





背景
当然除了利用数据库服务高 QPS 的在线事务,大量的客户需要挖掘数据的价值,利用数据库进行数据分析,帮助企业进行更好的进行业务决策,推动的业务的迭代创新,快速适应市场环境的变化。
但是传统数据库包括 TDSQL 为了支持高性能的在线事务处理能力,并且保证业务查询的稳定性,在存储结构上往往选择了行式存储,在执行模型上选择了火山模型,这种计算模型使用的内存比较少,在 TP 这种并发比较高的场景下系统也能提供比较稳定的服务。但是这种计算模型导致了其无法高效的服务分析类查询。
当然部分客户为了能够支持事务以及分析的混合负载(HTAP, Hybrid Transactional/Analytical
本文从物理执行器的角度来介绍下计算模型的演进过程和优化手段。
基础概念
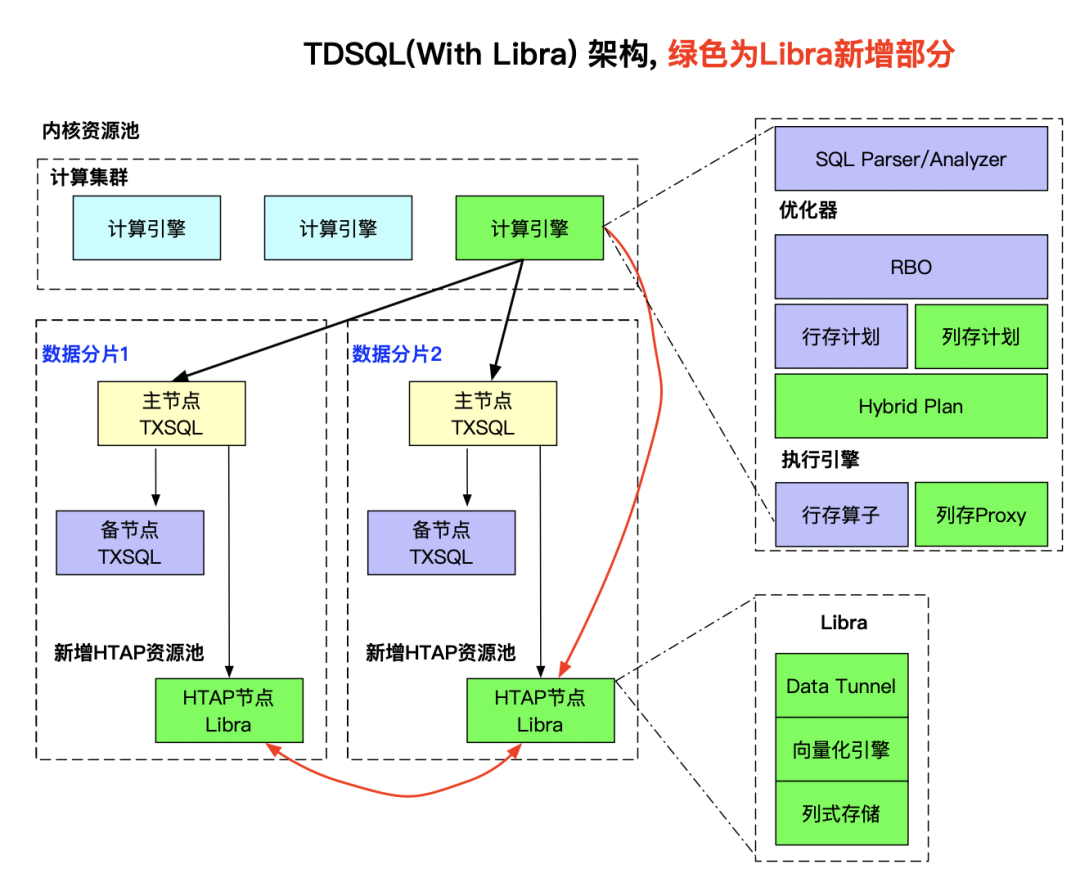
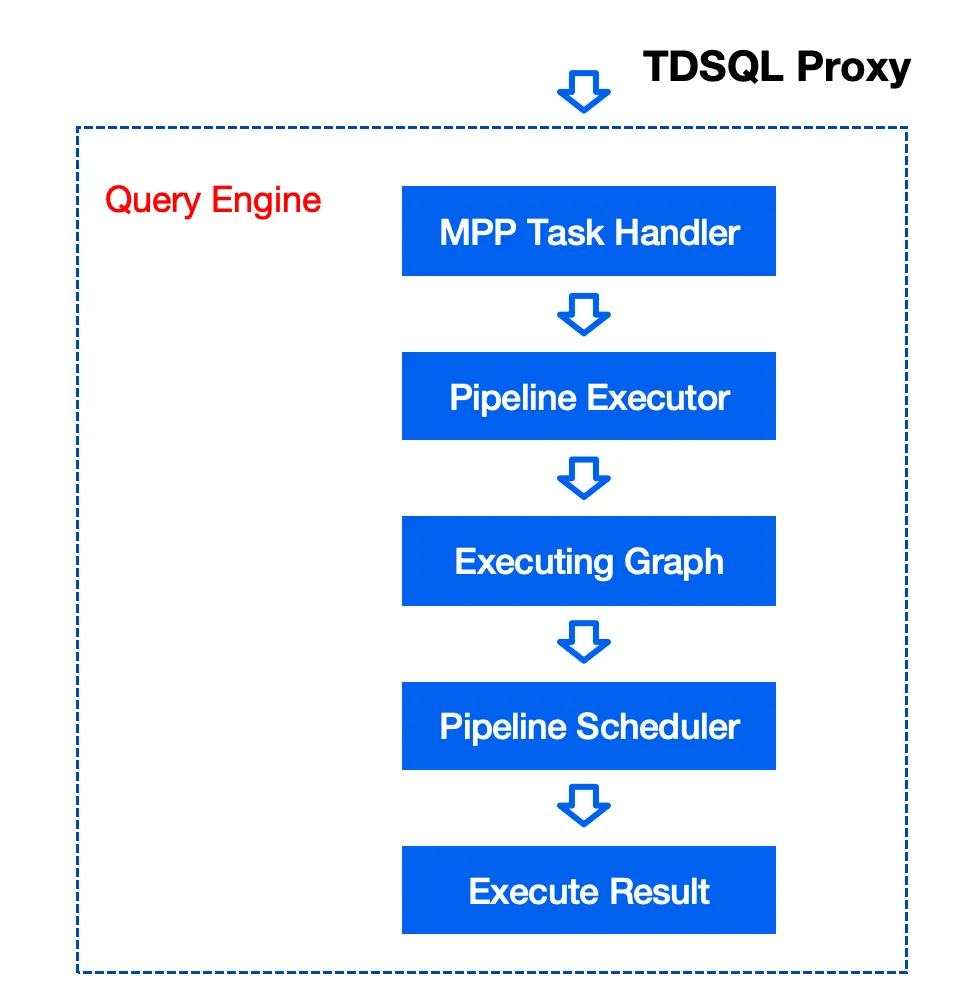
1. TDSQL 计算引擎组件
负责 SQL 的语法解析、语义解析、列存、行存逻辑计划的优化、列存、行存物理计划的生成。
2. 计划片段(Fragment)
Fragment 是物理执行计划的一部分。只有当执行计划被 TDSQL 计算引擎拆分成若干个 Fragment 后,才能多机并行执行。Fragment 是由物理算子构成,另外还包含 Sender 、Receiver 算子。上游的 Fragment 通过 Sender 向下游 Fragment 的 Receiver 算子发送数据。
3. 计划片段实例(MPP Task)
参考《Efficiently Compiling Efficient Query Plans for Modern Hardware》和《MonetDB/X100: Hyper-Pipelining Query Execution》这两篇论文,计算节点上的执行器会把 MPP Task 进一步拆分成若干 Pipeline 。每个 Pipeline 会根据 Pipeline 并行度参数而被实例化成一组 Pipe , Pipe是 Pipeline 实例,也是 Pipeline 执行引擎所能调度的基本任务。
4. Pipeline
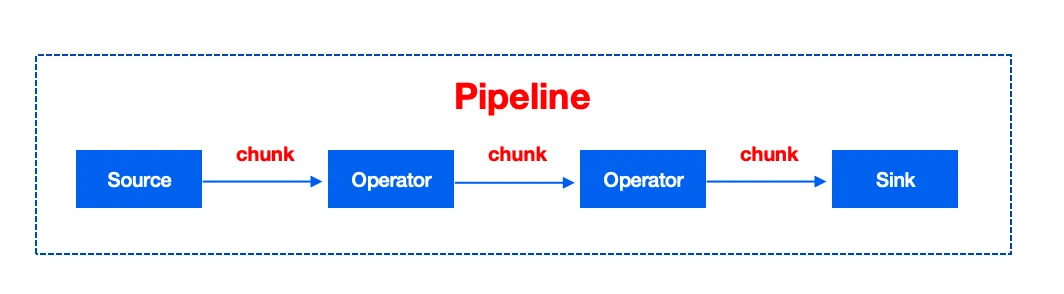
5. Pipe
每个 Pipeline 会根据 Pipeline 并行度(dop)参数而被实例化成一组 Pipe, Pipe 是 Pipeline 实例,也是 Pipeline 执行引擎所能调度的基本任务。
LibraDB 执行器架构演进
1. v1.0 Scatter-Gather模型
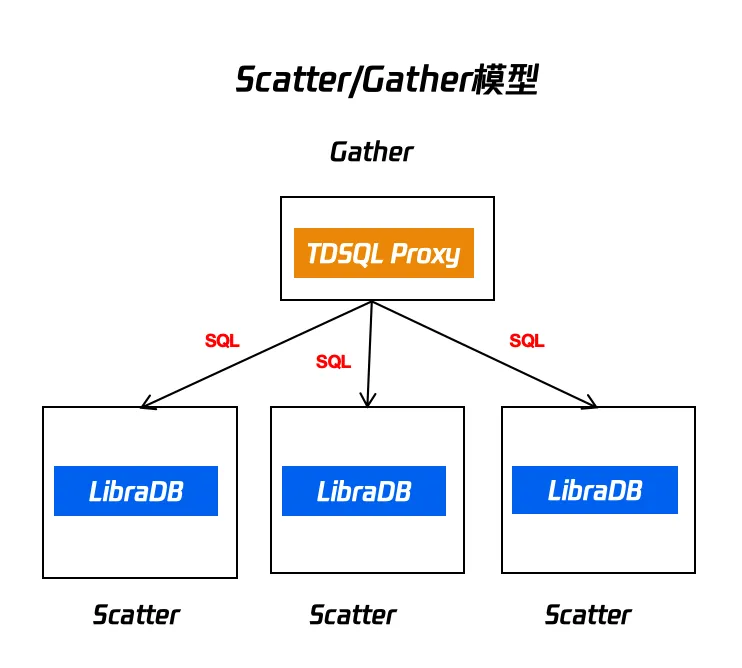
如上图所示,执行框架是一个简单的两阶段执行的框架(Scatther Gather模型),Scatther任务可以由多个节点(LibraDB)来进行计算,Gather任务只有一个节点(TDSQL 计算引擎)来进行计算。这里使用聚合计算举个例子如下所示
select l_orderkey from lineitem group by l_orderkey;
2. v2.0 MPP并行计算模型
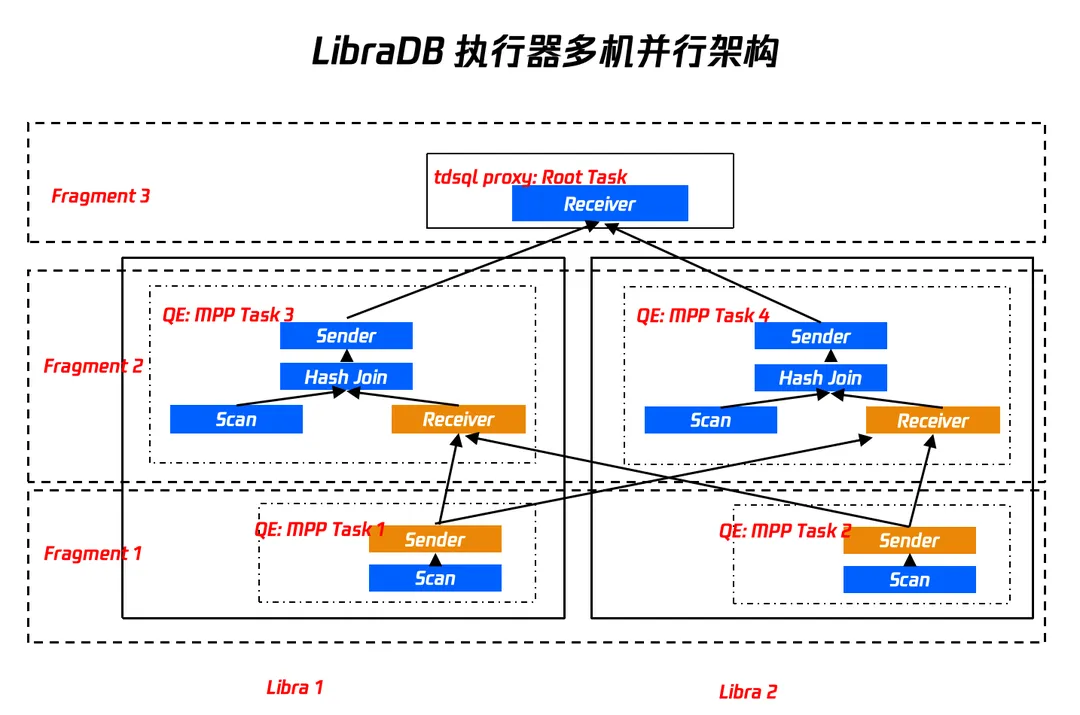
针对于 Scatther/Gather 模型无法应对复杂 SQL 场景下的性能问题,所以引入了`Sender算子`,`Receiver算子`,整个执行器架构调整成 MPP 的计算模型。TDSQL 计算引擎将用户 SQL 根据 RBO/CBO 拆分成若干个 MPP Task, 采用一次性(all-at-once)投递给 LibraDB , LibraDB 执行 MPP Task 然后返回执行结果。
select * from lineitem join orders on l_orderkey = o_orderkey;
3. v3.0 SMP PipeLine计算模型
多机并行场景的并行已经通过 MPP 的方案来优化处理了。但是单机场景如何把系统资源利用率提高,也是我们要思考的一个问题。在执行器v2.0版本执行器采用向量化火山模型的架构来实现的,如下图所示。
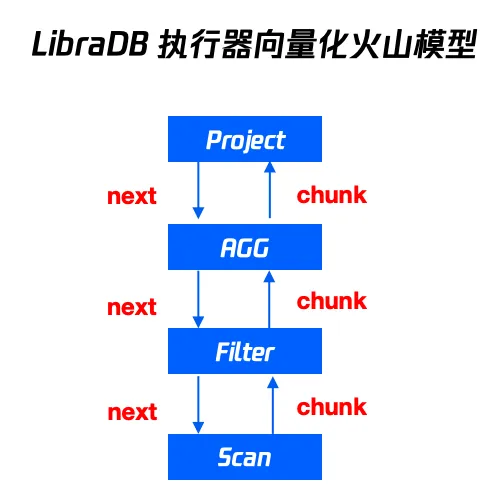
采用这种架构的优势在于:
1. 架构比较简单。
2. 因为数据是批量处理的,所以向量化计算应用的场景比较多。
但是这种架构的劣势也比较明显:
1. 调度不灵活,依赖系统调用,在数据倾斜场景不好处理。
2. 并行度不好控制。
3. 有虚函数调用的开销, context switch 比较高,cpu cache 命中率低。
4. 如果算子内部需要并行,只能自己开线程处理,对于执行器来说线程资源不可控。
PipeLine并行计算模型的设计
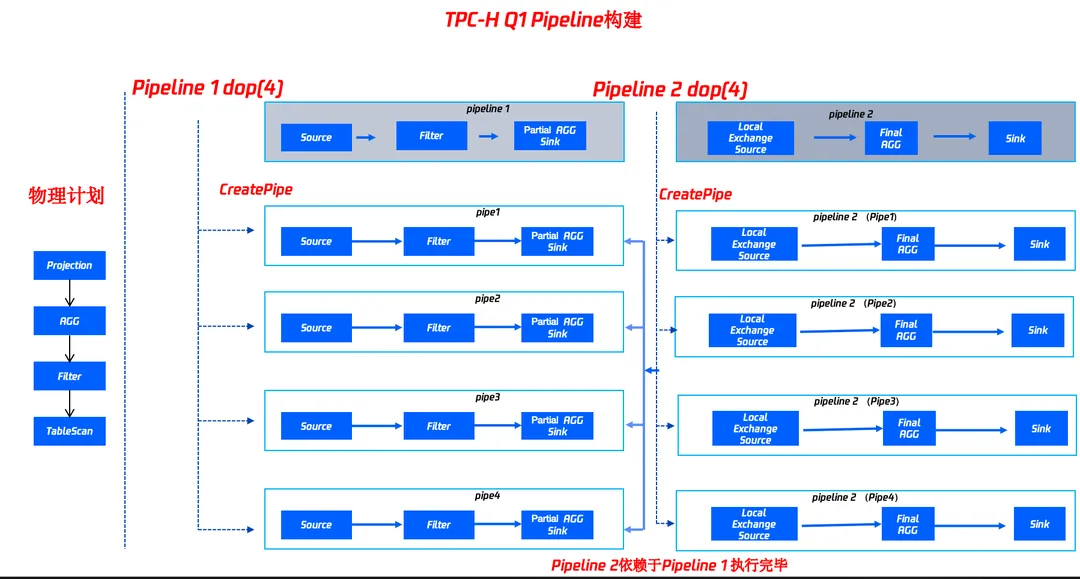
1. 基于物理计划构建Pipeline
我们以TPC-H语句中的Q1为例:
select
l_returnflag,
l_linestatus,
sum(l_quantity)as sum_qty,
sum(l_extendedprice)as sum_base_price,
sum(l_extendedprice *(1- l_discount))as sum_disc_price,
sum(l_extendedprice *(1- l_discount)*(1+ l_tax))as sum_charge,
avg(l_quantity)as avg_qty,
avg(l_extendedprice)as avg_price,
avg(l_discount)as avg_disc,
count(*)as count_order
from
lineitem
where
l_shipdate <= date_sub('1998-12-01',interval108day)
groupby
l_returnflag,
l_linestatus
这里假定节点的物理核心为4,LibraDB 物理执行器默认采用 CPU 物理核心数当做并行度(dop)来进行拆分 Pipeline。
2. 基于Pipeline构建执行图
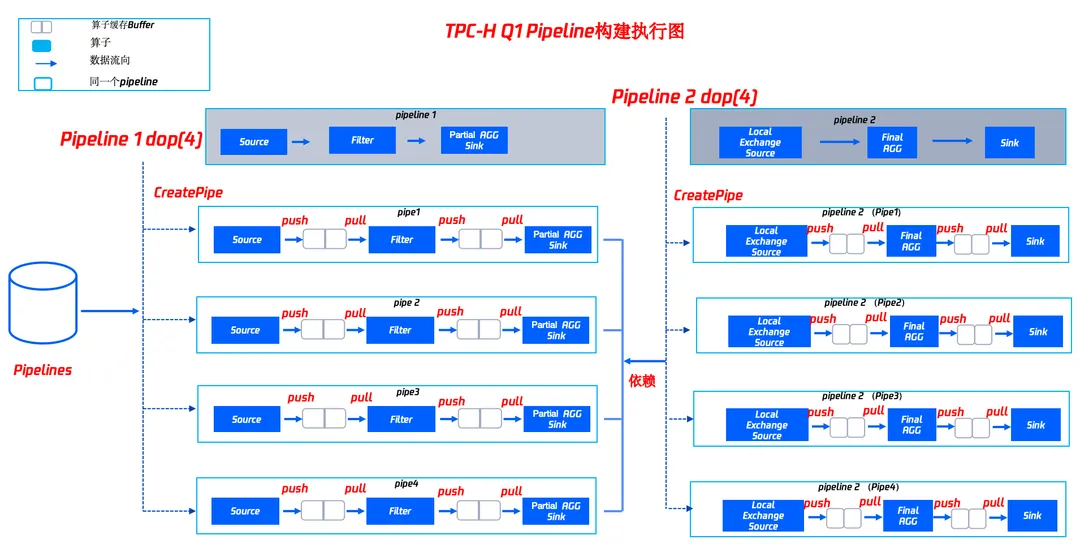
3. 基于Pipeline调度执行
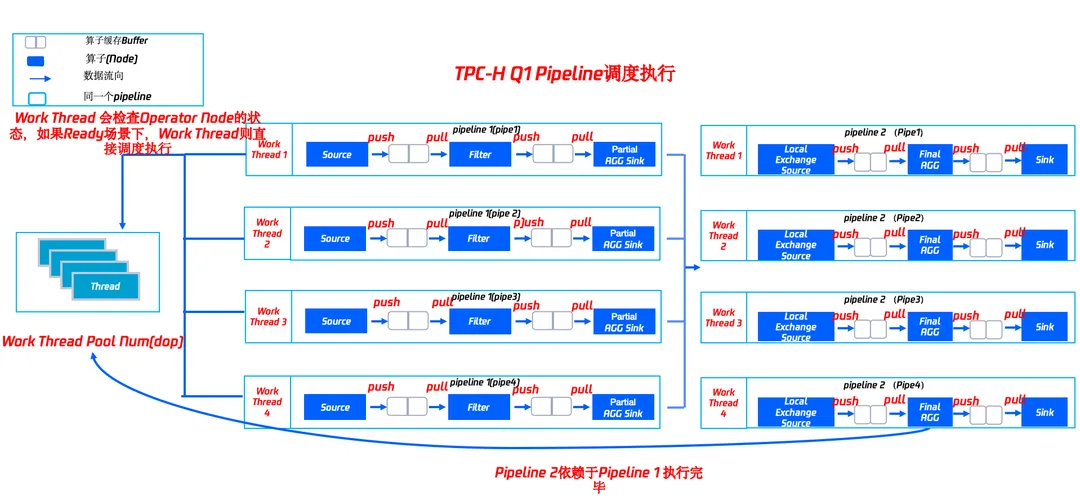
核心流程为:
● 每一个 Work 线程会检查算子 Node 的状态信息,当发现 Node 的状态信息为 Ready 的场景下,就调度当前 Node 进行计算,计算后的结果放到算子的缓存 Buffer 中。如果当前 Pipeline 的 Node 都没有 Ready 的情况下,则调度其他的 Pipeline 进行状态信息的判断和执行。
阻塞操作异步化
实现 Pipeline 执行引擎还有一个核心的功能就是阻塞操作异步化的优化,举个例子:
数据倾斜场景的调度优化
1. 执行线程的窃取能力(work-stealing)
在 Pipeline 执行的时候,每个 pipe 中的任务执行上可能出现各种情形的 skew,虽然在 pipeline 开始水平切分的时候尽可能将数据进行了平均切分,但是通过每个算子之后,剩余的数据可能不同,例如通过一个 filter 算子之后,pipeline 中的三个 pipe 之间的数据出现了极度不均衡,例如下面这种情况,第一个 pipe 的 filter 之后只有 1% 的数据,那么很快这个pipe 就计算完毕了。
pipe1: source1 -> filter -- selectity:1% ---> op2 ->
pipe2: source2 -> filter -- selectity:99% ---> op2 ->
pipe3: source3 -> filter -- selectity:50% ---> op2 ->
在这种情况下,pipe1 就可以尝试 steal pipe3 中的 task queue 中的任务来执行,不让每个 CPU 闲置,提高 CPU 的利用率。
2. Local Exchange数据打散能力
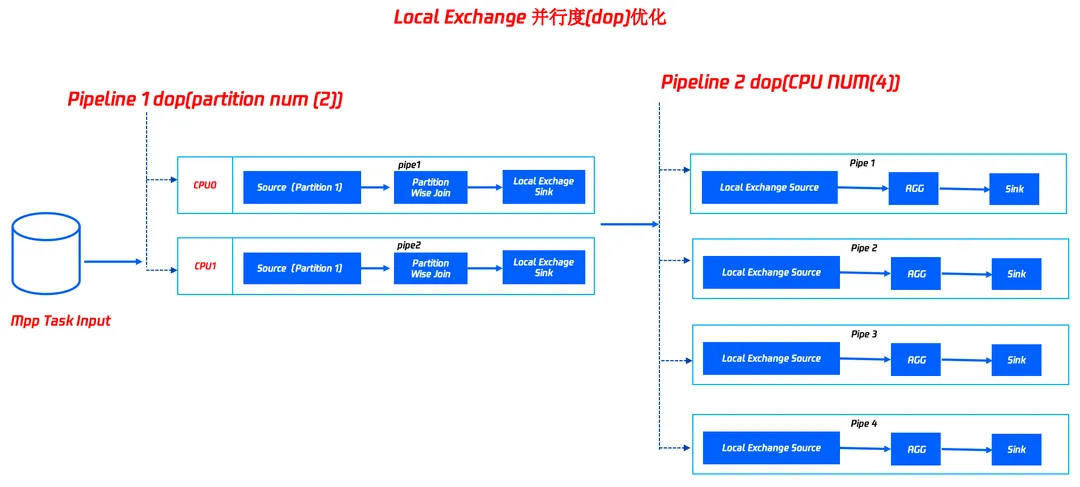
算子性能优化
1. AGG聚合算子的优化策略
我们还用TPC-H语句中的Q1来看下 LibraDB 关于聚合算子(AGG)层面的优化策略
select
l_returnflag,
l_linestatus,
sum(l_quantity)as sum_qty,
sum(l_extendedprice)as sum_base_price,
sum(l_extendedprice *(1- l_discount))as sum_disc_price,
sum(l_extendedprice *(1- l_discount)*(1+ l_tax))as sum_charge,
avg(l_quantity)as avg_qty,
avg(l_extendedprice)as avg_price,
avg(l_discount)as avg_disc,
count(*)as count_order
from
lineitem
where
l_shipdate <= date_sub('1998-12-01',interval108day)
groupby
l_returnflag,
l_linestatus
orderby
l_returnflag,
l_linestatus;
1.1 并行计算优化策略
1.1.1 线程级别并行优化
当 TDSQL 计算引擎产生分布式查询计划 (MPP Task)。物理执行器会使用 `MPP Task` 创建两阶段的 AGG 并行计算流程。
1.1.1.1 预聚合阶段并行优化策略
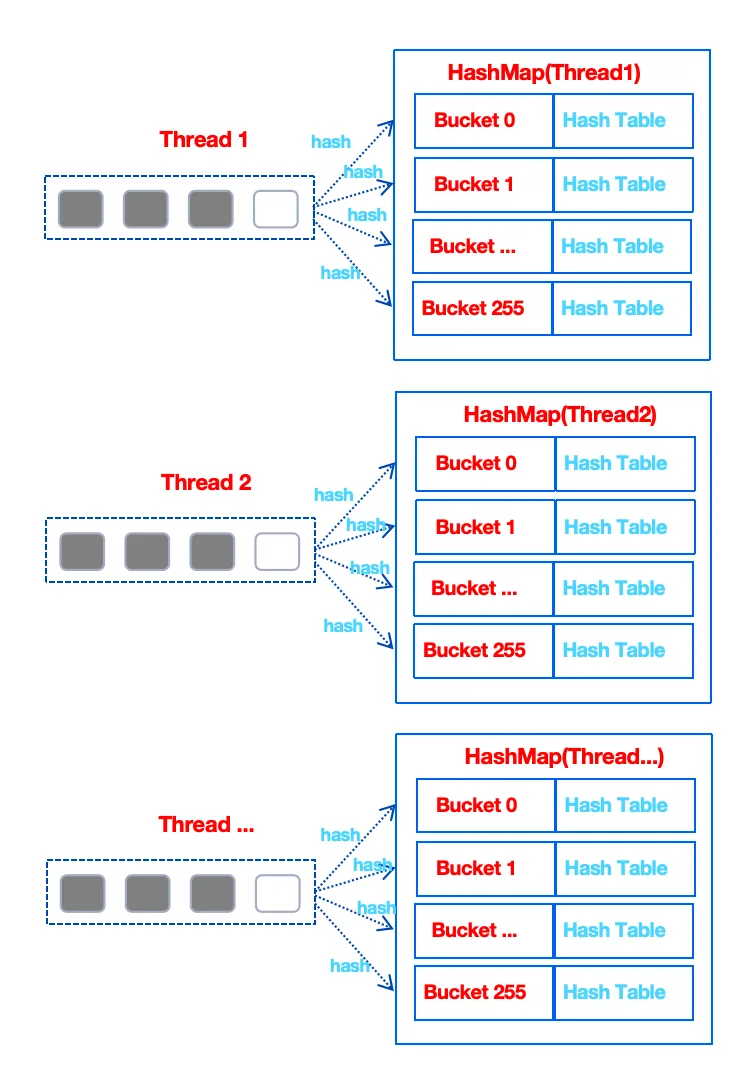
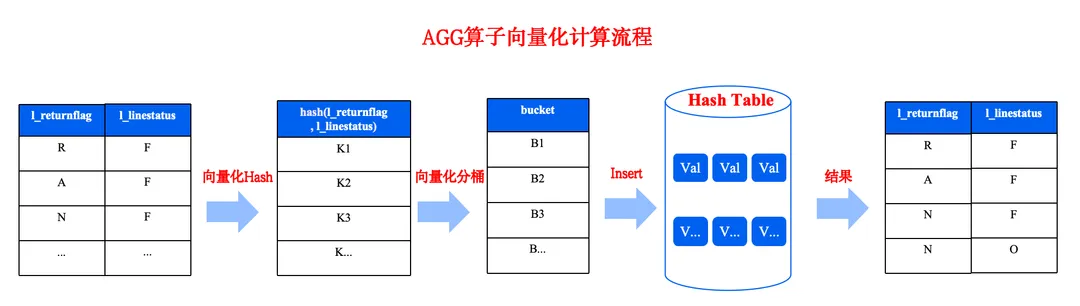
在聚合算法的预聚合阶段,会创建 CPU 核心数个 HashMap, 每一个 Work 线程持有各自的 HashMap。HashMap 包含256个 bucket,每一个 bucket 是一个子的哈希表。外部数据通过哈希的方式落到不同的 bucket 中进行聚合的预计算处理。这样每一个线程的 CPU 资源使用率都比较高。
1.1.1.2 Merge阶段并行优化策略
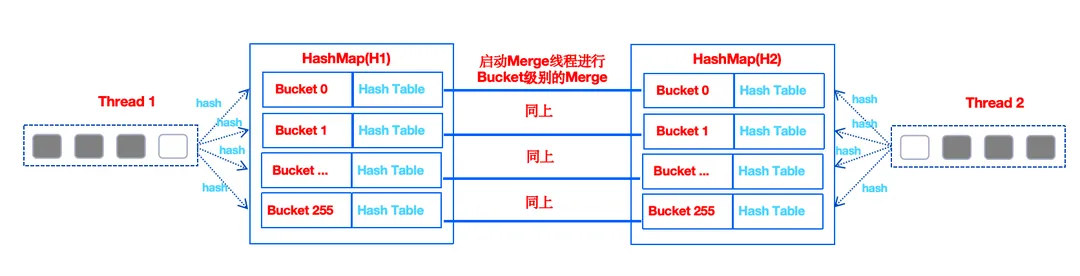
在聚合算法的 Merge 阶段,会启动 CPU 核心数个 Merge 线程,因为数据计算的哈希算法相同,并且 HashMap的Bucket 的个数也相同。所以每一个线程会把多个 HashMap 中相同 Bucket 的数据进行 Merge 操作,这样多个 HashMap 的 Bucket 也可以并行计算。这样系统资源的利用率会比较高。
1.1.2 数据级别并行优化
1.1.2.1 SIMD向量化优化
1.1.3 指令级别并行优化
1.1.3.1 Codegen JIT 优化
针对于聚合函数`Sum`、`Max`、`Min`、`AVG`等聚合函数场景,采用 Llvm JIT 的技术来提升执行性能。
1.2 哈希表优化策略
1.2.1 哈希表选择优化
根据 Group By Key 的数据类型、Null 值情况、单 GroupBy Key 场景或者复合 Group By Key 的场景设计出了60多种特定的 Hash 表。充分的利用CPU L1, L2, L3级别的 Cache 能力。从而提升算子的执行的性能。
1.2.2 哈希表Resize优化
LibraDB 采用的方式略有不同,基于计划的 FeedBack 的能力,计划会把算子预估要处理的行数传递给物理执行器,物理执行器接收到后,根据预估的行数来生成多大的哈希表,从而避免了大量的 Memory Copy。
1.2.3 单层哈希表转化成二层哈希表
1.2.4 Prefetch优化
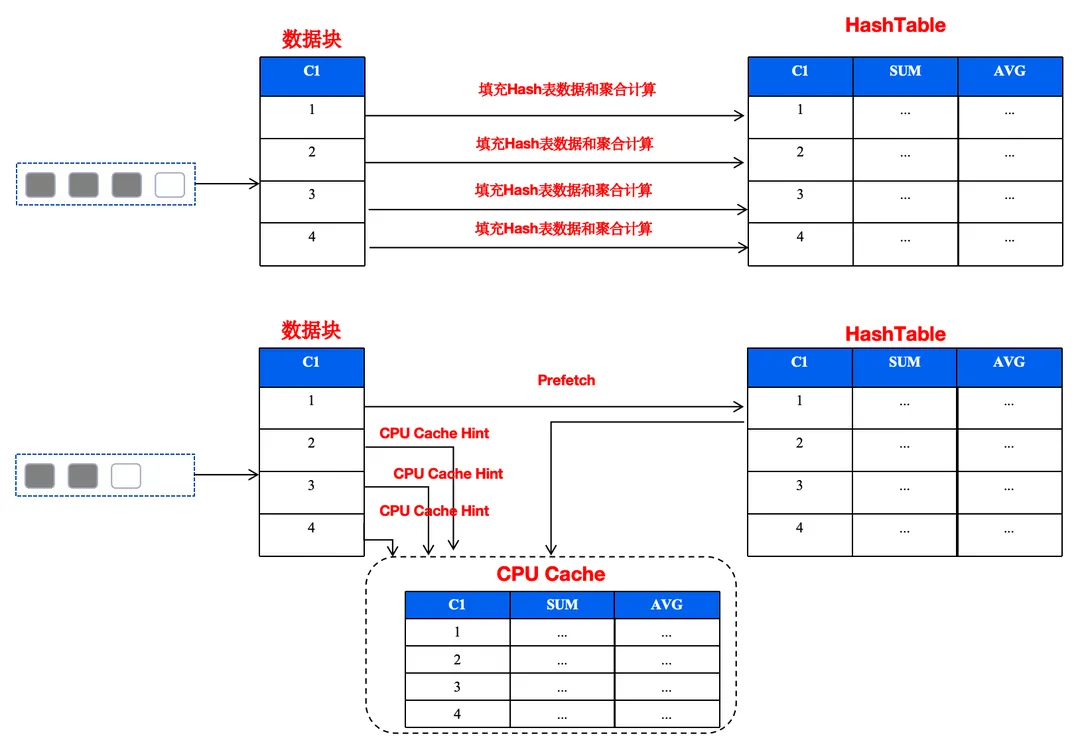
针对于哈希表中元素比较多的场景下,我们利用 Prefetch 优化 Cache Miss 的的场景,因为 Prefetch 的时机和距离比较难把握目前我们通过配置参数的方式来进行调整。每次读取哈希表数据的时候,通过预读一部分数据放到 CPU Cache 里面,如果后面的数据命中了 CPU Cache 的场景大大的优化了 CPU Cache Miss 的场景。
2. Join关联算子的优化策略
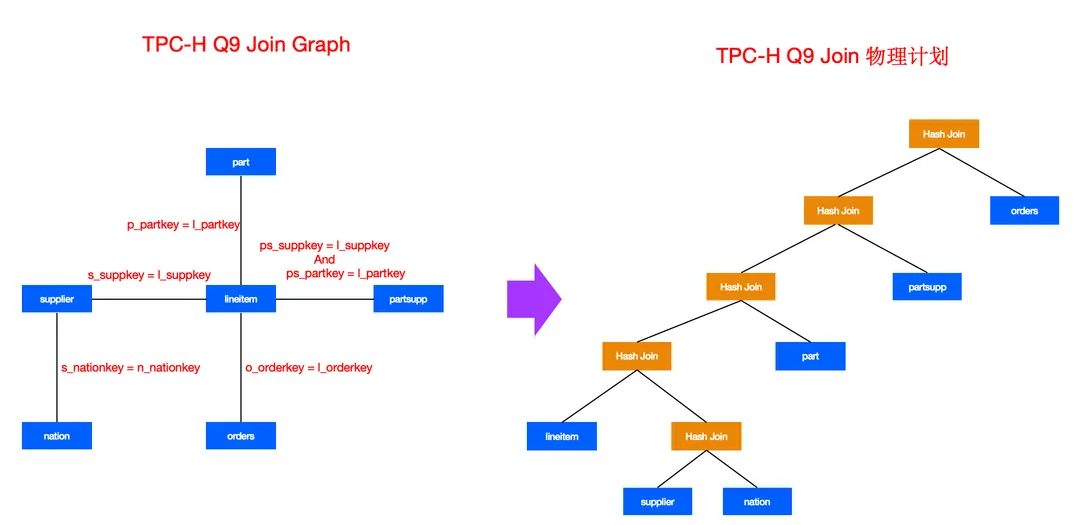
我们还用TPC-H语句中的Q9来看下 Libra 关于关联算子(Join)层面的优化策略
SELECT
nation,
o_year,
sum(amount)AS sum_profit
FROM
(
SELECT
n_name AS nation,
toYear(o_orderdate)AS o_year,
(l_extendedprice *(1- l_discount))-(ps_supplycost * l_quantity)AS amount
FROM part, supplier, lineitem, partsupp, orders, nation
WHERE(s_suppkey = l_suppkey)AND(ps_suppkey = l_suppkey)AND(ps_partkey = l_partkey)AND(p_partkey = l_partkey)AND(o_orderkey = l_orderkey)AND(s_nationkey = n_nationkey)AND(p_name LIKE'%dim%')
)AS profit
GROUP BY
nation,
o_year
ORDER BY
nation ASC,
o_year DESC
TPC-H Q9 中,包含关联运算、聚合运算、排序运算。但是针对于整个 SQL 而言耗时比较重的点还是在多表关联的运算上面, 所以聚合运算和排序运算, 不是我们主要考虑的优化。下面针对于关联运算的优化策略进行描述。
2.1 join 顺序优化
2.2 并行计算优化策略
2.2.1 线程级别并行优化
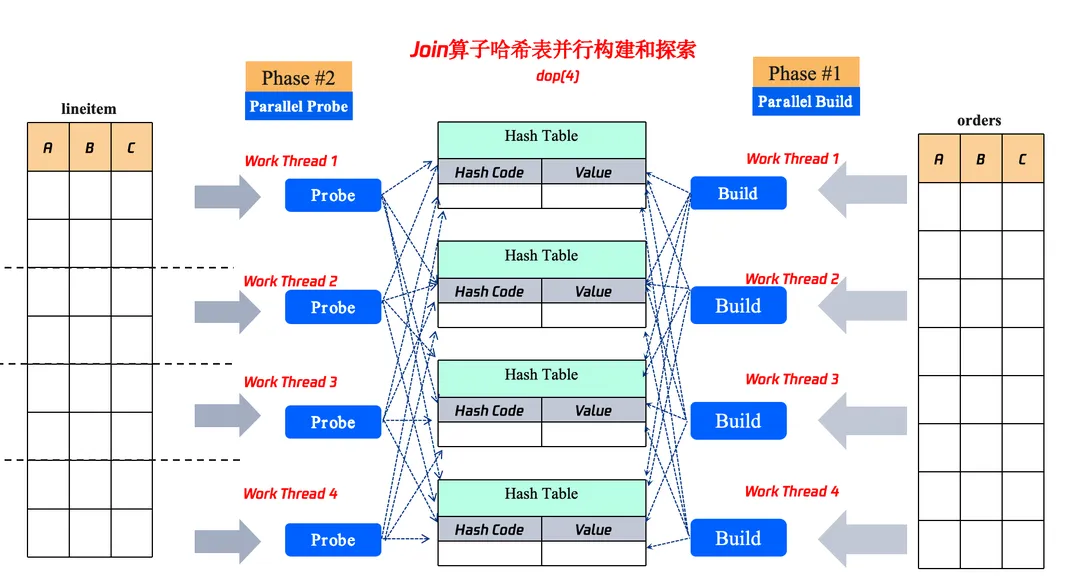
2.2.1.1 Fragment内部多个Join算子哈表表并行构建
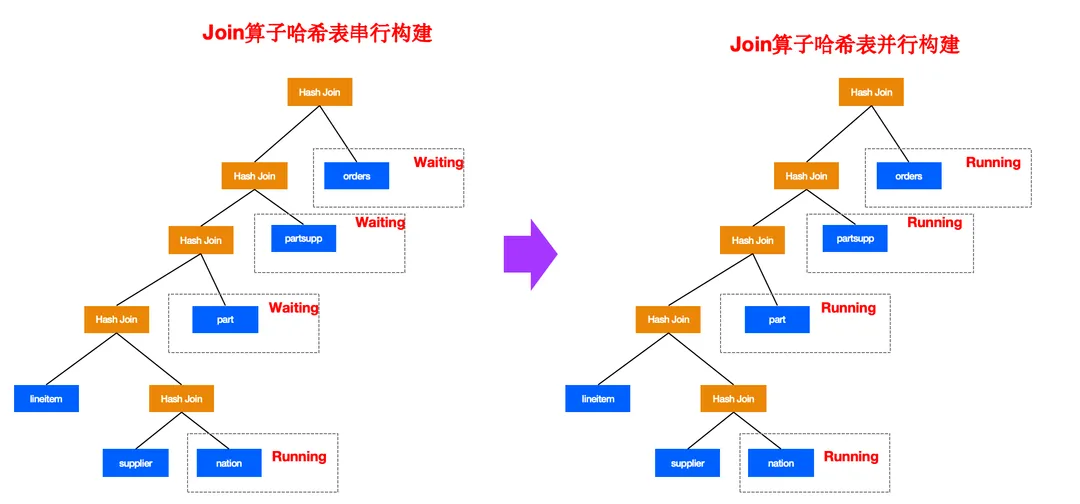
传统的数据库当处理多个 Join 的场景下,哈希表都是串行构建的如上图所示,例如 Clickhouse 等。这种计算模型会导致系统资源利用不充足。例如当 nation 表构建哈希表的时候,part、partsupp、orders 表都是没有计算的状态,但是这时这些表如果能够提前进行数据的扫描,这时系统的CPU资源和I/O资源都能充分的利用起来,从而整体的提升性能。
这面做还有个好处,例如如果 part, partsupp、orders 是 Receiver 算子的情况下,也能把下层计划的资源充分的利用起来。
物理执行器采用二阶段执行的方式,第一阶段提前使用 Work 线程并行构建哈希表的数据,让下层的计划物理资源利用率充分的利用起来。第二阶段再进行多个 Join probe 操作。
2.2.1.2 Join算子并行计算优化
针对于单个 Join 算子,物理执行器这里也是采用并行的方案来进行计算的。举个例子
select*from lineitem join orders on l_orderkey = o_orderkey;
2.2.2 数据级别并行优化
2.2.2.1 Join算子向量化优化
和聚合算子类似,也是在批量计算数据的 Hash 值和桶数的时候采用了 SIMD 技术来进行优化处理。
2.3 哈希表优化策略
2.3.1 哈希表选择优化
2.4 Runtime Filter 优化
减少算法输入规模也能很大程度提升性能。如果能够用很小的代价降输入规模,比如规模减少为十分之一,对于线性复杂度算法,大约能提升十倍。Runtime Filter 正是这个思想的体现。
SELECTsum(l_extendedprice)/7.AS avg_yearly
FROM lineitem, part
WHERE(p_partkey = l_partkey)AND(p_brand ='Brand#44')AND(p_container ='WRAP PKG')AND(l_quantity <(
SELECT0.2*avg(l_quantity)
FROM lineitem
WHERE l_partkey = p_partkey
))
布隆过滤器的特点并不完全等价于数据库中的谓词过滤,但是也能去除相当比例的无用数据。以 Q17 为例,输出结果集是原数据集的 1/80,整个查询性能提升了 8 倍。
结论
LibraDB 的执行器在执行性能方面做了很多的努力。执行器这里要考虑充分的利用集群的资源,实现多机场景下的并行计算,也要考虑在单机场景下,设计高性能的执行框架,例如使用异步化、灵活调度、SIMD、Runtime Filter、延迟物化、Encoding等等。充分利用单机多核的CPU、内存、网络、I/O,让资源利用率最大化。
未来分享
1. 资源管理相关,针对于高并发场景、CPU 资源控制、内存资源管控、线程资源控制、Query 的优先级队列、算子外存能力等功能。
2. 算子性能相关,例如有序数据的算子(Stream AGG算子,Stream Join)等。Adaptive Window Function、Adaptive AGG算子等。
3. Mysql 生态的兼容。
4. 平台相关优化,针对于 ARM , 海光等国产化平台进行优化。
5. 列存事务的支持。
﹀
﹀
﹀

大会速递丨腾讯云智能融合 AI+数据,重塑数据管理新范式

技术干货丨 TDSQL for MySQL DDL执行框架

分布式数据库时代,需要什么样的产品?
