





余成真
微盟 数据库高级技术专家
有多年的数据库产品管理和技术规划经验,目前负责微盟数据库团队管理及建设、数据库相关的业务保障、数据库技术决策;在微盟工作经历中主导海量实例跨 IDC 迁移、自建集群到云数据库迁移等迁移工作;组建并带领团队完成数据库产品从 0 到 1,从 1 到 N 的跨越;深度参与同城双活/异地多活数据库整体架构及数据同步方案的设计及实施。
在当下的互联网业务领域,敏态这个术语的曝光度日益增多。对于数据库而言,敏态场景往往与全链路压测等主题密切相关。在 2022 年第三期 DBTalk 技术公开课中,微盟数据库负责人余成真带来了主题为《在敏态业务场景中,微盟数据库的应用实践之路》的分享,阐述了微盟数据库应对敏态场景的实践经验。
介绍
本次分享主要阐述敏态业务场景下全链路压测数据库层做的数据能力和平台功能。敏态的关键词是敏捷和改变。如何理解敏态?比如说业务可以随时无感知地扩缩容,以适应时间和空间的要求,技术上目前主要表现为微服务化和可扩展的数据库。敏态在企业级 SaaS 的重要考量指标之一,是持续创新的能力。这种以技术和管理为导向的技术创新,传导到后端的数据库更需要具备持续变更的能力。
主流敏态场景包括微服务化、低代码和分布式的版本控制 Git,还有分布式数据库、全链路压测系统。因为全链路是一个系统化的工程,它有很多组件、DB 和服务组成一个全功能的产品。全链路业务系统的支撑重点之一就是数据的变化。
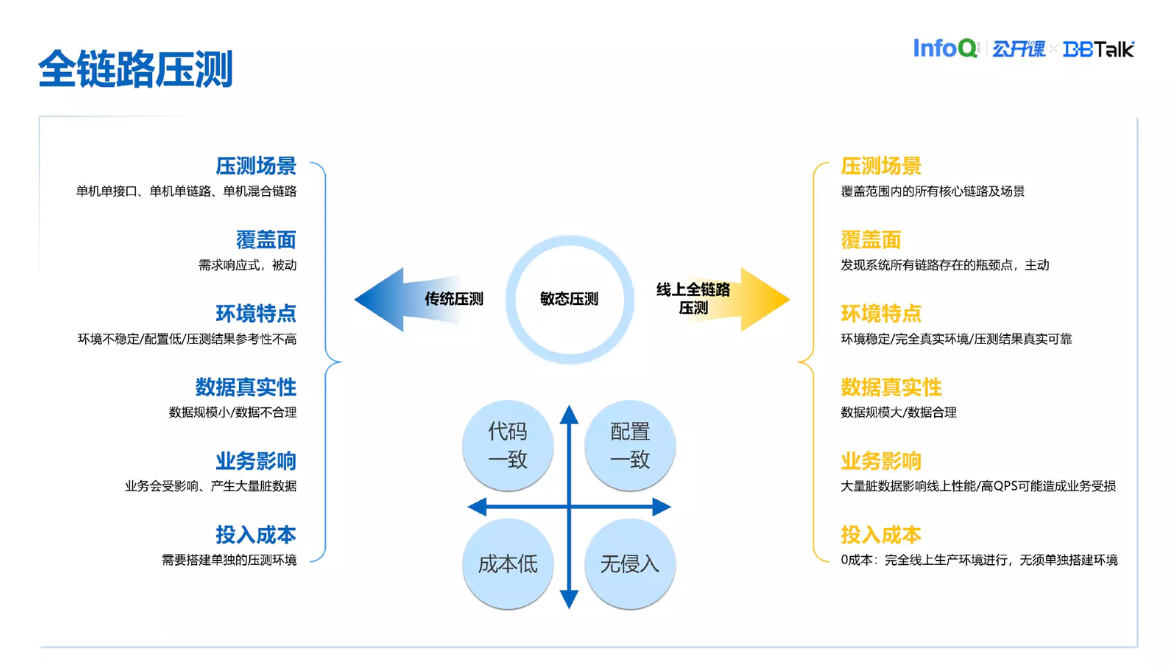
对比传统压测和线上全链路压测,传统压测的好处是业务影响非常低,环境非常独立,投入的成本是可控的。线上的全链路压测有很多实现方式,可能会影响业务,数据比传统压测更真实,覆盖面非常广。

以上是微盟全链路压测系统的方案、考虑因素和收益介绍。微盟要解决一些真实性问题,比如说业务侵入性问题,数据隔离问题。所以微盟的性能测试团队通过多种方案的对比尝试,并结合长期实际工作中的测试能力建设,演变出敏态业务场景下全链路压测的可落地平台。当前我们采用的是克隆环境的方式,它是在传统的压测基础上做了一些敏捷性的改造来实现的一套系统。这种克隆的方式是在一个独立的专用 ABC 网段搭建出来的,跟线上完全隔离,业务也不需要任何改造,数据也能够保持真实性。
我们的平台具有最小粒度和按需部署的能力,能够大大降低硬件成本。比如说业务在发布过程中深度耦合一个 CICD 的开发平台,同时也耦合数据库的管理平台。我们可以将这种应用级别的模块打包,然后一键克隆部署。数据库也同样有应用数据库实例一键部署、数据迁移同步、一键升降配功能。因为我们按需做数据迁移,所以能够保证压测环境下数据的真实性要求。同时因为压测需求对于实时性要求不高,一般压测团队做计划的时候可能会有一天、几个小时的时间,完全够我们做应用、DB 的部署迁移。
总结下来,我们用了极低的硬件成本,并且可以保证压测的真实性,同时保障了业务流量和数据隔离,对于业务是没有侵入的。
实践过程中我们全链路压测可以在 12 小时之内部署多达 300 套应用,数据库超过 200 套实例,可以满足敏捷测试的要求。
全链路压测依赖两个平台,一个是开发平台,就是前面讲的应用发布平台;同时也依赖数据库的管理平台。做计划的时候我们会把所有的应用打包成模块的形式,同时也会做一些模块级别的 KPS 计划。下面从资源部署、数据能力、灵活集成和动态扩展四个维度阐述微盟全链路压测数据库侧的建设和应用。
实践
我们的产品线在部署计划周期内做一些低配操作的部署,然后计划外会自动做数据库资源的销毁,同时也支持按需申请高配。我们在一些重要活动也会做 Online 同等配置的申请和升配,压测周期结束之后会有自动降配的任务去降低成本。
域名是依托微盟的 DNS 系统,根据线上的域名实现 1:1 域名的构建和销毁,能够自动实现全链路环境域名注册和域名合并。
数据库本身的账密是一键迁移同步到压测环境,数据都会同步过去。同时我们也做了一些内部的免密改造,免密应用会自动同步到压测环境,实现自动密码填充功能。这边也会有明文的业务测试账号密码,供一些研发和测试脚本使用。
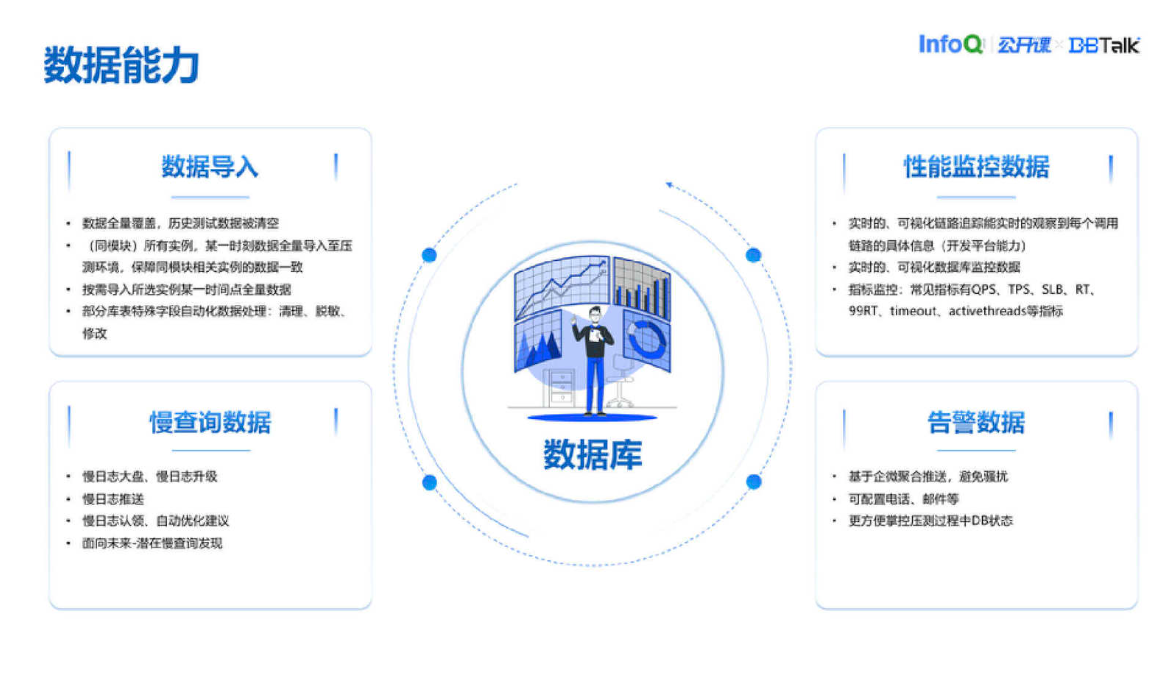
以上是我们的数据能力。根据全链路系统对于数据平台能力的要求,我们构建了数据库平台的架构。我们也分三个区,管理区、任务区、组件区。管理区就是常见的功能,如权限、扩缩容、SQL 工单、SQL 优化。任务区做了任务编排和状态协调、任务调度。组件区有很多日志服务、部署服务、监控报警服务、备份还原服务、自定义脚本命令服务。这个平台的业务挑战主要是数据一致性的挑战,比如说相同模块所有实例数据怎么保证一致;任务创建、状态检查、数据同步等子任务怎么做协调机制;数据批量处理过程中怎么最大速度做数据落地、修改,这是平台建设过程中遇到的一些业务挑战。

比如说我们要对域名操作,要生成一个任务表,基于任务表做资源的购买创建、状态的查询。资源已经存在的情况下,我们要做数据迁移的任务,同时还要做数据初始化工作,这些任务完成之后还要保证数据的一致性。这边是通过 DTS 迁移任务,通过异步的瞬间完成,把 DTS 任务终止掉,保证数据的一致性。一般情况下我们 200 多套实例,基本上可以在 1 分钟之内全部完成。这个数据的差异可能在 1 分钟之内,也就是秒级别的,通常情况下秒级别的数据可以完全满足压测数据一致性要求。
我们是用 Celery 做链接组和子任务。同时我们引入了状态机 Transitions,要根据购买状态决定下一步操作,构建子任务。我们在数据处理的过程中也引入多线程和队列技术。
在平台上,我们可以对全链路做告警推送、监控展示,也会做慢日志的全链路项目推送,它跟线上是隔离的。同时我们也有平台做一键化的部署。

灵活集成有三个要点,第一是资源回收,我们这边是叫测试计划。它结束的时候有自动回收的机制。比如说双十一有一个大的计划,我们会把双十一涉及到的资源应用模块做框定,然后做起始和终止时间。终止时间结束之后会自动触发资源回收功能。同时在测试的周期外,比如说我们计划是一个月,那么第一周期间可能我在测试商品,测试商品过程中可能也会升配。我们会在周期外对于升配过的资源做自动降配的任务。
另外我们也可以支持各种局部压测,特别是无依赖服务的,调用关系简单的服务。它都是基于应用去选择应用对应的资源做创建和导入。同时也支持全链路级别的模块级别的链条压测。
灵活集成里比较有亮点的一个组件是 SQL 性能压测组件。这也是线上的一个组件,集成这个组件的目的是为了定位性能的卡口。比如我们在压测业务接口的时候,发现业务接口压不起来,我们可以把业务对应的 SQL 语句通过压测组件做 SQL 级别的性能压测,来比对 SQL 的 QBS 和接口 QBS 的差异。同时基于这种接口在压测环境做一些 SQL 的性能压测,可以发现一些潜在的慢查询。
我们的全链路 SQL 压测组件也是花了很多心思,比如说集群添加,服务器添加、任务创建,包括压测之后每一个 SQL 语句的性能报表,可以很清楚地看到每一个接口或者是每一套 SQL 语句在不同时间段内压测数据的性能数据。
动态扩展方面,我们拉取了我们这边的数据,测试周期外我们数据库自动扩容的任务达到了 60 多,基于测试需求主动扩容的数据有 200 多次。数据库侧主要是对 CPU 和内存升配,跟线上配置做对齐任务。自动创建店铺数据达到 23 次,最多的商铺的数据量超过 7 亿次,所有的数据在非常短的时间内都能够完成。
展望
对于未来的展望,首先我们想到的是成本问题。

我们要做的一个展望是数据能力的加强。我们想要更好的数据能力、更强的数据清洗能力。因为现在我们的清洗分两块,一块是计划外的,数据全量删除,还有一些实例需要保留一些压测的数据。我们不仅仅需要数据的全量清除,更需要的是数据的清理能力。数据克隆能力未来也需要,目前只是少部分的实例或者是模块的克隆,后续可能想要做更多的这种实例,比如说活动营销的数据克隆能力。
