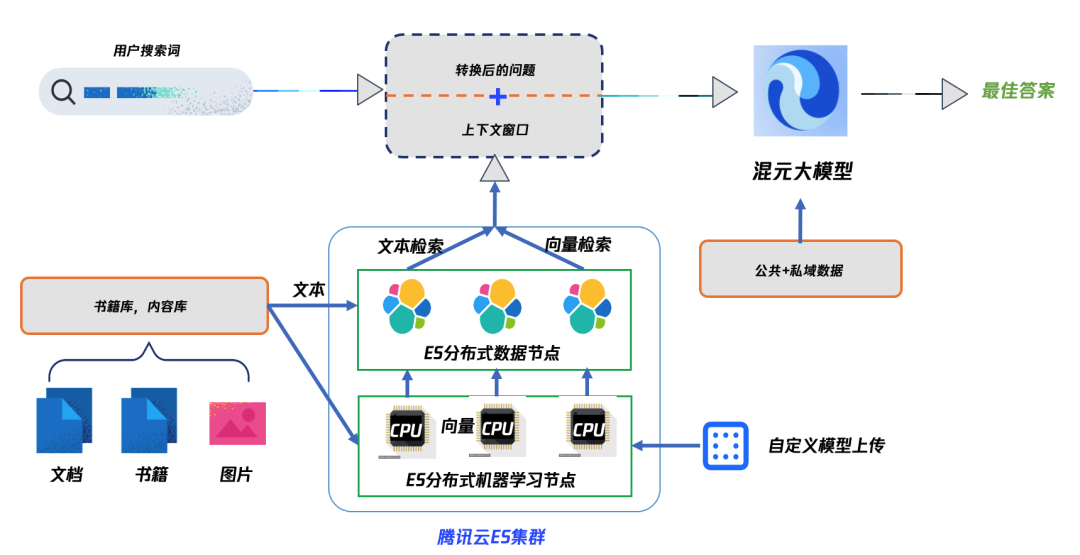
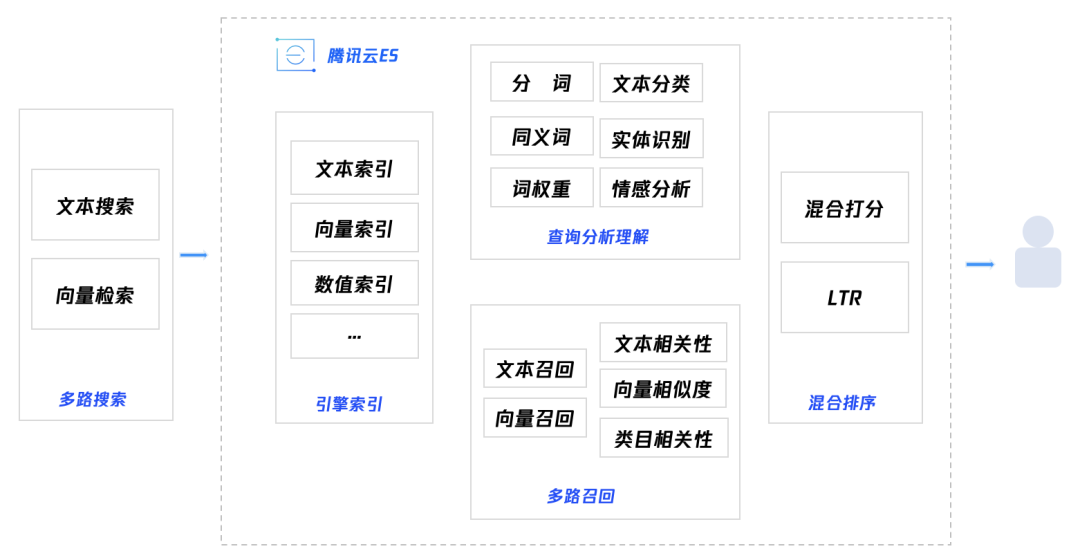
腾讯云 ES 提供了一站式的 RAG 方案,具体而言, AI 问书在实现过程中,主要应用了以下能力:
● 知识向量化:通过上传自定义的 embedding 模型到腾讯云ES提供的机器学习节点中,实现书籍内容与搜索词的向量化( embedding )。
● 混合搜索:腾讯云 ES 提供了全文检索与向量检索能力,只需要简单的一条查询语句,即可从 ES 中实现混合搜索与多路召回。
● 与大模型集成:腾讯云 ES 支持通过 API 与大模型进行集成,从 ES 召回的数据,可与 Prompt 一起送进到大模型中进行生成式整合,最终完成智能问答。
● Kibana 调试:作为与 ES 天然集成 Web 页面, Kibana 提供了丰富的可视化能力,能帮助开发运维人员快速进行召回调试,并在 Kibana 上完成模型的部署与管理。
● 安全高可用:腾讯云 ES 自研全链路熔断限流方案,同时支持多副本、多可用区部署,能够有效保障在线业务稳定性。
● 资源成本低:腾讯云 ES 提供了低成本的一站式向量检索方案,从原来的纯内存 400 台 64G 机器下降到30台,大幅降低硬件成本。
● 运维成本低:腾讯云 ES 提供了一站式 RAG 方案,同时提供全文检索、向量检索、向量化服务,降低服务服务运维成本,从 1 次调优跨 4 套系统,到“所见即所得”,开发运维人员在 Kibana 上即可调试召回流程。
● 高性能高可靠:数亿量级索引召回平均耗时在 100ms 以下,基于腾讯云 ES 强大的专业支持团队与安全高可用能力,保证稳定性及可靠性。
腾讯云ES一站式RAG能力介绍
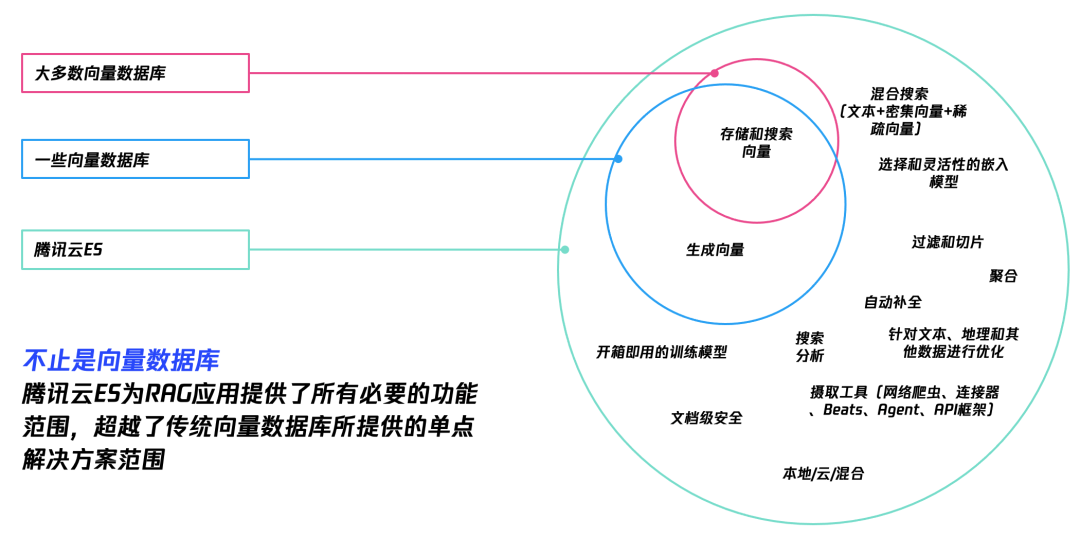
向量索引/存储->向量检索的全流程操作,具体能力如下:
基于腾讯云 ES 提供的能力,我们可以直接完成向量生成->向量索引/存储->向量检索的全流程操作,具体能力如下:
● 内置开箱即用的 ELSER 语义模型。
● 支持上传自定义模型或从 Hugging Face 等开源社区直接上传模型。
● 支持专有机器学习节点,用于向量推理(可选,也可跟数据节点混部)。
● 支持向量索引( HNSW 算法)、向量存储与 KNN 检索。
混合搜索是指结合了全文检索和向量检索技术的搜索方式,这种方法旨在利用两种技术的优势,提供更加准确和全面的搜索结果,其优势如下:
● 更精准:混合搜索可以同时利用关键词检索和向量搜索对数据进行查询,提高检索的准确性和可信度。
● 更多样:混合搜索可以利用向量检索的多样性,返回多种不同的检索结果,提供更多的选择和信息,满足不同的用户查询需求和偏好。
● 更强大:混合搜索可以利用关键词检索的逻辑运算、排序、过滤等功能,实现更复杂的查询需求。如包含多个条件、多个字段、多个排序规则等的查询,这可以提高检索的功能和灵活性。
● 更可解释:混合搜索可以利用关键词检索的文本匹配和高亮显示,实现更可解释的检索结果。如显示查询语句和文档的匹配程度、匹配位置、匹配内容等,这可以提高用户对检索结果的理解和满意度。
RRF 的优点如下:
● 简单性:RRF 不需要复杂的归一化步骤,只需要知道每个文档在每个系统中的排名。
● 鲁棒性:由于 RRF 基于排名而不是评分,它对不同评分尺度和分布的敏感性较低。
● 公平性:RRF 通过相同的公式为所有系统的排名赋予权重,从而确保了所有系统在融合过程中的公平性。
● 易于实现:RRF 算法的实现相对简单,不需要复杂的参数调整或训练过程。
● 适应性:RRF 可以很容易地适应新的系统或数据,因为它不依赖于特定的评分机制。
紫霄 GPU 支持
腾讯云 ES 是全球首个支持 GPU 的 ES 服务,它可以与腾讯自研“芯”技术紫霄软硬结合,充分利用GPU的性能优势,提高向量生成和检索的效率。例如,紫霄 V1 具有高能效、高吞吐、高带宽等特点,设计算力规格 NVIDIA A10 相当,显存带宽比 A10 高 30% ,最高可比 A10 性能高 50%-100% 。在常见中小模型上,紫霄相比NVIDIA T4 通常有 100% 以上的性能提升,相比 NVIDIA A10 有 20%+ 的性能优势。
自研内核优化
腾讯云 ES 在内核层面,针对微信读书的典型场景特点做了更多优化,比如分片架构优化,查询并行化, lucene 查询缓存锁改造等, 10 亿级向量检索平均响应延迟控制在毫秒级,整体帮助向量场景查询性能提升 3-10 倍:
a. 分片架构优化:针对向量场景,合并查询跟归并流程,总体查询性能提升 2 倍以上。
b. 块存储跟查询优化:通过对 Segment 进行合并收敛,减少查询随机 IO ,总体查询性能提升 2 倍以上。
c. 查询并行化:多线程文档切分、多 Segment 并行化处理、精准拉取文件数据段。
d. lucene 查询缓存锁改造:大幅提高了查询的并发能力,QPS 提升 50% 以上。
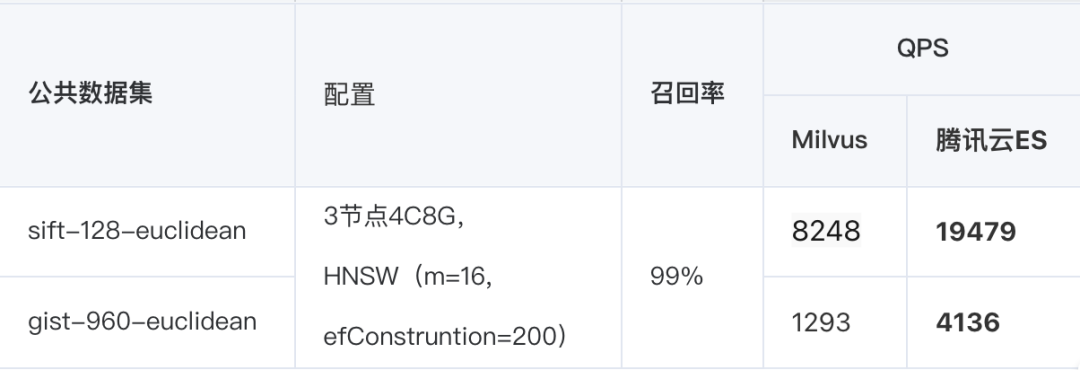
腾讯云 ES 与 Milvus 对比
我们基于开源工具 ann-benchmark 进行了详细性能测试,通过检索不同维度的数据集在召回率达到 99% 的情况下,获取最相似的 Top10 的文档,对比 Milvus、与腾讯云 ES 的 QPS 数据。
总结
关注腾讯云大数据公众号
邀您探索数据的无限可能

点击阅读原文,了解更多产品详情
↓↓↓
