





刘畅
腾讯云 数据库高级工程师
目前参与分布式 TDSQL 数据库开发,专注于数据存储方向,研究领域为分布式事务、数据一致性、数据分片等。
TDSQL 作为国产分布式数据库中的佼佼者,其在各个应用场景中都有着很好的表现,获得了用户的认可与好评。TDSQL 取得今天的成绩也绝非易事,其背后是腾讯云数据库团队的多年努力和持续技术演进。
在 2022 年第三期 DBTalk 技术公开课中,腾讯云数据库高级工程师刘畅带来了主题为《TDSQL 破局敏态业务背后的技术演进》的分享,探讨了敏态场景下 TDSQL 的成长实践。
敏态业务场景一般具有不可预知性。有时业务的数据规模可能会不断扩大,这时就需要对集群扩容。但业务的读写操作可能会集中在某一段数据上,其他范围的数据相对空闲,导致少部分节点承担整个集群大部分的压力,这种情况下也需要做负载均衡。类似双十一的场景中,数据库压力可能在一段时间内猛增,需要及时让数据库调度,把压力分摊到其他节点。这种业务的不确定性就是一种敏态,如果数据库没有很好地应对敏态业务场景,可能导致读写比较缓慢,或者让整个服务不可用。
应对敏态业务场景的传统做法是需要人工介入,比如人工分表。但这种方法未必可以兼容所有数据库,另外需要用户自己预判数据热点,可能不够灵活。同时一些扩容场景需要 DBA 发起,可能会中断业务执行。最后,人工扩容对双十一这种场景也不一定能及时处理。
因此数据库最好具备自动应对敏态业务的能力,尽可能解放人力,让用户像使用单机数据库一样使用分布式数据库。
TDSQL 架构介绍
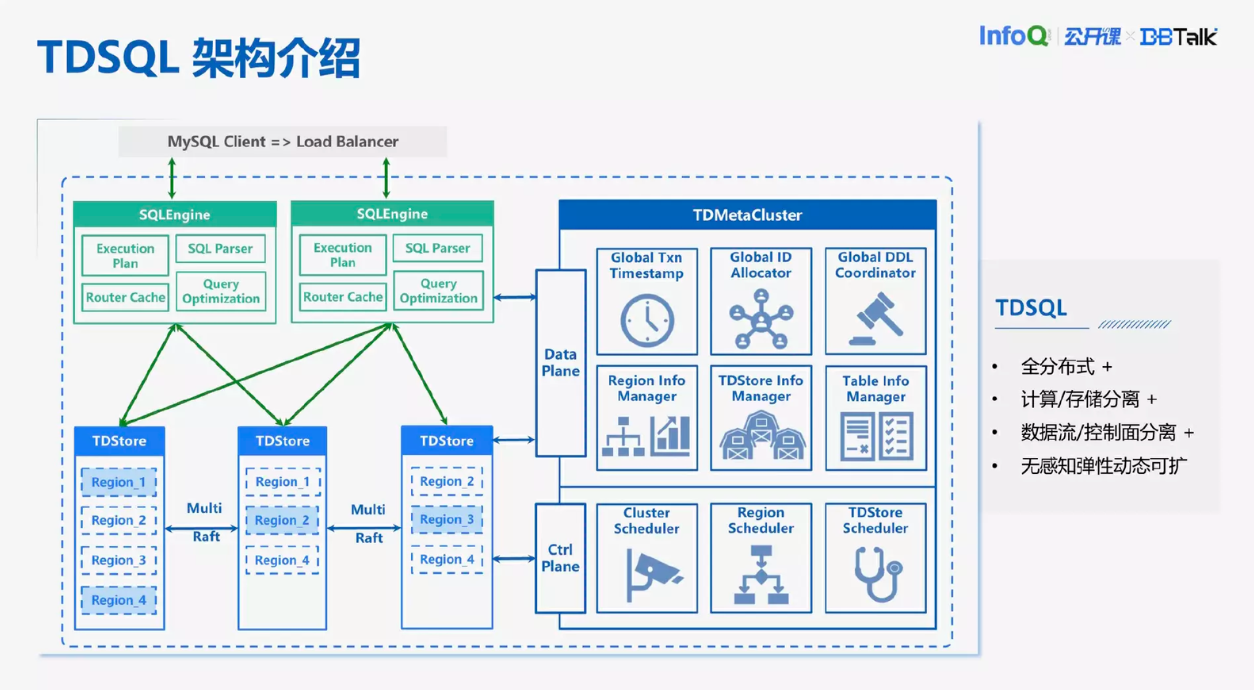
TDSQL 是全分布式,存算分离的数据库,由三个模块构成。最上面是 SQLEngine,是一个计算节点,它的目的是将 SQL 语句转化为 KV 请求,然后发送给存储集群。它会做一些查询优化和 onlineDBL 的功能。下面是 TDStore,是存储的一个分布式集群。然后它是一个 KV 的存储模块,用来接收 KV 请求。TDStore 做了数据分片,把整个范围的数据划分成各个连续的 Region,每一个 Region 是一个独立的 Raft,Raft 中每一个副本打散在不同的 TDStore 上,这样就实现了比较初步的负载均衡。
同时 TDStore 提供了分布式事务的下沉,保证分布式事务提交的原子性。右边的模块是全局的元数据管理模块 MC,提供全局递增的时间戳管理、全局资源调度。比如说发现某一个 TDStore 压力比较大,它会向 TDStore 下发调度任务,把一部分压力均衡给另外一些压力不怎么大的 TDStore 节点。对敏态业务的支持是离不开 MC 的帮助的。
TDSQL 应对敏态业务的基本原理:Region 调度的类型与流程
接下来简单介绍 Region 的调度原理。TDStore 目前的调度分为分裂、迁移和切主三种。每一个 TDStore 包含的 Region 数量是有差异的。因为它是向 Region 的 Leader 副本下发读写请求,所以这个 Region 的 Leader 副本比 Follower 承担更多的压力。所以我们可以得出一个初步结论,如果我们观察到一个 TDStore 节点包含了比较多的 Region 副本数,或者是它上面的 Leader 副本比较多,说明这个 TDStore 就承担了比较多的压力。
比如四个 TDStore 构成的一个存储集群,其中包括三个 Region,Region3 比较大,上面的数据比较多,读写比较频繁,它就是一个热点 Region。对于热点的 Region3 而言,它的 Leader 所在的 TDStore4 节点压力要更多一些。同时 TDStore1 有三个副本,其他的 TDStore 都只负责两个副本,所以 TDStore1 压力也比较大。最终我们想达到一个目的是把 TDStore1 和 TDStore4 的压力转移到压力比较小的 TDStore1 和 TDStore2 上面。
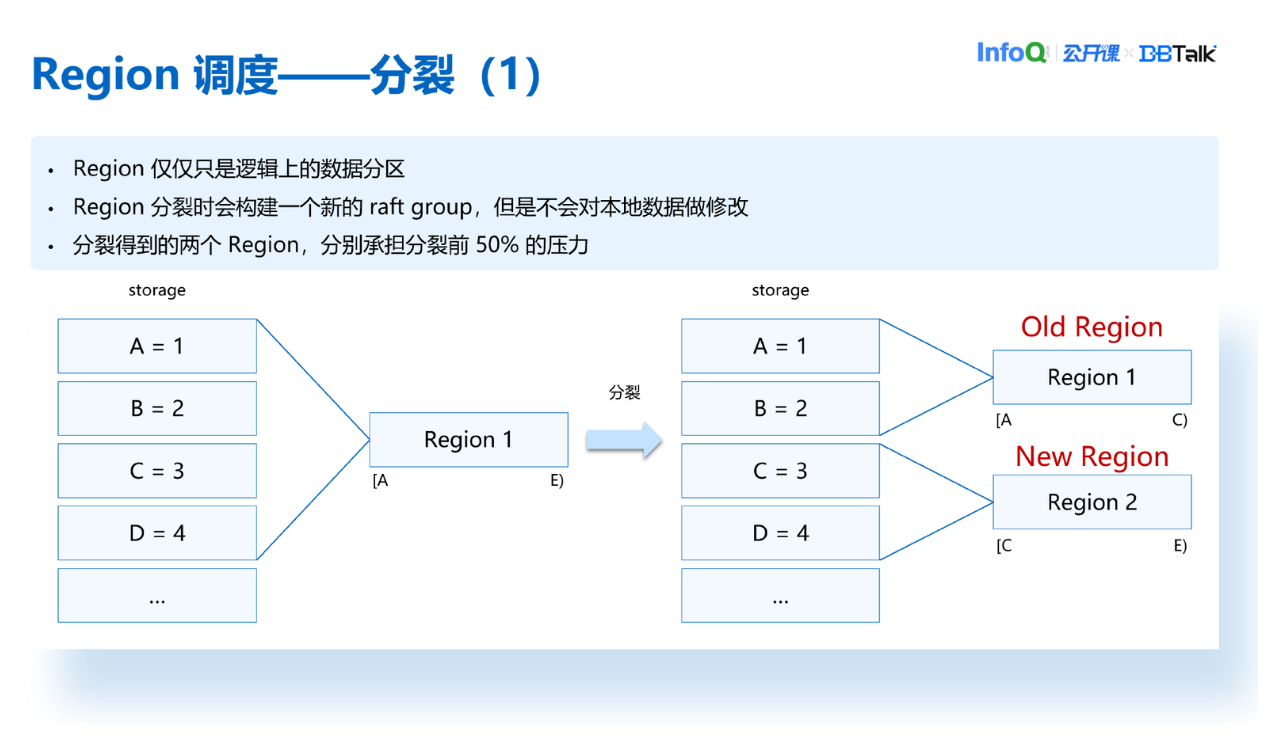
我们看一下 Region 分裂的原理。首先 Region 仅仅是一个逻辑数据分区,比如说一开始 Region1 范围是 A 到 E,包含了 ABCD 四个数据。它经过分裂之后,底层的 ABCD 这四个数据是没有变动的。唯一变动的只是它新增了一个新的 Region2,原来的 Region1 称为 Old Region,新产生的这个 Region 称为 New Region。可以看到 Region1 范围变成了 A 到 C,包含的数据是 A 和 B。Region2 的范围是 C 到 E,管理的数据是 C 跟 D,也就是说经过分裂之后得到的两个 Region 分别承担的是分裂之前的 Region 的 50%的压力。这样可以把压力比较大的 Region 分裂成两个新 Region,压力得到了分担。
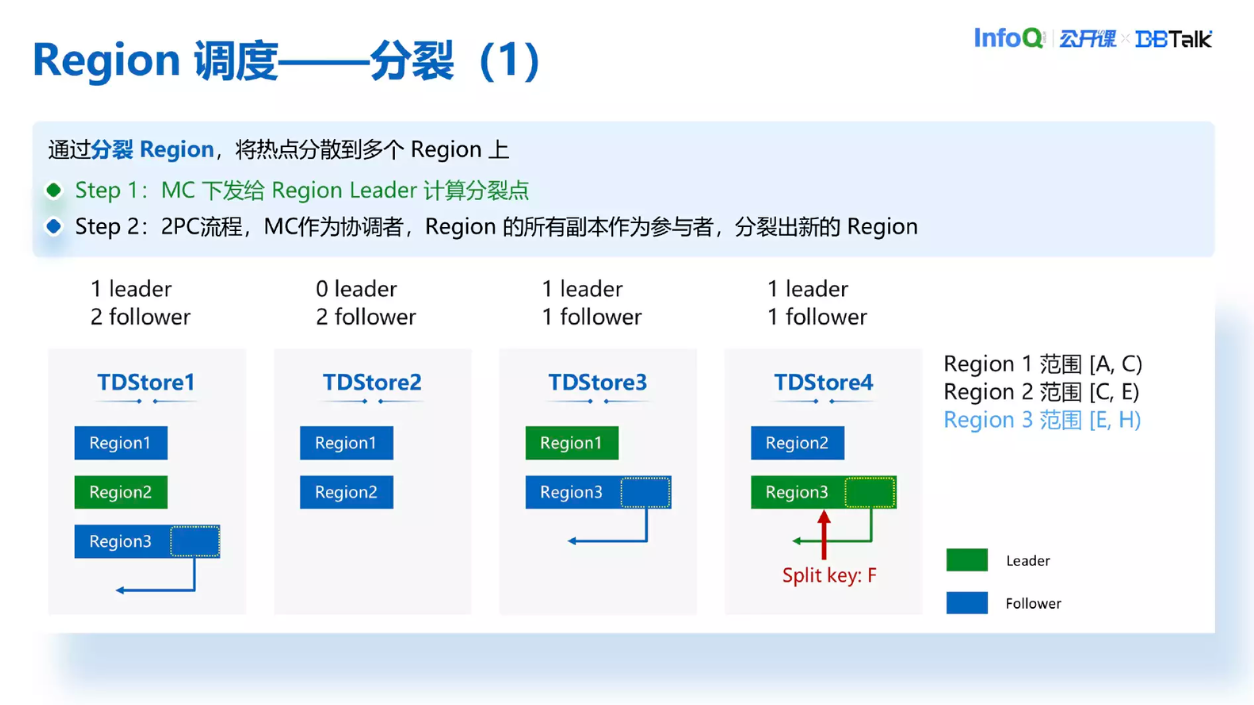
我们要触发分裂的时候,MC 会向 Region 的 Leader 下发一个计算分裂点的任务,Leader 通过二分法找到整个 Region 范围内的数据中间点的 Key,然后把这个 Key 返回给 MC。MC 收到之后会重新向每一个 Region 的副本下发一个分裂任务。当 TDStore 收到这个分裂任务后会在 TDStore 上产生一个 Region4,相当于 Region3 的数据范围变小了,把后面一部分的 Region 范围单独拆分出一个 Region4。这样看来 Region 的热点没有了,但 TDStore 的压力没有太大变化。比如说 TDStore4,它现在变成了有两个 Leader 一个副本的节点,而 TDStore1 更是承担了 4 个副本的压力。所以下一步的目的是把 TDStore1 和 TDStore4 的压力去均衡到 TDStore2 上面。

我们通过 Region 迁移去分担一部分 TDStore1 的压力。MC 会向要迁移目标的节点,也就是 TDStore2 添加一个副本任务,然后 TDStore2 收到之后会创建一个 Region4 副本,短时间内 Region4 从 3 副本变成了 4 副本。然后 MC 会向 TDStore1 下发一个销毁副本任务,这样 TDStore1 的 Region4 就销毁掉了,Region4 的副本数又回到了 3 个。这样一套操作下来 TDStore1 变成了一个 Leader 跟两个 Follower,压力会降低很多。
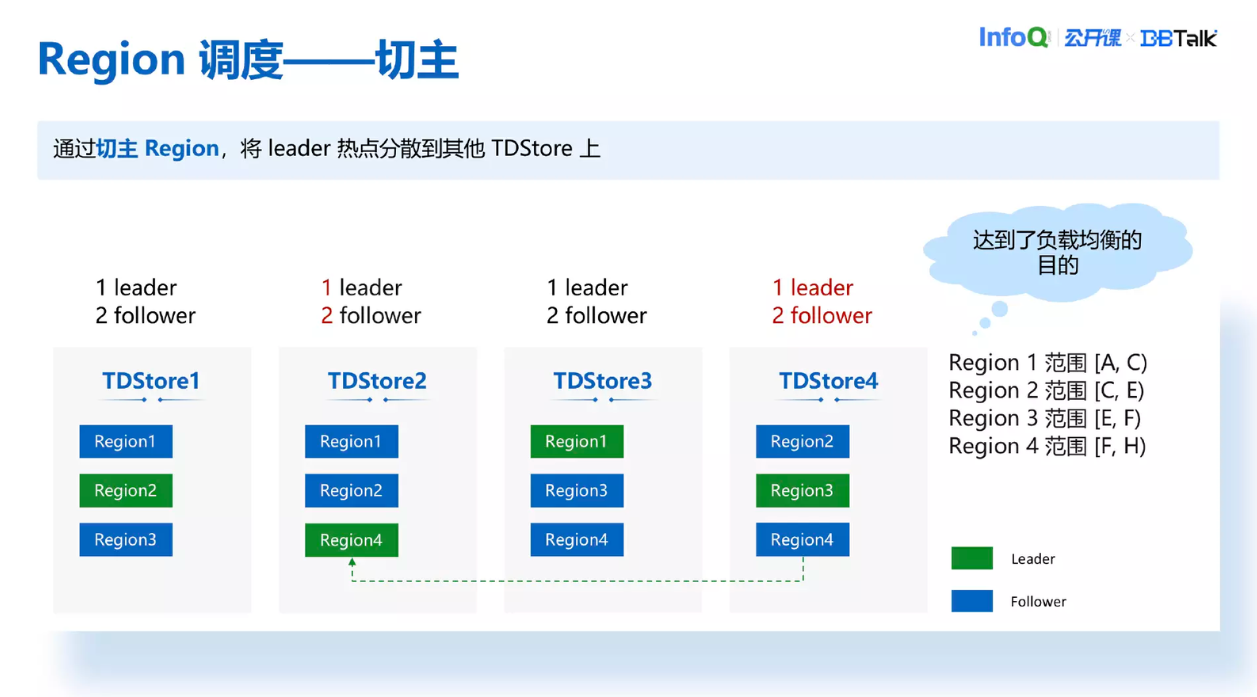
下一步我们通过切主的方式把 TDStore4 的 Leader 切到 TDStore2 上面,这样所有的 TDStore 都变成了有一个 Leader 跟两个 Follower 的压力情况,负载就得到了均衡。
实际生产环境中 Region 的数量和 TDStore 的节点数量会有很多,同时针对同一个 Region 的分裂、迁移跟切主三种任务也不会这么紧凑地进行。如果没有特殊处理,Region 的分裂和切主会对事务执行有一些影响,影响业务的正常进行。所以接下来我们会重点介绍 TDSQL 如何尽量优化事务跟 Region 调度和并发,做到 Region 调度不杀事务的。
TDSQL 应对敏态业务的可用性保证:Region 调度不杀事务
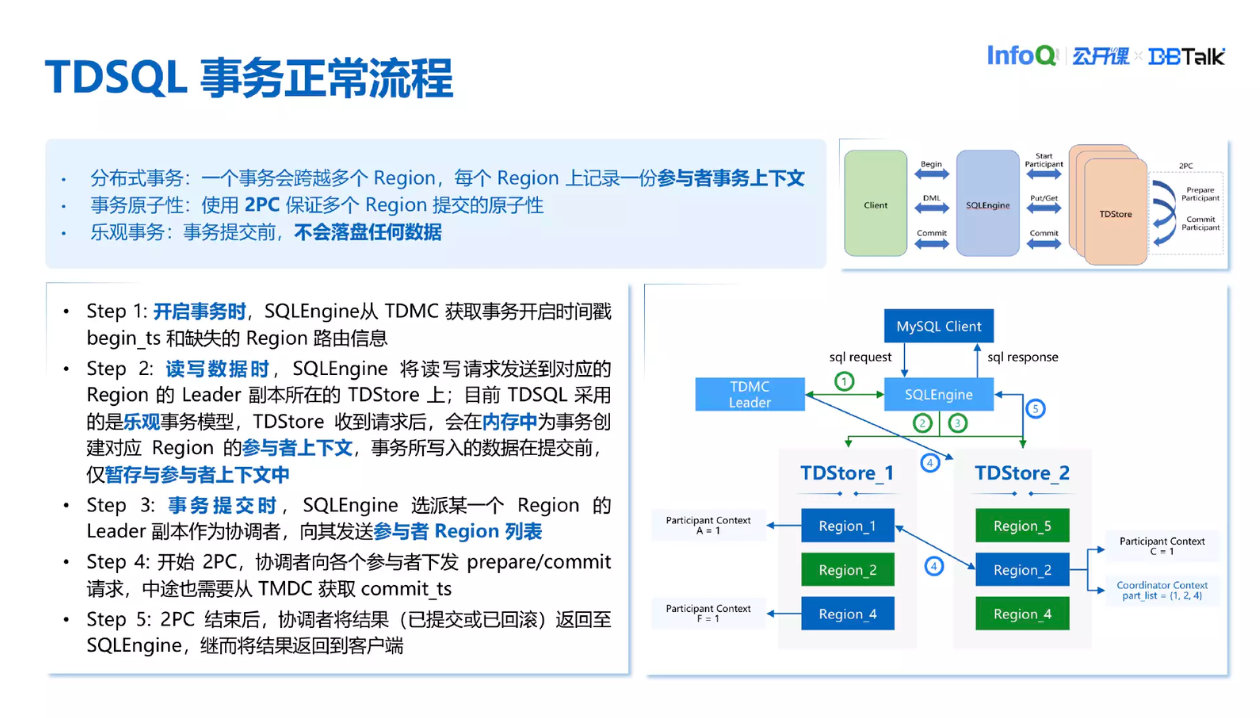
上图是一个事务完整执行的流程图。这个事务流程跟一般的 Percolator 的对比如下:
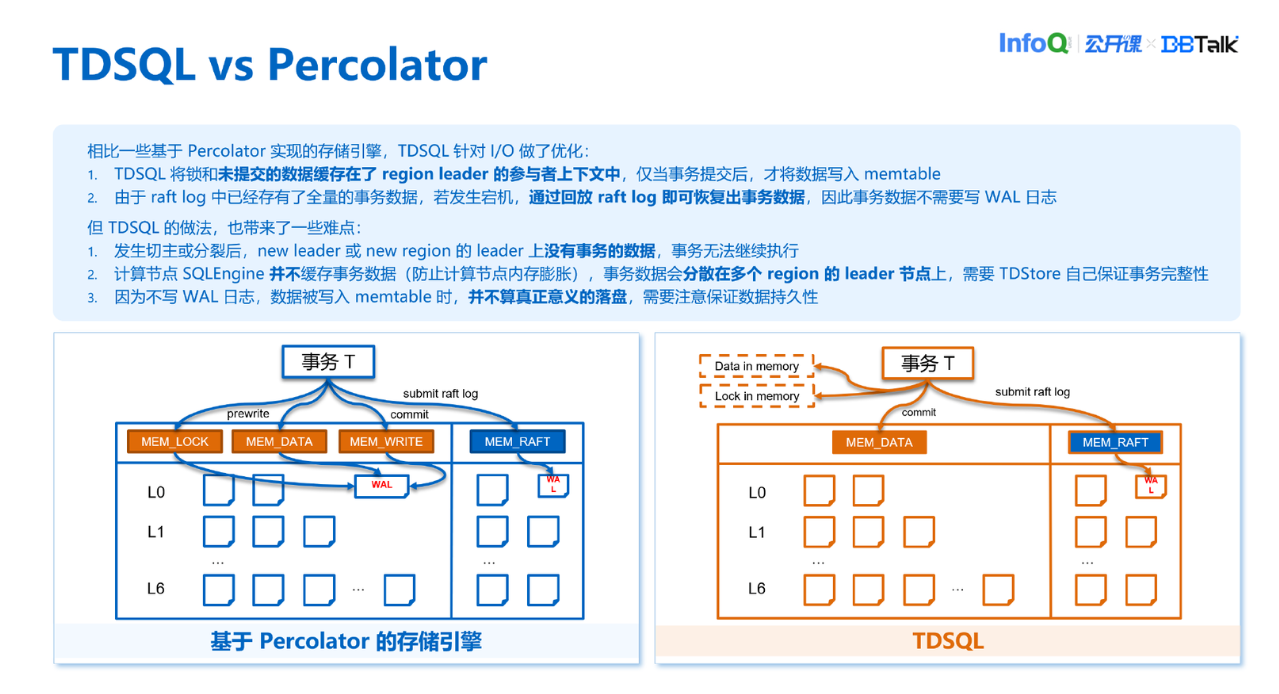
这里介绍为什么 Region 调度会杀事务。因为事务数据存在内存中,切主时可能 New Leader 节点上并没有这个事务的信息,接下来 SQLEngine 想继续访问事务所写入的数据就会发现,New Region 上面并没有事务的上下文信息,这时候就会报错事务不存在,事务就会被回滚掉。分裂也是类似,分裂之后 SQLEngine 会访问 NewRegion 上的数据,因为 New Region 上也没有上下文信息,这时候也会报错,事务不存在,导致数据回滚。也就是说切主和分裂会影响到事务,导致业务中断。我们的目的是尽量让事务的生命周期跨越分裂和切主,尽量让业务感知不到中断。
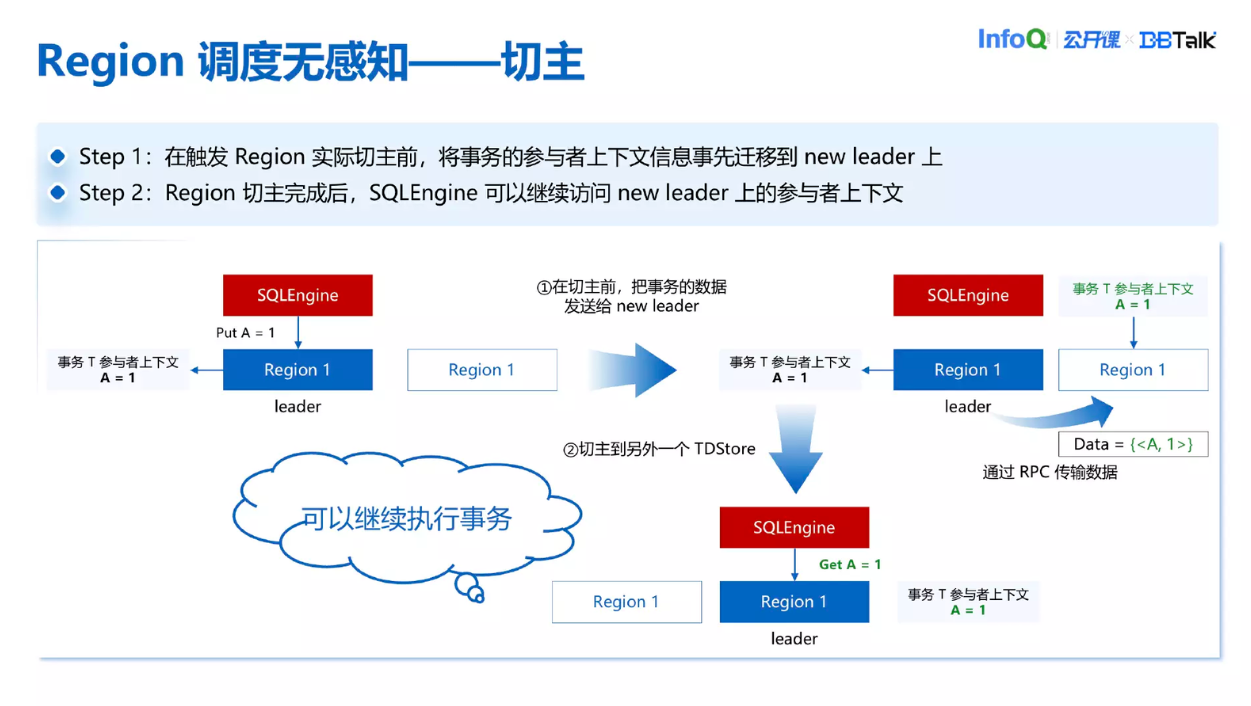
具体来看,切主之前把事务的数据发送给 New Leader,并在上面也创建一个数据上下文出来。之后当 SQLEngine 想去访问 New Leader 的时候会发现上面已经有一个参与者的上下文,这样 SQLEngine 可以继续访问数据,整个切主流程对于业务来说是没有感知的。
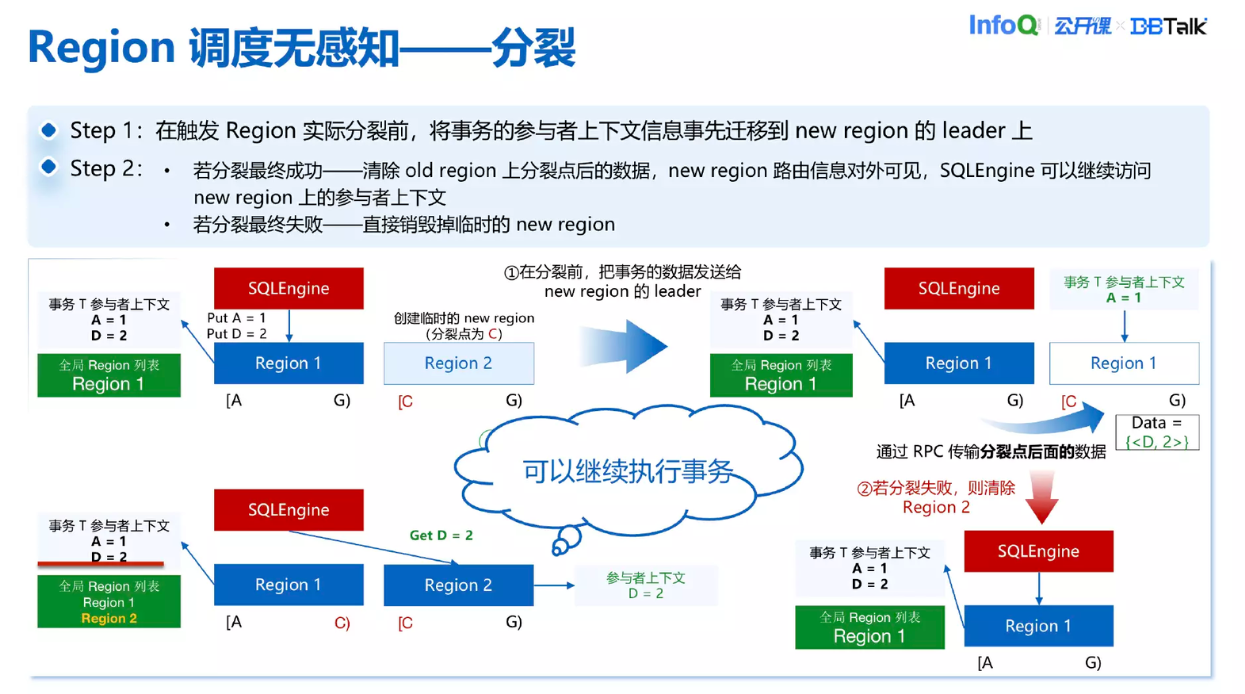
分裂也是类似,分裂之前会把分裂点之后的这一部分数据发送给 New Region,然后在 New Region 上创建一个参与者上下文出来。现在 Old Region、Region1 和 Region2 都有事务的上下文存在。如果后面分裂成功,就直接把 Old Region 上后面的数据直接删掉,这样 Region1 上面的数据上下文只有分裂前的数据,New Region 上只有分裂后的数据,就做到了数据拆分到两个 Region 上面,TDStore 继续向 New Region 下发读写请求也是可以的。
分裂失败了也没有关系,只需要把刚刚临时创建的 New Region 删掉,存储情况又回到了分裂之前。所以无论分裂是否成功数据都可以继续推进,就做到了 Region 分裂跟切主对业务没有感知。
TDSQL 应对敏态业务的数据正确性保证(1):Region 分裂对事务完整性的保证
刚刚说了可用性,接下来讲讲对于这种 Region 分裂对于事务完整性是如何去保证的。
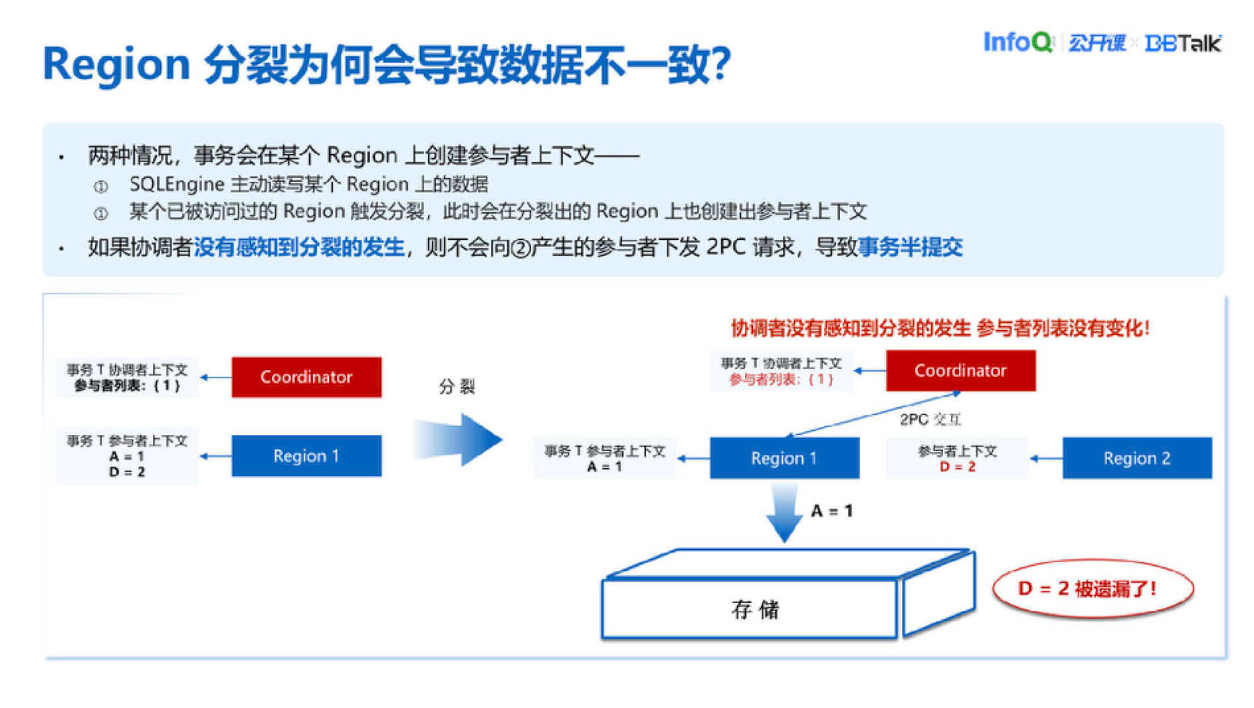
首先举个例子看看为什么 Region 分裂会导致数据不一致。因为一般情况下在 Region 上创建一个参与者只有两种情况,一种是 SQLEngine 主动访问了 Region 上的数据,这样 SQLEngine 会在 Region 上创建一个事务的参与者上下文。这种情况下 SQLEngine 知道 Region 上面是有参与者在的。但如果触发了分裂,为了分裂不杀事务我们会把事务一部分数据传送到 SQLEngine 上,这种情况它也会创建个参与者上下文。于是有可能 SQLEngine 或者协调者都感知不到分裂的发生,所以它并不知道有这么一个分裂出来的新 Region 也持有一部分事务的数据。
这里举个例子,用户 A 想向用户 D 转账 10 块钱,可能分裂之前 Region1 其实是存储了两部分数据,分别是 A 少了 10 块钱跟 D 多了 10 块钱。但是当分裂发生之后 A 少了 10 块钱是属于 Region1 的,而 D 多了 10 块钱是属于 Region2 的,这两部分数据是分摊到了两个 Region 上面。如果说协调者没有感知到这次分裂的发生,就会只向 Region1 下发 2PC 请求,最后提交的时候只有 Region1A 少了 10 块钱的数据,而 D 多了 10 块钱的数据并没有被落盘。因此最终呈现的效果是 A 的余额变成了 90 块钱,D 的余额并没有变,这样算下来 A 跟 D 的金额总数是 190,少了 10 块钱,这样就导致了数据的不一致。
为了解决这种不一致我们提出了一个方法,当分裂发生的时候我们会在 Old Region 参与者上下文信息中记录一下分裂出来的 New Region 是什么,比如说这里面 New Region 是 Region2,我们就会在 Region1 参与者上下文中去记分裂出来的 Region 是 Region2。接下来协调者向 Region1 下发请求的时候会带有当前协调者持有的参与者列表,也就是只有 Region1。然后 Region1 收到之后会比对一下,看分裂出来的 Region2 在不在列表当中,如果发现不在的话,就会返回给协调者一个 Region2 这样一个消息。协调者收到之后就会感知到 Region2 的存在,并且把 Region2 也放到了参与者列表中,之后协调者会重新下发 Prepare 请求。这次下发时因为已经感知到了 Region2 的存在,所以它会给 Region1 和 Region2 都下发 2PC 的请求。当 Region1 收到 Prepare 请求之后会发现 New Region2 现在确实是在参与者列表中的,这时候就会返回 Prepare OK 给协调者。接下来协调者就可以继续推进 2PC,当 2PC 推进到 Commit 阶段的时候就会让 Region1 跟 Region2 的数据都落盘。最终效果是用户 A 的余额变成了 90,用户 D 的数据变成了 110。这样就实现了 A 到 D 的转账,整个数据也是完整的。这样我们就保证了 Region 分裂事务的一致性。
TDSQL 应对敏态业务的数据正确性保证(2):解决 Region 分裂导致的数据掩盖问题
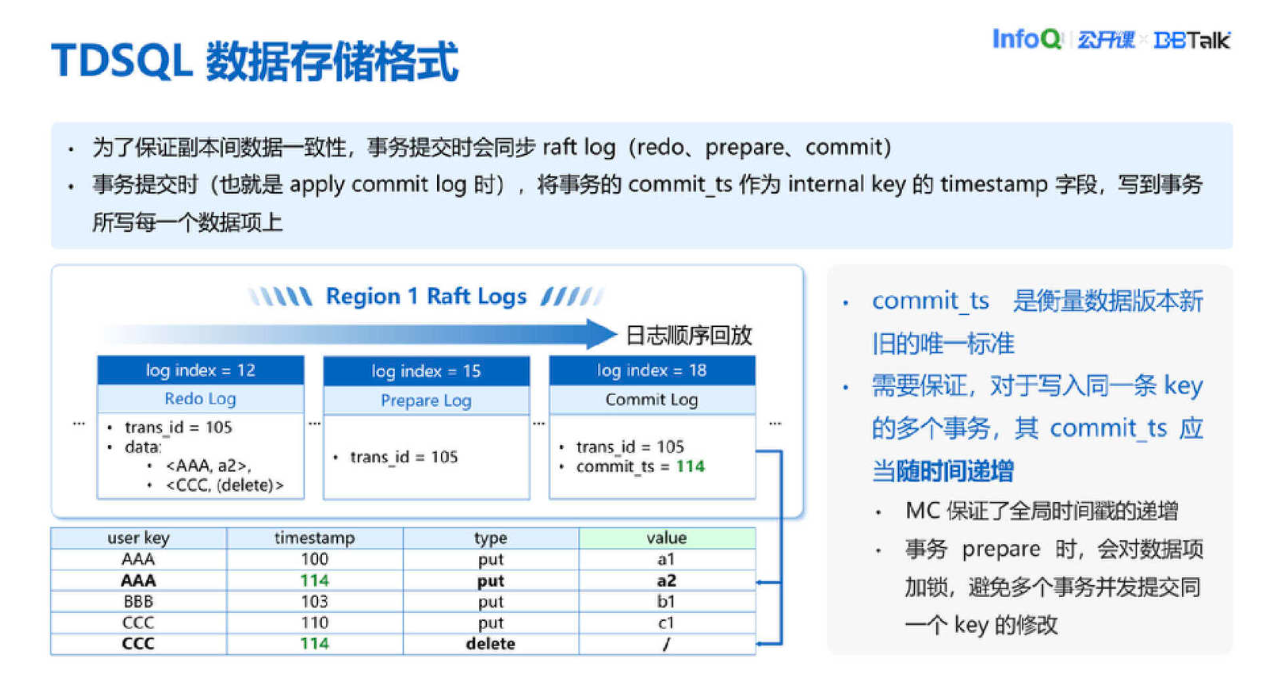
以上是 TDSQL 的数据存储格式。注意 Timestamp 这个时间需要保证,对于写入同一 Key 的多个事务 Timestamp 应该是随时间递增的。目前我们通过两个机制保证这一点。首先是 MC 提供一个全局递增的时间戳,第二是事务 Prepare 的时候会对数据项加一个锁,避免多个数据并发提交同一 Key 的修改。
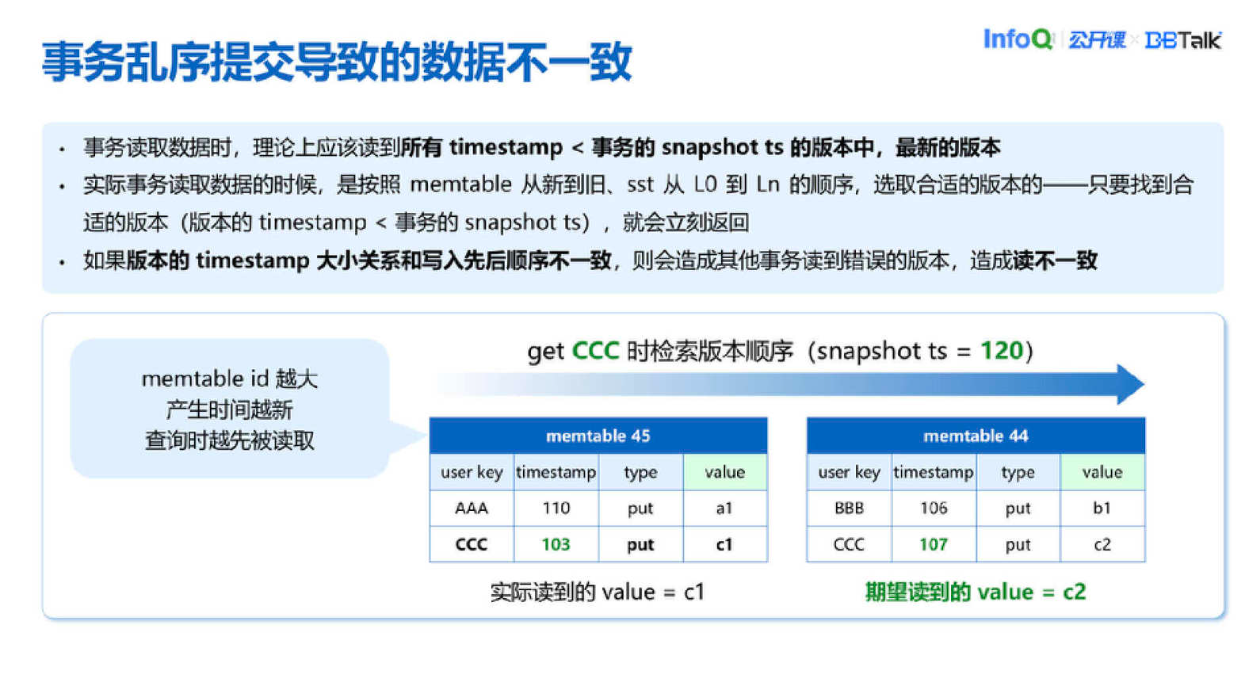
以上是 Timestamp 乱序时会发生的情况。大部分场景下这种情况不会出现,但唯独 Region 分裂的时候有可能产生这种问题。

为了解决这个问题,我们引入了 Save Snapshot 机制。它的含义是说,Snapshot 之前这些日志都已经落盘,刷到 SSD 里面了,所以 Region 启动的时候只需要从 Snapshot Index 回放日志就可以恢复出全部数据,没必要从第一条日志开始回放。通过这种机制,只需要在分裂之前以 Region Raft Log20 做一个 Save Snapshot,恢复数据的时候,Region1 只需要回放 20 之后的日志就可以,跟 Region2 就不会有任何交集。这样 Region2 的日志和 Region1 的日志可以并发回放,不会有数据掩盖的问题。
但这种方式有一个问题。因为我们需要同步等 Old Region 所有副本都以相同的 Region Split Log 做 Save Snapshot,如果 Old Region 上某一个副本落后比较严重,可能会导致要等很久,这个 Region 副本才可以回放到 20 这个位置,造成 Region Split 消耗时间不可控。所以我们后面又提出了一个新的优化方案,也就是控制 Region 之间的日志回放顺序。

比如说我们会在 Region2 上新分裂出来的 Region 信息上记,它是由 Region1 分裂得到的,并且发生分裂的时候 Region1 上面的最新的 Region Raft Log 是 20。所以数据恢复的时候首先我们会等这个 Region1,它要先回放到 20 这个位置,之后我们再去允许 Region1 后面的日志 Region2 的日志并发回放。通过这种机制我们就保证了事务对于单条 Key 的写入顺序和恢复顺序二者保持一致。这个相比之前同步等待 Save Snapshot 的方案,分裂的时候不再需要去等日志回放比较落后的 Region 副本去回放到 20 这个位置,分裂速度大大提高了。
总结
对本次分享做一个大概的总结。首先 TDSQL 是通过 Region 的分裂、迁移和切主达到负载平衡的目的。然后我们通过分裂和切主之前把数据转移到 New Leader 或者 New Region,保证数据事务不流失,让分裂和切主之后可以继续保留事务。
同时 TDSQL 也保证了数据正确性,数据完整性保证是在参与者上下文当中记录分裂出来的 New Region ID,把 New Region ID 上报给协调者,这样协调者可以感知到 New Region 的存在,把 New Region 一起提交上去。
另外对于日志并发回放造成数据掩盖的问题,我们一开始是通过在分裂时对 Old Region 做 Save Snapshot 解决的,然后通过延后 New Region 日志回放时机的方式做了优化,做到避免 Old Region 和 New Region 并发回放日志,导致数据不一致的问题。
