





彭涛
神州信息 核心解决方案 BU 技术总监
从事金融 IT 行业 15 余年,先后参与了 16 个银行核心系统建设其中 7 个为分布式微服务核心、30 多个支付业务系统建设,有着丰富的银行 IT 系统实施经验。近 5 年来主要从事分布式+微服务架构核心系统落地,助力银行数字化转型以及核心系统主机下移,在国产数据库落地银行核心系统上有较深入的研究,其主导的某银行分布式微服务核心系统落地国产分布式数据库,实现了核心系统日终批处理 10 分钟内处理完成、20 万笔批量代发 60 秒内处理完成。
核心主机下移是金融企业数字化转型过程中面临的最大挑战之一。对稳定性、安全性、可用性、业务连续性等指标有着苛刻要求的银行更关注核心业务系统主机下移的解决方案。神州信息核心解决方案 BU 技术总监彭涛带来了主题为《银行核心业务系统数据库主机下移架构与实践》的分享,站在银行系统视角分析了核心业务系统数据库主机下移的考量点。
银行核心业务系统数据库主机下移的关注点
数据库主机下移的关注点可分为开发、运维、高可用、容灾几个维度。
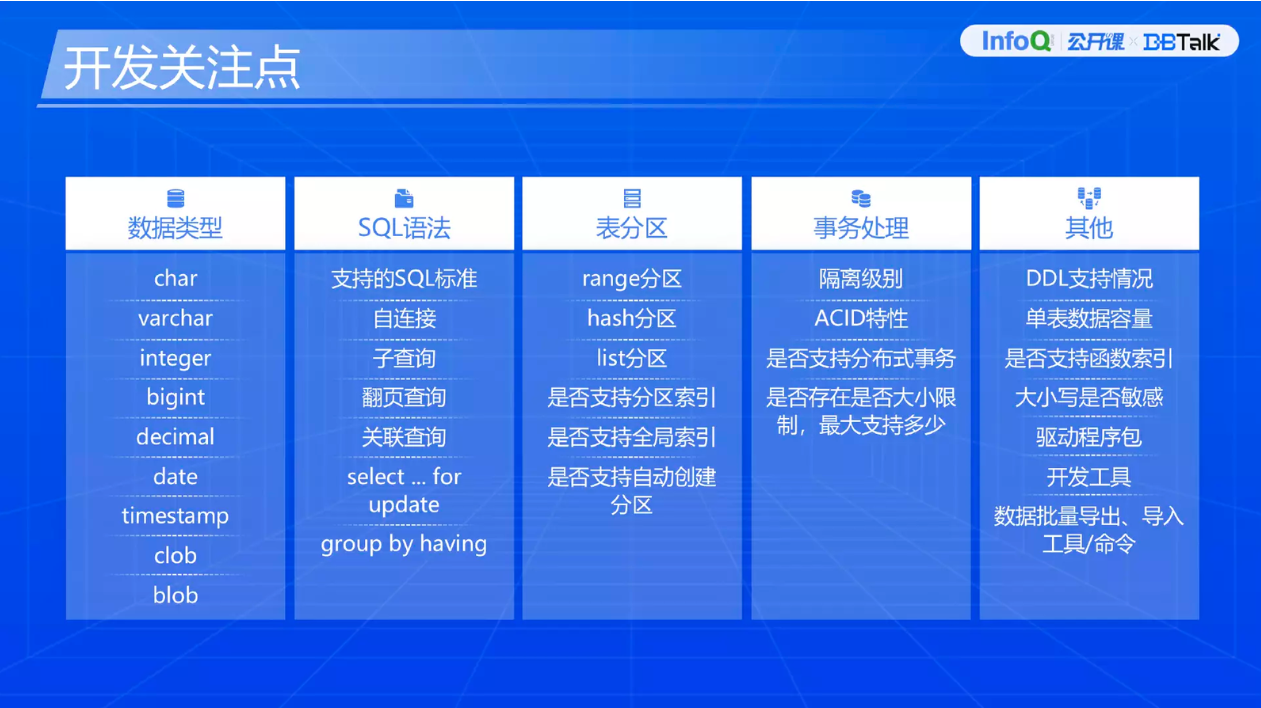
首先是开发关注点,分为 5 个层面。数据类型这块更关注 data 类型和 timestamp 类型,clob 和 blob 使用场景、高效存取能力也要重点关注。
SQL 语法层面包括支持的 SQL 标准、自连接查询 SQL 语法、子查询。常见的子查询会使用到 SQL 各个关键字段后面,比如说最常见的 where 条件后面的子查询。第二个是在关联之后的子查询,可能会放在一个临时的表做一些关联。第三个是整个 select 关键字后面的子查询。
接下来是翻页查询关注点,翻页查询在 MySQL 系、DB2 系、Oracle 系的支持情况不一样,我们也需要在开发的时候关注翻页查询。接下来是关联查询,需要看关联查询语法的执行情况。再下来是隔离级别,就是一个特殊语法——select ... for update。select ... for update 可能跟后边的隔离级别会有一些考量点,因为目前已知 DB2 对于 select ... for update 的处理,跟 MySQL 和 Oracle 的语法处理不一样,因为 DB2 支持 select ... for update 它不是悲观锁,是一个可重用的锁,所以这块对于应用层来说需要关注它的特殊用法。我们要实现类似悲观锁的机制,DB2 的时候需要在后面加隔离级别的语法。最后一块需要关注分组查询或者分组查询后的条件过滤,group by having 语法。
第三块是表分区关注点,包括常见的 range 分区、hash 分区、list 分区,以及我们分区之后对于索引的支撑,是否支持分区索引或者说支持全局索引,最后一个是创建分区之后数据库是否支持自动创建分区。
第四块是事务处理关注点,第一个是隔离级别,这块 DB2 跟其他数据库还是有一定差距,所以开发者视角需要关注这块。第二个是事务 ACID 特性,再下来是针对分布式数据库特性,它是否支持分布式事务。最后一块是是否存在大小限制,最大支持多久。对一些数据库而言这里考虑的是支持条数,比如说最大支持 5 万行记录更新,有的数据库可能给不了大小限制,可能给数据库大小限制,比如说这次更新影响到多少 M 的数据。
最后一块是其他关注点,比如说一些 DDL 语句关注点,我们是否支持在线修改语法。再下来是单表数据支持,在不分区情况下一个表能存储多少数据,并且能够在高并发读写操作下保证稳定性,这是我们评判的标准。再下来是是否支持函数索引,跟应用系统的优化相关,我们在一些特殊场景下需要建立一个函数索引,评估整个连接交易的处理性能。再下来关注大小写是否敏感,主要是列名、表名的大小写,数据的大小写敏感是肯定的。再下来是驱动包情况以及是否有图形化、可视化的开发工具,以及是否支持数据批量导出导入的工具或者命令的支撑。这是站在开发者视角的关注点。
下面看运维视角关注点。第一个层面是可视化运维工具,我们是否有一个可以图形化操作的工具能够看到整个数据库的运行性能、运行状态,以及数据库资源使用情况。第二块是备份和恢复工具的支撑,包括全量备份、增量备份,以及物理备份、逻辑备份工具支撑。第三块是数据库运行报告,能否导出一些数据库运行报告,比如说 TOP SQL,便于开发运维人员优化;还有数据库资源使用情况,以及性能指标,比如说 QPS 等等一些指标。第四块是是否支持在线升级,以及数据库升级是否对上层应用是透明无感的。第五块是是否支持数据库横向扩展,是否能够通过横向加资源提升整个数据库的处理性能。第六块是是否支持动态资源调整,我们在前期做数据库资源规划时相对而言资源给的小一些,随着数据量增加,能不能通过动态资源调整提升微服务数据库资源,进而让数据库访问性能得到提升。最后一块是对于信创的支持,信创这块包括对国产化芯片的支持、对国产化操作系统的支持,以及国产化中间件的支持。这是站在运维者视角的关注点。
最后看一下高可用以及容灾的关注点。首先是整个数据库在双中心/多中心高可用方案及满足的 RPO、RTO 指标。这块还需要关注中心之间数据同步方式,是否引入商用数据库作为兜底方案。国产分布式数据库彻底被市场所认可之前,很多银行都会考虑兜底库的方案,我们在做高可用以及容灾关注点的时候也需要考虑引入一个兜底库方案。第二块要考虑主从或者主副本切换的时间,以及切换的时候数据一致性保障,主从或者主副本切换是否能够做到对应用无感,就是说切换之后是否需要重启,或者是否需要做数据源重置。第三个跟第一个相关,如果说我们引进了异构数据库兜底方案,异构数据库之后的双向同步,包括表结构初始化、数据初始化,以及初始化数据增量校验,和一些运行态下增量数据的准实时同步这些能力是否具备。这是高可用及容灾的关注点。
下面来看核心业务的关注点。银行核心业务系统的典型业务场景分四类:
第一类是联机业务,包括查询业务、账务类业务、维护类业务。维护类业务包括签约、解约、账户信息变更。查询类就是交易明细类等查询。
第二类是联机批量业务,又分成三类,查询类、维护类、账务类。查询类顾名思义,返回的是一个文件。维护类是接收到一个文件,返回也是一个文件,但实际上它有一定的业务逻辑处理,包括批量开卡、批量开户的场景。最后一类是账务类,典型场景是批量代发、批量代扣等场景。
第三类是日终批量,包括账户计提、账户解析、到期处理。
第四类是定时任务,像短信推送、定时查证和同步、历史数据处理。

联机业务场景对数据库访问的特性如上图。

联机批量业务对数据库的访问特性如上图。
下面是日终批量业务和定时任务业务场景的访问特性。


银行核心业务系统数据库主机下移架构设计
下面看一下数据库主机下移时的架构设计考量。

首先来看核心业务系统的数据架构。目前核心系统都做了微服务拆分,每个微服务都是独立部署,数据库数据做了一层垂直切分,切分维度是纵向切分,按照不同的微服务做整个数据拆分。
比如说我拆分出来客户信息数据、运营管理类数据、存款类数据、贷款数据、核算数据,以及一些分布式组件或者说辅助功能的数据,做垂直拆分。垂直拆分完之后在微服务内部按照实际情况做水平拆分。比如说存款数据,在存储账户量很大的时候做水平拆分。流水类和登记簿类数据不拆分,因为随着时间增加它的数据量会越来越大,所以这类数据会做分区处理。也就是说整个数据架构来看,按照微服务做垂直拆分,在微服务内部根据实际情况做水平拆分,不管做不做水平拆分,对于流水类和登记簿类的数据都会做分区类处理。
下面来看微服务内部数据水平拆分时主要有哪些考量点。
第一是数据库单表容量,不分区的时候高并发读写时保持稳定且较高性能,单库单表到多少数据量的时候维持高并发读写,还是稳定的高并发读写。
第二是主体数据容量,包括当前数据容量以及未来规划数据容量。我们关注的是主体数据,不是说最大表的数据。比如说站在银行核心业务系统角度可能关注客户或者账户主体数据量,而不会关注交易明细或者交易流水数据容量。
第三是联机交易高并发数据处理能力,就是分库和不分库的处理能力。还有批处理能力,如果不分库就是要看数据库在单机下的处理能力。
第四是做水平拆分是用分布式数据库的特性,还是说在应用层做水平拆分。衍生出来的问题是说拆分之后分布式事务由谁处理,这是微服务要做水平拆分的考量点。
我们再看一下微服务数据水平拆分后的数据架构。整个核心业务系统数据粗略分成四大类,第一类是参数表,不需要做水分拆分,因为它数据量不大。参数表还可作为全局表/广播表。第二个是不拆分的业务表,一般是业务处理中间表数据,比如说批量代发或者代扣的文件入库的数据。第三个是业务表要做水平拆分的数据表,这块按照分库键/分片键水平拆分。第四类是框架表,它取决于系统设计的框架,包括一些调度表。这类可以做水平拆分也可以不做水平拆分,一般建议不做水平拆分,把它放在一个单独的库,我们姑且叫做垂直库。它在存储的时候用分区+历史表的方式存储,该类表数据查询和更新的频率不高。
做水平拆分后的数据的整体架构中,我们会有垂直库,里面放的是框架类的表和不拆分的业务数据表。当然,在这块设计的时候也会有往垂直库放个别参数表数据的情况。水平库里主要放参数表数据以及拆分后业务表的数据。
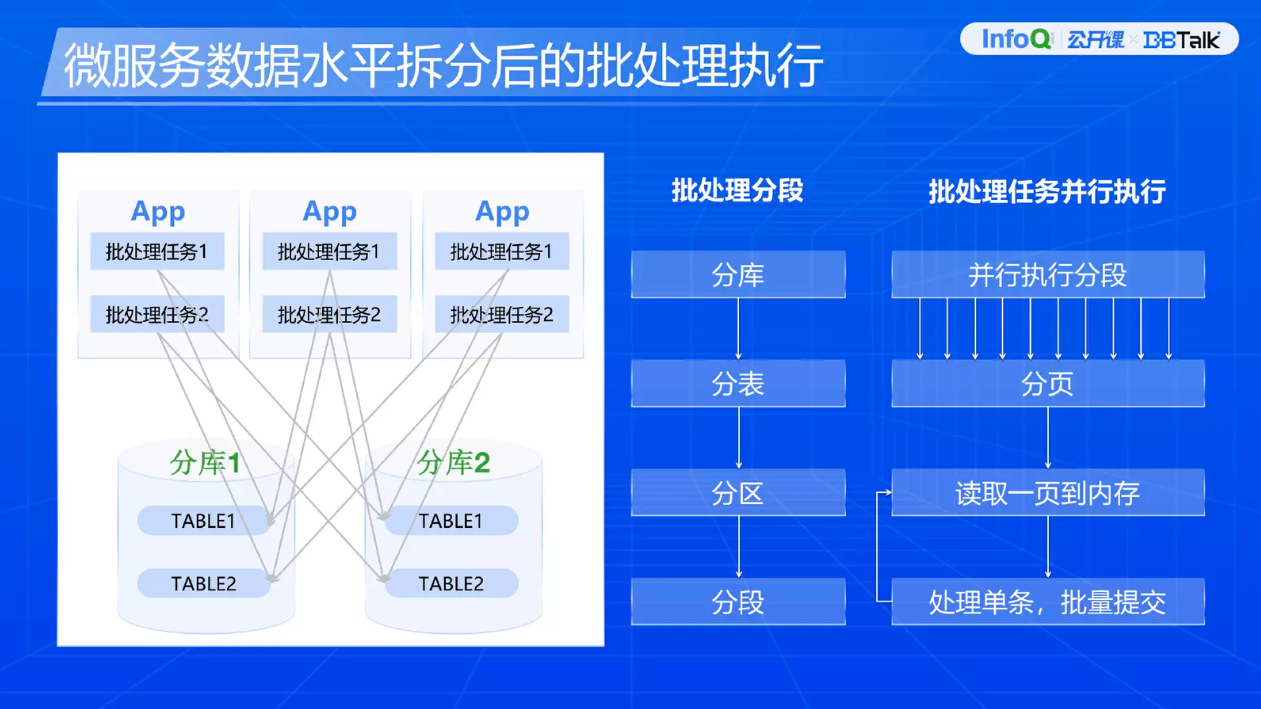
再看微服务数据水平拆分后的批处理执行。为了保障批处理高效我们会做分段处理。涉及批处理的时候可以看左图,我们在拆分批处理任务的时候尽量用某一个批处理任务去查询主体的某一张表或者某两张表,大部分场景下建议查询主体数据在某一张表里面。批处理任务 1 访问的是 TABLE1,批处理任务 2 访问的是 TABLE2,这个 TABLE2 有可能是 1 库的 TABLE2,也可能是 2 库的 TABLE2。这是批处理设计上的考量。
在批处理做分段的时候怎么保障高效性呢?第一个,我们避免在同一个分段里出现跨分库的数据,避免分布式事务场景。在分段的时候优先考虑分库,分库下来再分表,拆分不同表去做不同分段,有可能是一库十表。在做分段的时候一库上的十张表都做分段,比如说我会拆成 1000 条一段,至少说十张表会有十个段。
然后是分区,有一些表做分区,处理的时候我们也是避免跨分区数据在同一个段里,就是为了提高查询效率,减少跨分区查询,最后才是数据分段。
分段之后是批处理任务并行执行,我们把整个分处理的段做并发处理。这里面提到分页,分页解决了分段比较多时遇到的问题。比如说分成一万条一段,当并发上来的时候,比如说并发 500 个,意味着我要一次性从数据库里查 500 万条记录进来,这个时候也是为了降低数据库内存的压力,所以我们这块做了分页,把一万条数据分成 5 页,每一页 2000 条读取,读取之后在内存里逐条处理,然后批量提交。比如说我每次读 2000 条,有可能为了控制事务大小每 200 条记录做一个提交,这是整个批处理拆分后的任务执行过程。
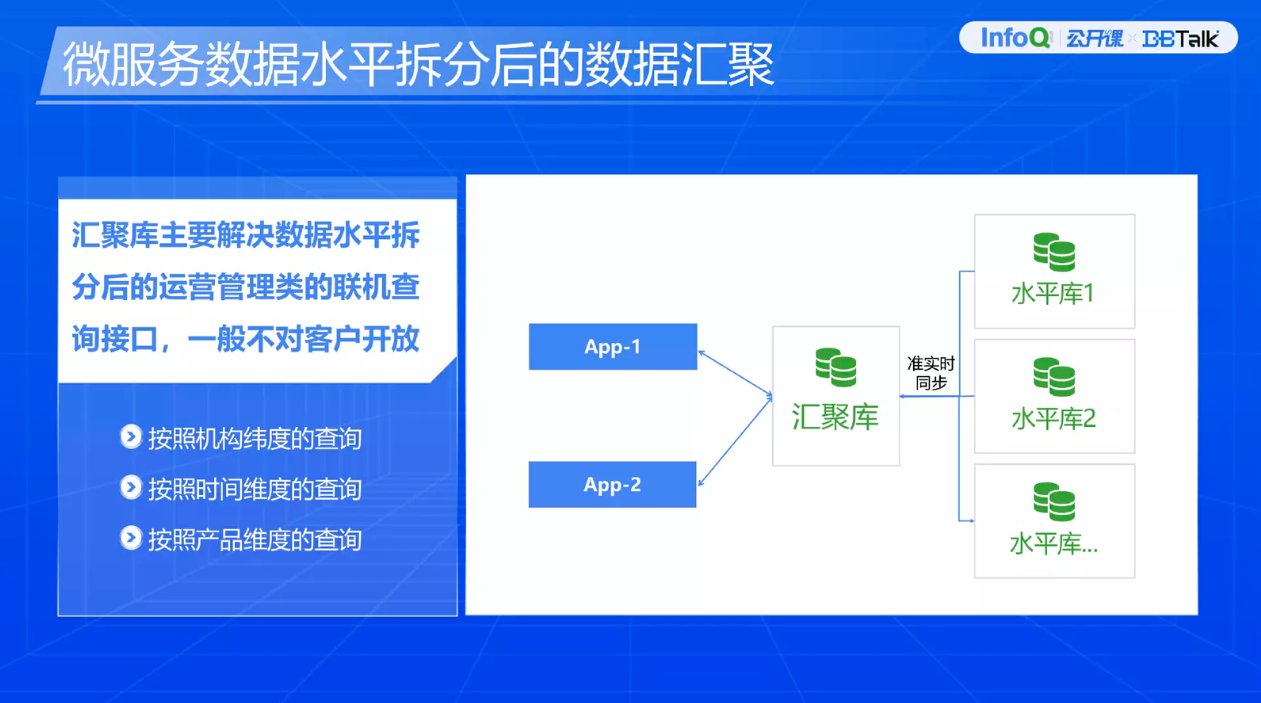
微服务数据水平拆分后有一些数据汇聚场景很特殊。这类场景主要是运营管理类,是管理人员查询使用,一般不会对客户开放。这里有按照机构维度的查询、按照时间维护的查询、按照产品维度的查询。它对数据的时效性要求不高,我们为了避免把大量数据聚合拉到数据库内存或者应用内存里处理,所以引入了汇聚库的概念。我们对这类查询数据通过一些同步工具准实时同步到汇聚库上,对外提供一些汇聚数据查询的服务。
再看数据高可用设计。首先要考虑对于信创数据库或者国产数据库需不需要引入异构数据库进来作为兜底方案。如果要引入会有一些关注点,比如说主备数据库语法的兼容度,Oracle 语法跟 MySQL 语法、DB2 语法差异相对大一些。第二块,对于数据类型匹配度,刚才罗列了应用系统视角需要使用到哪些数据库,要考虑它们的类型在多个数据库之间的长度、单位是否一致,存储是否一致。第三个,整个数据库事务隔离级别是否一致。第四个,我们有没有一些工具能够做到数据双向同步以及同步时效性,是秒级还是分钟级。第五个,需要考虑我的应用系统能否只用一套代码同时支持或者兼容主备两种数据库。最后一个要考虑主备数据库怎么切换。
最后是核心业务系统在异构数据库场景下如何做高可用架构。首先我们对主库会有一个分布式数据库多副本跨中心集群,更多是依赖数据库特性,对于微服务按照实际情况做水平拆分。对于异构数据库这块也是集群部署,它会依赖于兜底数据库自身的集群能力。
我们的汇聚库场景有多副本跨中心集群。这块牵扯到整个数据库之间的同步,比如说主备数据库之间的同步、主库跟汇聚库之间的同步。当然这里对数据同步时效性要求不是特别高,只要做到准实时甚至异步同步都可以,但异步同步时间不能太长。
案例分享
最后看一下两个我参与的数据库主机下移案例。第一个案例是某银行核心系统主机下移的案例。它原本是高可用架构,我们做的是在应用层双中心双活一个高可用架构。在数据库层面我们用到了分布式数据库特性,在应用层做分库。我们可以设置它的主本数据存放位置,整个集群是双中心数据库,都对外提供服务,也变相实现了数据库双活架构。
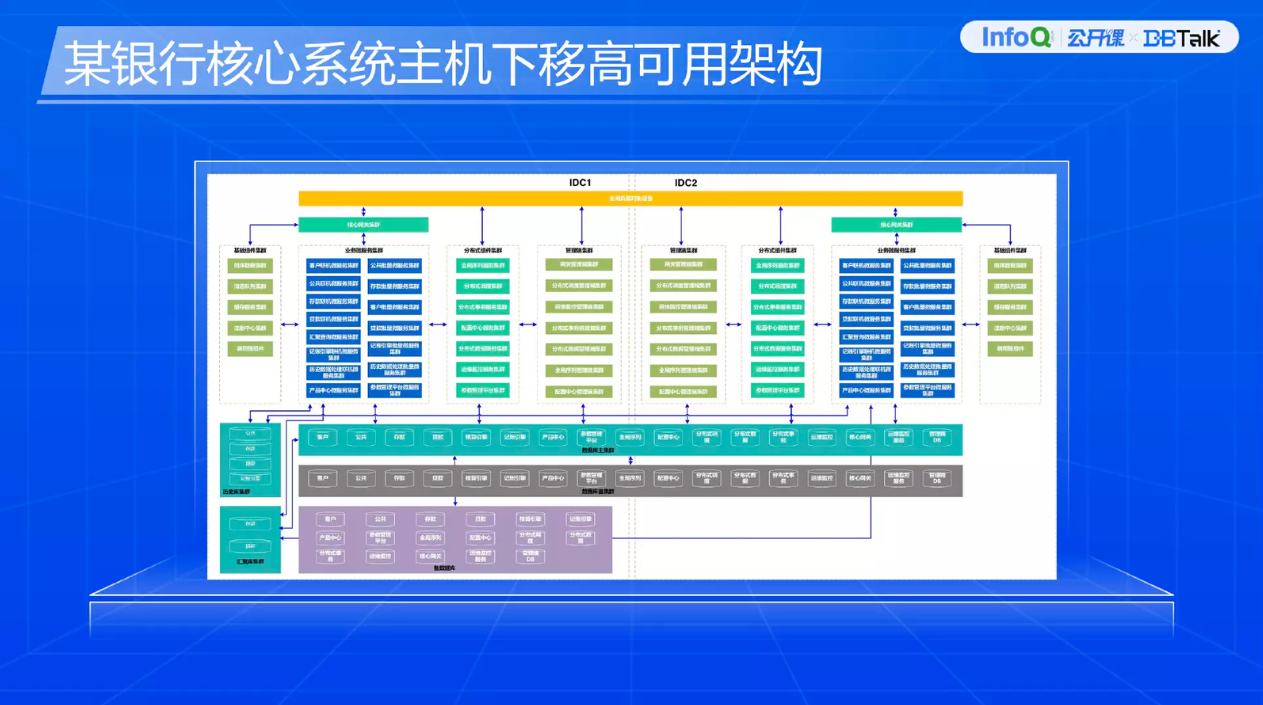
左下角两块一个是历史库,一个是汇聚库,灰色这块做了主数据库集群处理。之所以会引用备集群,是因为备集群跑在全信创的架构下。紫色是异构兜底数据库。
我们在主库上做了垂直拆分,在存款和贷款做了水平拆分。我们还有一个主数据库的备集群,备集群运行在纯国产化的服务器上,它们之间的数据做准实时同步。下面有一个备数据库部署,当时规划的是备数据库在短期内会下线,所以它并没有做双中心部署。再下面是历史库和汇聚库。对于历史数据并没有产生数据库,而是在应用层做了历史数据迁移,这块做了异步处理。汇聚库场景做了双中心集群部署。
下一个是外资银行案例。因为它的数据体量相对较小,所以并没有做双活部署,做的是主备模式。整个核心系统,包括数据库都做了云化私有云部署。数据库采用的是一主三从的部署架构,在主中心会部署一主一从两个副本,在备中心部署的是两个从副本。
数据同步、数据高可用来看,备中心两个从数据库节点都是按照数据强同步方式去做的,对于本中心从节点做的是异步同步,能够保证数据绝对不丢,因为备中心的两个从副本是强同步,RPO 是 0。
